 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Geo-localization: Fine-grained Orientation of Street-view Images by Cross-view Matching with Satellite Imagery with Supplementary Materials
Jul 13, 2023
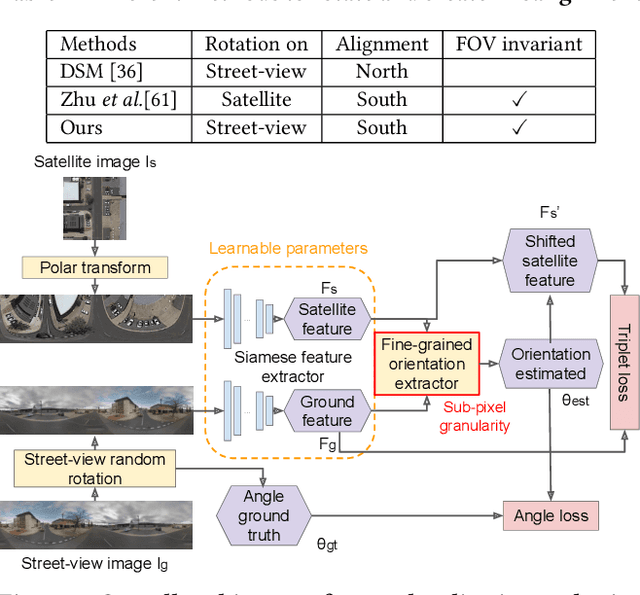

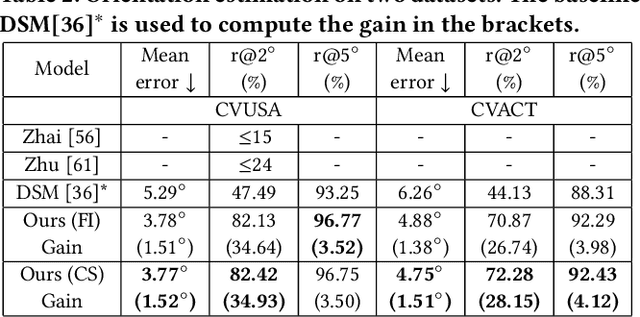
Street-view imagery provides us with novel experiences to explore different places remotely. Carefully calibrated street-view images (e.g. Google Street View) can be used for different downstream tasks, e.g. navigation, map features extraction. As personal high-quality cameras have become much more affordable and portable, an enormous amount of crowdsourced street-view images are uploaded to the internet, but commonly with missing or noisy sensor information. To prepare this hidden treasure for "ready-to-use" status, determining missing location information and camera orientation angles are two equally important tasks. Recent methods have achieved high performance on geo-localization of street-view images by cross-view matching with a pool of geo-referenced satellite imagery. However, most of the existing works focus more on geo-localization than estimating the image orientation. In this work, we re-state the importance of finding fine-grained orientation for street-view images, formally define the problem and provide a set of evaluation metrics to assess the quality of the orientation estimation. We propose two methods to improve the granularity of the orientation estimation, achieving 82.4% and 72.3% accuracy for images with estimated angle errors below 2 degrees for CVUSA and CVACT datasets, corresponding to 34.9% and 28.2% absolute improvement compared to previous works. Integrating fine-grained orientation estimation in training also improves the performance on geo-localization, giving top 1 recall 95.5%/85.5% and 86.8%/80.4% for orientation known/unknown tests on the two datasets.
* This paper has been accepted by ACM Multimedia 2022. This version contains additional supplementary materials
WaveTransformer: A Novel Architecture for Audio Captioning Based on Learning Temporal and Time-Frequency Information
Oct 21, 2020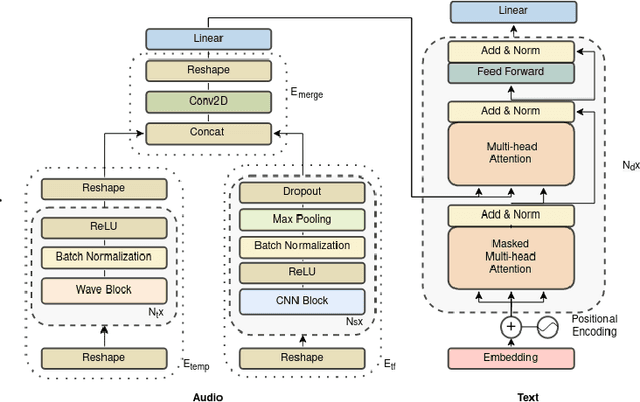

Automated audio captioning (AAC) is a novel task, where a method takes as an input an audio sample and outputs a textual description (i.e. a caption) of its contents. Most AAC methods are adapted from from image captioning of machine translation fields. In this work we present a novel AAC novel method, explicitly focused on the exploitation of the temporal and time-frequency patterns in audio. We employ three learnable processes for audio encoding, two for extracting the local and temporal information, and one to merge the output of the previous two processes. To generate the caption, we employ the widely used Transformer decoder. We assess our method utilizing the freely available splits of Clotho dataset. Our results increase previously reported highest SPIDEr to 17.3, from 16.2.
PP-LinkNet: Improving Semantic Segmentation of High Resolution Satellite Imagery with Multi-stage Training
Oct 14, 2020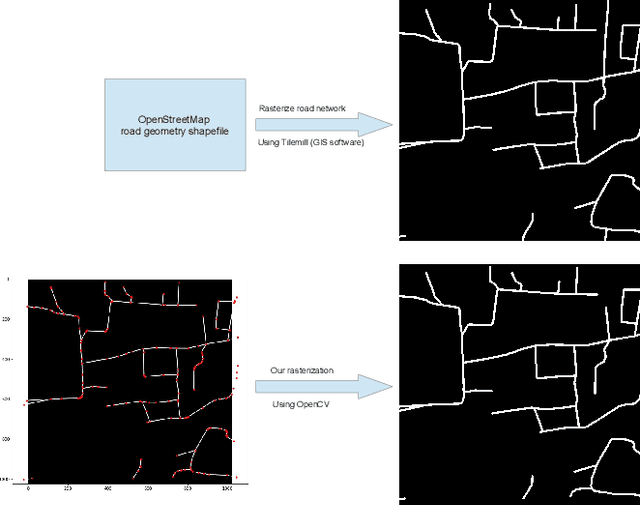
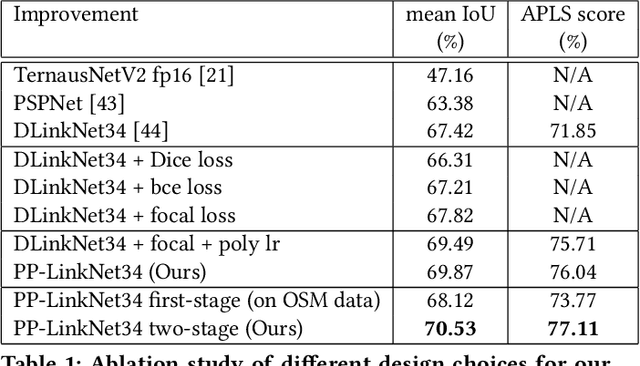

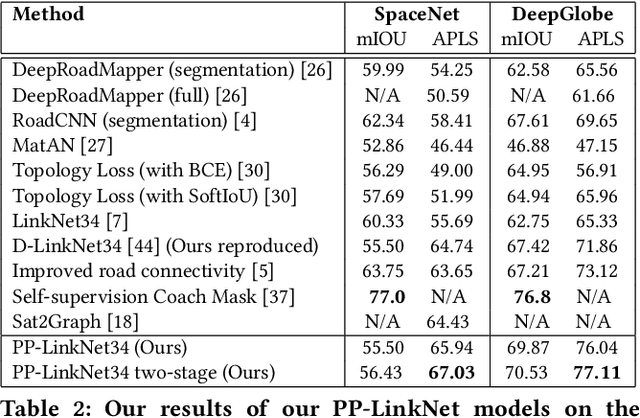
Road network and building footprint extraction is essential for many applications such as updating maps, traffic regulations, city planning, ride-hailing, disaster response \textit{etc}. Mapping road networks is currently both expensive and labor-intensive. Recently, improvements in image segmentation through the application of deep neural networks has shown promising results in extracting road segments from large scale, high resolution satellite imagery. However, significant challenges remain due to lack of enough labeled training data needed to build models for industry grade applications. In this paper, we propose a two-stage transfer learning technique to improve robustness of semantic segmentation for satellite images that leverages noisy pseudo ground truth masks obtained automatically (without human labor) from crowd-sourced OpenStreetMap (OSM) data. We further propose Pyramid Pooling-LinkNet (PP-LinkNet), an improved deep neural network for segmentation that uses focal loss, poly learning rate, and context module. We demonstrate the strengths of our approach through evaluations done on three popular datasets over two tasks, namely, road extraction and building foot-print detection. Specifically, we obtain 78.19\% meanIoU on SpaceNet building footprint dataset, 67.03\% and 77.11\% on the road topology metric on SpaceNet and DeepGlobe road extraction dataset, respectively.
Two-stream Flow-guided Convolutional Attention Networks for Action Recognition
Aug 30, 2017
This paper proposes a two-stream flow-guided convolutional attention networks for action recognition in videos. The central idea is that optical flows, when properly compensated for the camera motion, can be used to guide attention to the human foreground. We thus develop cross-link layers from the temporal network (trained on flows) to the spatial network (trained on RGB frames). These cross-link layers guide the spatial-stream to pay more attention to the human foreground areas and be less affected by background clutter. We obtain promising performances with our approach on the UCF101, HMDB51 and Hollywood2 datasets.