 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZooming for Efficient Model-Free Reinforcement Learning in Metric Spaces
Mar 09, 2020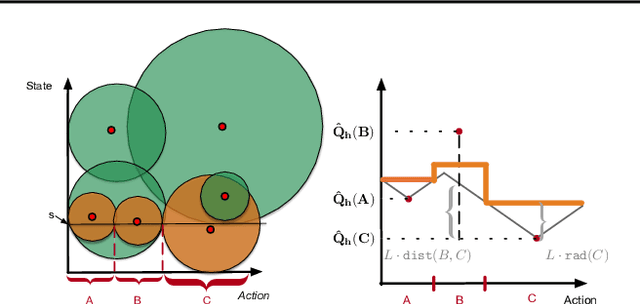

Despite the wealth of research into provably efficient reinforcement learning algorithms, most works focus on tabular representation and thus struggle to handle exponentially or infinitely large state-action spaces. In this paper, we consider episodic reinforcement learning with a continuous state-action space which is assumed to be equipped with a natural metric that characterizes the proximity between different states and actions. We propose ZoomRL, an online algorithm that leverages ideas from continuous bandits to learn an adaptive discretization of the joint space by zooming in more promising and frequently visited regions while carefully balancing the exploitation-exploration trade-off. We show that ZoomRL achieves a worst-case regret $\tilde{O}(H^{\frac{5}{2}} K^{\frac{d+1}{d+2}})$ where $H$ is the planning horizon, $K$ is the number of episodes and $d$ is the covering dimension of the space with respect to the metric. Moreover, our algorithm enjoys improved metric-dependent guarantees that reflect the geometry of the underlying space. Finally, we show that our algorithm is robust to small misspecification errors.
A Geometric Perspective on Optimal Representations for Reinforcement Learning
Jan 31, 2019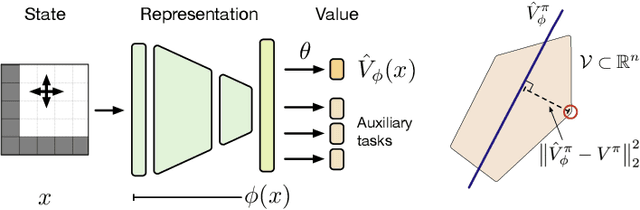
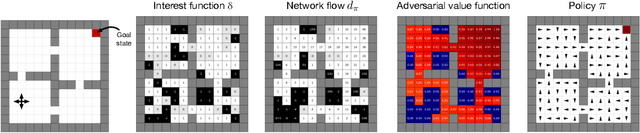
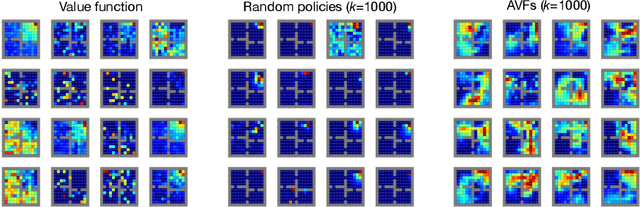
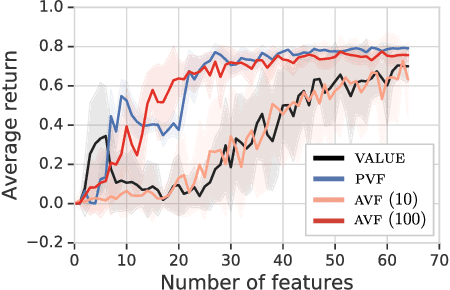
This paper proposes a new approach to representation learning based on geometric properties of the space of value functions. We study a two-part approximation of the value function: a nonlinear map from states to vectors, or representation, followed by a linear map from vectors to values. Our formulation considers adapting the representation to minimize the (linear) approximation of the value function of all stationary policies for a given environment. We show that this optimization reduces to making accurate predictions regarding a special class of value functions which we call adversarial value functions (AVFs). We argue that these AVFs make excellent auxiliary tasks, and use them to construct a loss which can be efficiently minimized to find a near-optimal representation for reinforcement learning. We highlight characteristics of the method in a series of experiments on the four-room domain.
PixelVAE: A Latent Variable Model for Natural Images
Nov 15, 2016
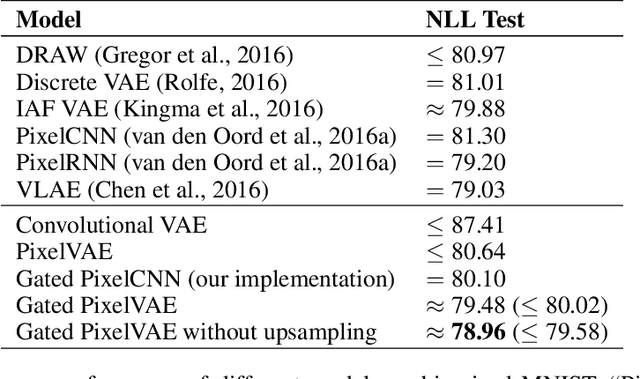
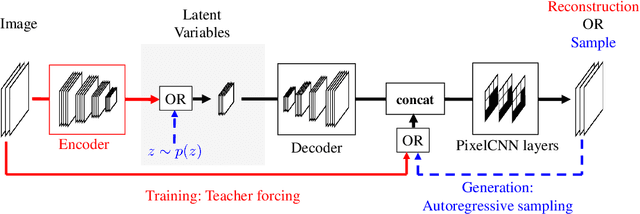

Natural image modeling is a landmark challenge of unsupervised learning. Variational Autoencoders (VAEs) learn a useful latent representation and model global structure well but have difficulty capturing small details. PixelCNN models details very well, but lacks a latent code and is difficult to scale for capturing large structures. We present PixelVAE, a VAE model with an autoregressive decoder based on PixelCNN. Our model requires very few expensive autoregressive layers compared to PixelCNN and learns latent codes that are more compressed than a standard VAE while still capturing most non-trivial structure. Finally, we extend our model to a hierarchy of latent variables at different scales. Our model achieves state-of-the-art performance on binarized MNIST, competitive performance on 64x64 ImageNet, and high-quality samples on the LSUN bedrooms dataset.