 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Informed Model Complexity Metric for Optimizing Symbolic Regression Models
Jan 29, 2025



Choosing models from a well-fitted evolved population that generalizes beyond training data is difficult. We introduce a pragmatic method to estimate model complexity using Hessian rank for post-processing selection. Complexity is approximated by averaging the model output Hessian rank across a few points (N=3), offering efficient and accurate rank estimates. This method aligns model selection with input data complexity, calculated using intrinsic dimensionality (ID) estimators. Using the StackGP system, we develop symbolic regression models for the Penn Machine Learning Benchmark and employ twelve scikit-dimension library methods to estimate ID, aligning model expressiveness with dataset ID. Our data-informed complexity metric finds the ideal complexity window, balancing model expressiveness and accuracy, enhancing generalizability without bias common in methods reliant on user-defined parameters, such as parsimony pressure in weight selection.
Deep Rib Fracture Instance Segmentation and Classification from CT on the RibFrac Challenge
Feb 14, 2024Rib fractures are a common and potentially severe injury that can be challenging and labor-intensive to detect in CT scans. While there have been efforts to address this field, the lack of large-scale annotated datasets and evaluation benchmarks has hindered the development and validation of deep learning algorithms. To address this issue, the RibFrac Challenge was introduced, providing a benchmark dataset of over 5,000 rib fractures from 660 CT scans, with voxel-level instance mask annotations and diagnosis labels for four clinical categories (buckle, nondisplaced, displaced, or segmental). The challenge includes two tracks: a detection (instance segmentation) track evaluated by an FROC-style metric and a classification track evaluated by an F1-style metric. During the MICCAI 2020 challenge period, 243 results were evaluated, and seven teams were invited to participate in the challenge summary. The analysis revealed that several top rib fracture detection solutions achieved performance comparable or even better than human experts. Nevertheless, the current rib fracture classification solutions are hardly clinically applicable, which can be an interesting area in the future. As an active benchmark and research resource, the data and online evaluation of the RibFrac Challenge are available at the challenge website. As an independent contribution, we have also extended our previous internal baseline by incorporating recent advancements in large-scale pretrained networks and point-based rib segmentation techniques. The resulting FracNet+ demonstrates competitive performance in rib fracture detection, which lays a foundation for further research and development in AI-assisted rib fracture detection and diagnosis.
Blind Analysis of CT Image Noise Using Residual Denoised Images
May 24, 2016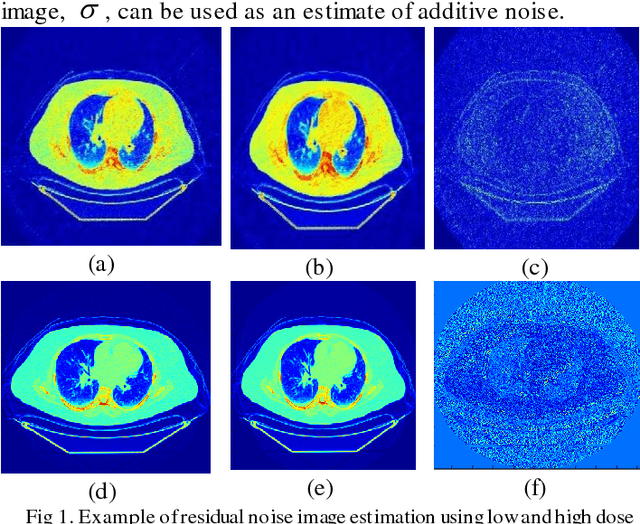
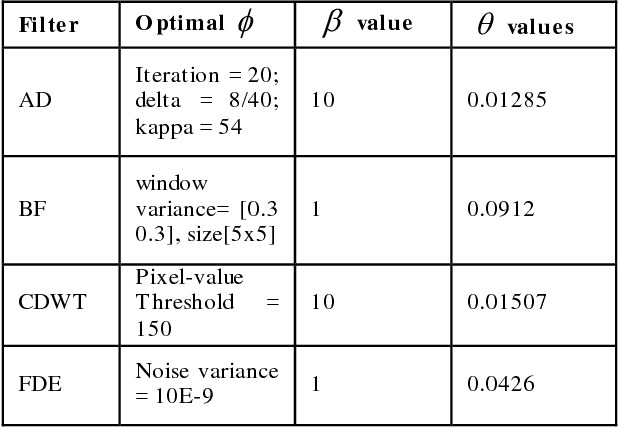
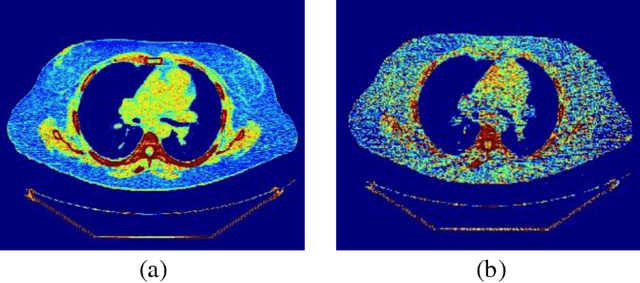
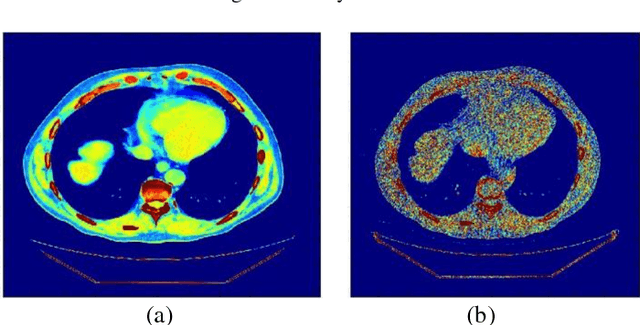
CT protocol design and quality control would benefit from automated tools to estimate the quality of generated CT images. These tools could be used to identify erroneous CT acquisitions or refine protocols to achieve certain signal to noise characteristics. This paper investigates blind estimation methods to determine global signal strength and noise levels in chest CT images. Methods: We propose novel performance metrics corresponding to the accuracy of noise and signal estimation. We implement and evaluate the noise estimation performance of six spatial- and frequency- based methods, derived from conventional image filtering algorithms. Algorithms were tested on patient data sets from whole-body repeat CT acquisitions performed with a higher and lower dose technique over the same scan region. Results: The proposed performance metrics can evaluate the relative tradeoff of filter parameters and noise estimation performance. The proposed automated methods tend to underestimate CT image noise at low-flux levels. Initial application of methodology suggests that anisotropic diffusion and Wavelet-transform based filters provide optimal estimates of noise. Furthermore, methodology does not provide accurate estimates of absolute noise levels, but can provide estimates of relative change and/or trends in noise levels.