 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoRL: Reinforcement Learning via Rollout Echoing
May 29, 2026Reinforcement Learning with Verifiable Rewards is an effective route for post-training to strengthen the reasoning capability of large language models. However, as training proceeds, the learning signal can collapse thus makes the training gain become marginal and ineffective. Specifically, a growing fraction of prompts' rollouts become advantage-degenerated: all the self-generated rollouts show verified-success, making the standard deviation over their rewards be zero; accordingly each rollout's advantage becomes degenerated (zero) as well. Given such rollouts' advantages, the policy-gradient for model optimization eventually vanishes, capping the training performance. We argue that some of these rollouts still contain valuable learning signals but unfortunately omitted with the existing RLVR methods. In this paper, inspired through analyzing the entropy pattern behind golden trajectories produced by external expert models, we propose EchoRL for better exploiting the advantage-degenerated rollouts to further improve the training performance. EchoRL is a lightweight module that first identifies an EchoClip from verified-success rollouts based on their step-level entropy values, and then feeds this clip back as an auxiliary supervision signal in the RL objective. Extensive experiments across 10 benchmarks, 5 LLM backbones, and 4 popular RLVR post-training methods demonstrate that EchoRL consistently improves RLVR post-training with minimal overhead.
SiameseNorm: Breaking the Barrier to Reconciling Pre/Post-Norm
Feb 08, 2026Modern Transformers predominantly adopt the Pre-Norm paradigm for its optimization stability, foregoing the superior potential of the unstable Post-Norm architecture. Prior attempts to combine their strengths typically lead to a stability-performance trade-off. We attribute this phenomenon to a structural incompatibility within a single-stream design: Any application of the Post-Norm operation inevitably obstructs the clean identity gradient preserved by Pre-Norm. To fundamentally reconcile these paradigms, we propose SiameseNorm, a two-stream architecture that couples Pre-Norm-like and Post-Norm-like streams with shared parameters. This design decouples the optimization dynamics of the two streams, retaining the distinct characteristics of both Pre-Norm and Post-Norm by enabling all residual blocks to receive combined gradients inherited from both paradigms, where one stream secures stability while the other enhances expressivity. Extensive pre-training experiments on 1.3B-parameter models demonstrate that SiameseNorm exhibits exceptional optimization robustness and consistently outperforms strong baselines. Code is available at https://github.com/Qwen-Applications/SiameseNorm.
The Machine Learning for Combinatorial Optimization Competition (ML4CO): Results and Insights
Mar 17, 2022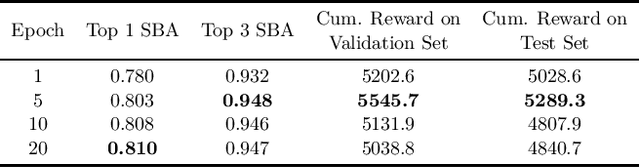

Combinatorial optimization is a well-established area in operations research and computer science. Until recently, its methods have focused on solving problem instances in isolation, ignoring that they often stem from related data distributions in practice. However, recent years have seen a surge of interest in using machine learning as a new approach for solving combinatorial problems, either directly as solvers or by enhancing exact solvers. Based on this context, the ML4CO aims at improving state-of-the-art combinatorial optimization solvers by replacing key heuristic components. The competition featured three challenging tasks: finding the best feasible solution, producing the tightest optimality certificate, and giving an appropriate solver configuration. Three realistic datasets were considered: balanced item placement, workload apportionment, and maritime inventory routing. This last dataset was kept anonymous for the contestants.
PooL: Pheromone-inspired Communication Framework forLarge Scale Multi-Agent Reinforcement Learning
Feb 20, 2022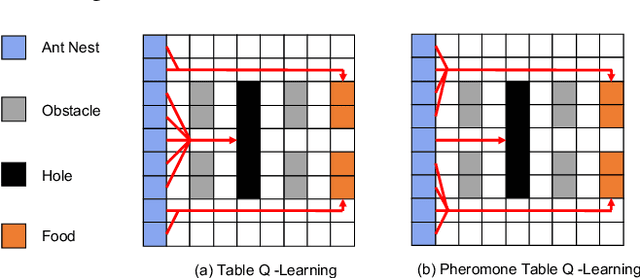

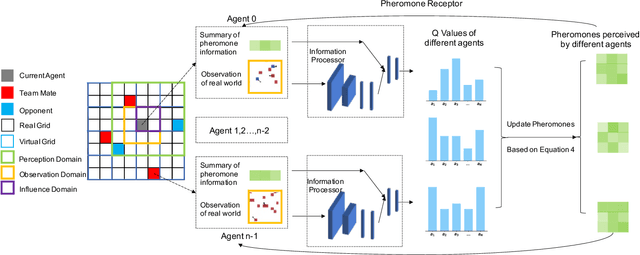
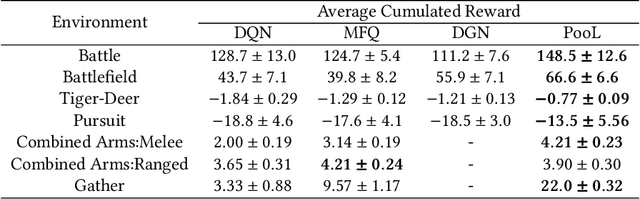
Being difficult to scale poses great problems in multi-agent coordination. Multi-agent Reinforcement Learning (MARL) algorithms applied in small-scale multi-agent systems are hard to extend to large-scale ones because the latter is far more dynamic and the number of interactions increases exponentially with the growing number of agents. Some swarm intelligence algorithms simulate the release and utilization mechanism of pheromones to control large-scale agent coordination. Inspired by such algorithms, \textbf{PooL}, an \textbf{p}her\textbf{o}m\textbf{o}ne-based indirect communication framework applied to large scale multi-agent reinforcement \textbf{l}earning is proposed in order to solve the large-scale multi-agent coordination problem. Pheromones released by agents of PooL are defined as outputs of most reinforcement learning algorithms, which reflect agents' views of the current environment. The pheromone update mechanism can efficiently organize the information of all agents and simplify the complex interactions among agents into low-dimensional representations. Pheromones perceived by agents can be regarded as a summary of the views of nearby agents which can better reflect the real situation of the environment. Q-Learning is taken as our base model to implement PooL and PooL is evaluated in various large-scale cooperative environments. Experiments show agents can capture effective information through PooL and achieve higher rewards than other state-of-arts methods with lower communication costs.
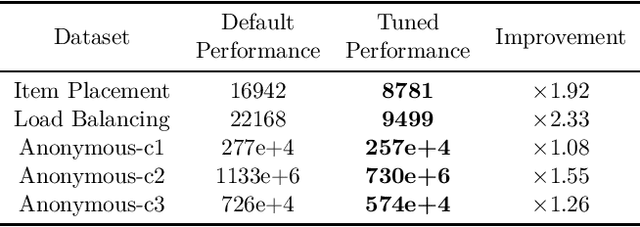
ML4CO-KIDA: Knowledge Inheritance in Dataset Aggregation
Feb 03, 2022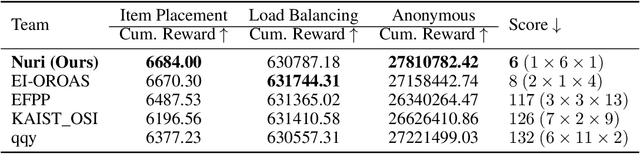
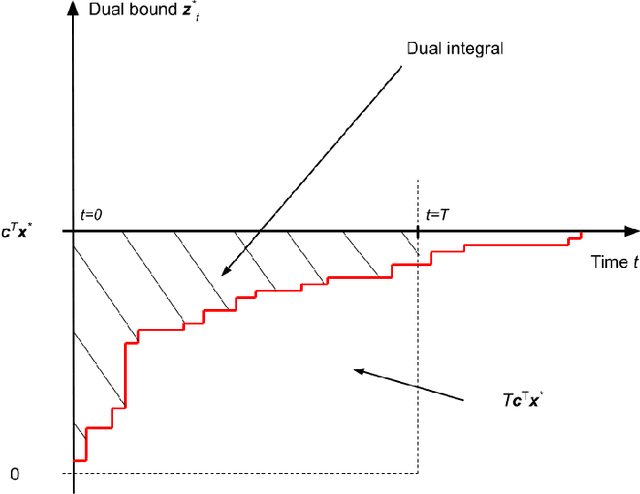
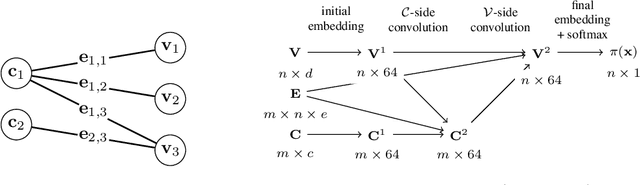
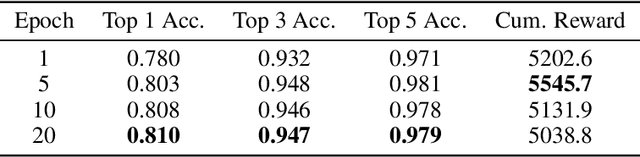
The Machine Learning for Combinatorial Optimization (ML4CO) NeurIPS 2021 competition aims to improve state-of-the-art combinatorial optimization solvers by replacing key heuristic components with machine learning models. On the dual task, we design models to make branching decisions to promote the dual bound increase faster. We propose a knowledge inheritance method to generalize knowledge of different models from the dataset aggregation process, named KIDA. Our improvement overcomes some defects of the baseline graph-neural-networks-based methods. Further, we won the $1$\textsuperscript{st} Place on the dual task. We hope this report can provide useful experience for developers and researchers. The code is available at https://github.com/megvii-research/NeurIPS2021-ML4CO-KIDA.