 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital Player: Evaluating Large Language Models based Human-like Agent in Games
Feb 28, 2025With the rapid advancement of Large Language Models (LLMs), LLM-based autonomous agents have shown the potential to function as digital employees, such as digital analysts, teachers, and programmers. In this paper, we develop an application-level testbed based on the open-source strategy game "Unciv", which has millions of active players, to enable researchers to build a "data flywheel" for studying human-like agents in the "digital players" task. This "Civilization"-like game features expansive decision-making spaces along with rich linguistic interactions such as diplomatic negotiations and acts of deception, posing significant challenges for LLM-based agents in terms of numerical reasoning and long-term planning. Another challenge for "digital players" is to generate human-like responses for social interaction, collaboration, and negotiation with human players. The open-source project can be found at https:/github.com/fuxiAIlab/CivAgent.
Battery and Hydrogen Energy Storage Control in a Smart Energy Network with Flexible Energy Demand using Deep Reinforcement Learning
Aug 26, 2022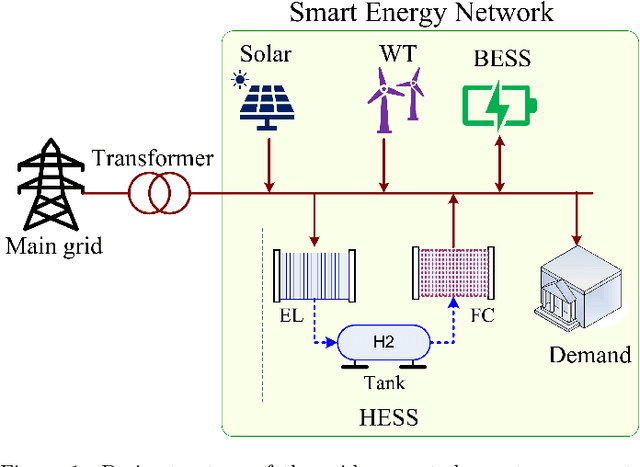

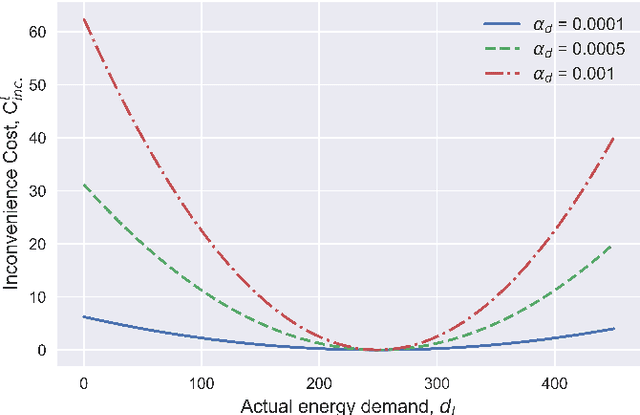
Smart energy networks provide for an effective means to accommodate high penetrations of variable renewable energy sources like solar and wind, which are key for deep decarbonisation of energy production. However, given the variability of the renewables as well as the energy demand, it is imperative to develop effective control and energy storage schemes to manage the variable energy generation and achieve desired system economics and environmental goals. In this paper, we introduce a hybrid energy storage system composed of battery and hydrogen energy storage to handle the uncertainties related to electricity prices, renewable energy production and consumption. We aim to improve renewable energy utilisation and minimise energy costs and carbon emissions while ensuring energy reliability and stability within the network. To achieve this, we propose a multi-agent deep deterministic policy gradient approach, which is a deep reinforcement learning-based control strategy to optimise the scheduling of the hybrid energy storage system and energy demand in real-time. The proposed approach is model-free and does not require explicit knowledge and rigorous mathematical models of the smart energy network environment. Simulation results based on real-world data show that: (i) integration and optimised operation of the hybrid energy storage system and energy demand reduces carbon emissions by 78.69%, improves cost savings by 23.5% and renewable energy utilisation by over 13.2% compared to other baseline models and (ii) the proposed algorithm outperforms the state-of-the-art self-learning algorithms like deep-Q network.
Renewable energy integration and microgrid energy trading using multi-agent deep reinforcement learning
Dec 05, 2021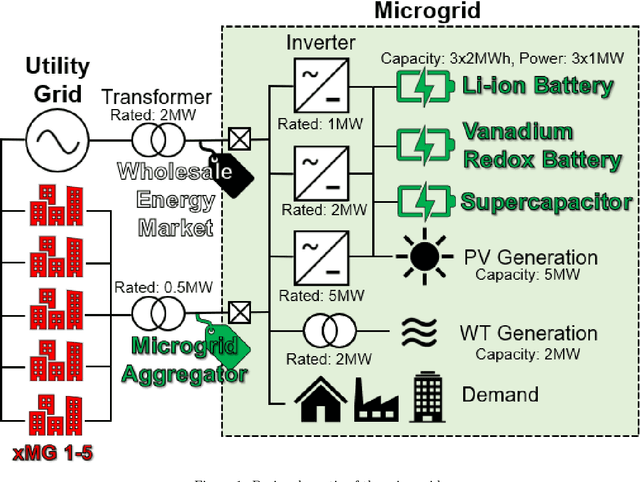

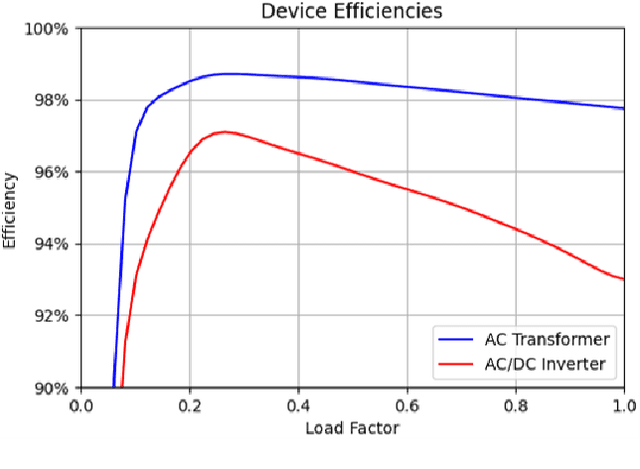
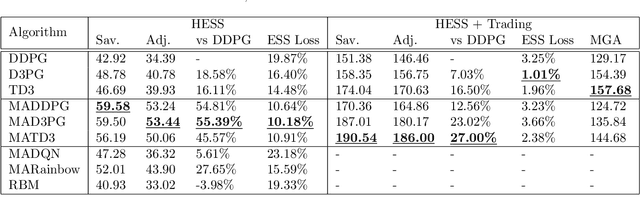
In this paper, multi-agent reinforcement learning is used to control a hybrid energy storage system working collaboratively to reduce the energy costs of a microgrid through maximising the value of renewable energy and trading. The agents must learn to control three different types of energy storage system suited for short, medium, and long-term storage under fluctuating demand, dynamic wholesale energy prices, and unpredictable renewable energy generation. Two case studies are considered: the first looking at how the energy storage systems can better integrate renewable energy generation under dynamic pricing, and the second with how those same agents can be used alongside an aggregator agent to sell energy to self-interested external microgrids looking to reduce their own energy bills. This work found that the centralised learning with decentralised execution of the multi-agent deep deterministic policy gradient and its state-of-the-art variants allowed the multi-agent methods to perform significantly better than the control from a single global agent. It was also found that using separate reward functions in the multi-agent approach performed much better than using a single control agent. Being able to trade with the other microgrids, rather than just selling back to the utility grid, also was found to greatly increase the grid's savings.
Data-driven battery operation for energy arbitrage using rainbow deep reinforcement learning
Jun 10, 2021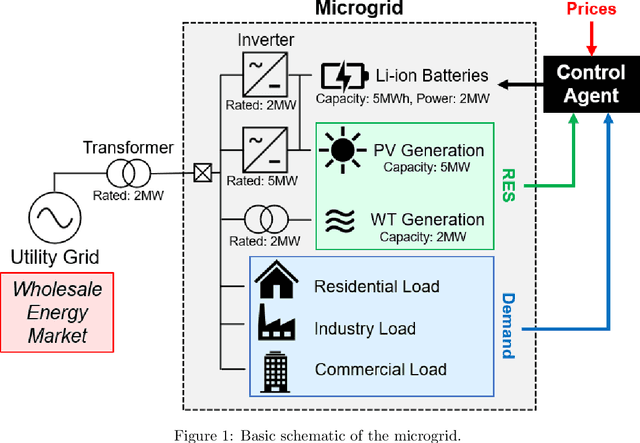
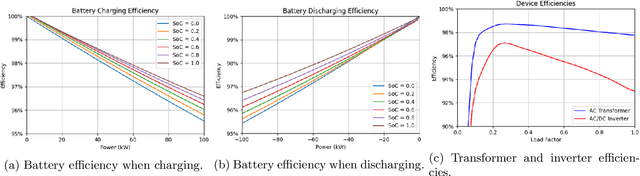
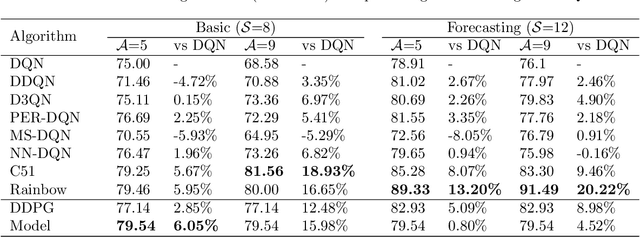
As the world seeks to become more sustainable, intelligent solutions are needed to increase the penetration of renewable energy. In this paper, the model-free deep reinforcement learning algorithm Rainbow Deep Q-Networks is used to control a battery in a small microgrid to perform energy arbitrage and more efficiently utilise solar and wind energy sources. The grid operates with its own demand and renewable generation based on a dataset collected at Keele University, as well as using dynamic energy pricing from a real wholesale energy market. Four scenarios are tested including using demand and price forecasting produced with local weather data. The algorithm and its subcomponents are evaluated against two continuous control benchmarks with Rainbow able to outperform all other method. This research shows the importance of using the distributional approach for reinforcement learning when working with complex environments and reward functions, as well as how it can be used to visualise and contextualise the agent's behaviour for real-world applications.
Federated Learning for Short-term Residential Energy Demand Forecasting
May 27, 2021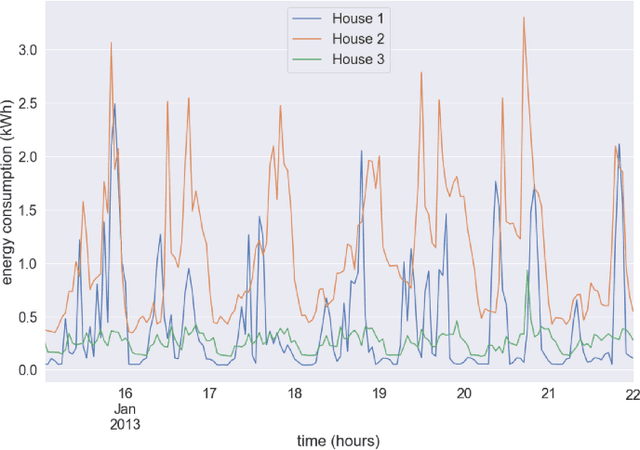
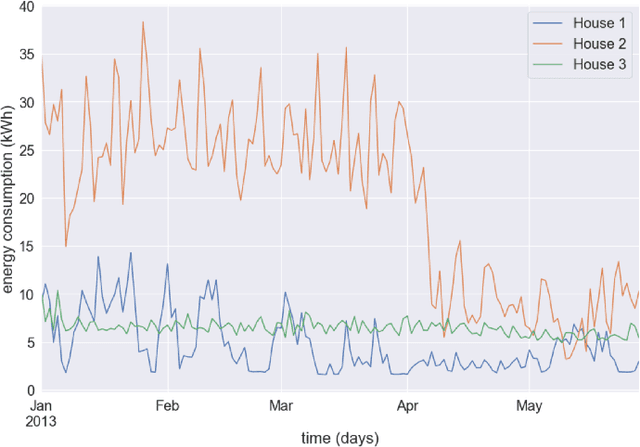
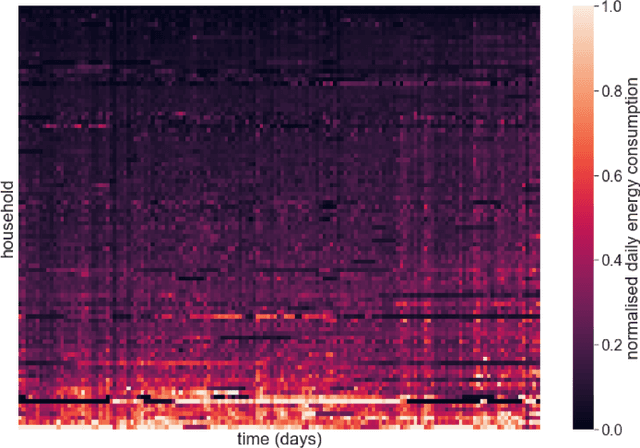
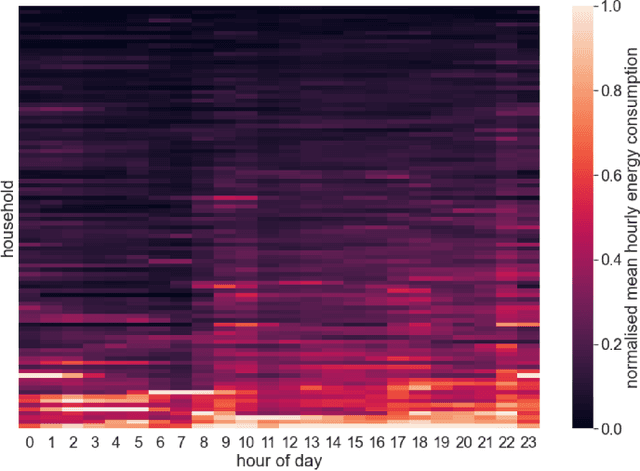
Energy demand forecasting is an essential task performed within the energy industry to help balance supply with demand and maintain a stable load on the electricity grid. As supply transitions towards less reliable renewable energy generation, smart meters will prove a vital component to aid these forecasting tasks. However, smart meter take-up is low among privacy-conscious consumers that fear intrusion upon their fine-grained consumption data. In this work we propose and explore a federated learning (FL) based approach for training forecasting models in a distributed, collaborative manner whilst retaining the privacy of the underlying data. We compare two approaches: FL, and a clustered variant, FL+HC against a non-private, centralised learning approach and a fully private, localised learning approach. Within these approaches, we measure model performance using RMSE and computational efficiency via the number of samples required to train models under each scenario. In addition, we suggest the FL strategies are followed by a personalisation step and show that model performance can be improved by doing so. We show that FL+HC followed by personalisation can achieve a $\sim$5% improvement in model performance with a $\sim$10x reduction in computation compared to localised learning. Finally we provide advice on private aggregation of predictions for building a private end-to-end energy demand forecasting application.
Privacy Preserving Demand Forecasting to Encourage Consumer Acceptance of Smart Energy Meters
Dec 14, 2020In this proposal paper we highlight the need for privacy preserving energy demand forecasting to allay a major concern consumers have about smart meter installations. High resolution smart meter data can expose many private aspects of a consumer's household such as occupancy, habits and individual appliance usage. Yet smart metering infrastructure has the potential to vastly reduce carbon emissions from the energy sector through improved operating efficiencies. We propose the application of a distributed machine learning setting known as federated learning for energy demand forecasting at various scales to make load prediction possible whilst retaining the privacy of consumers' raw energy consumption data.
Federated learning with hierarchical clustering of local updates to improve training on non-IID data
May 06, 2020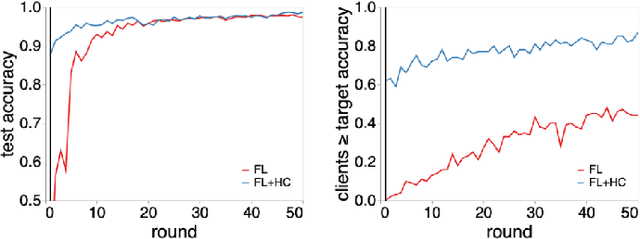
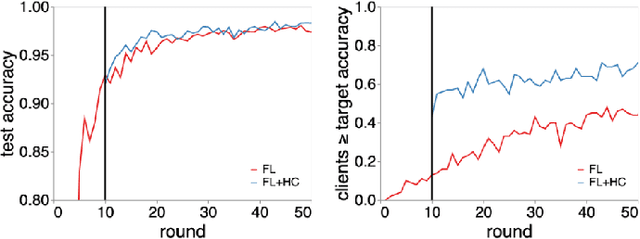
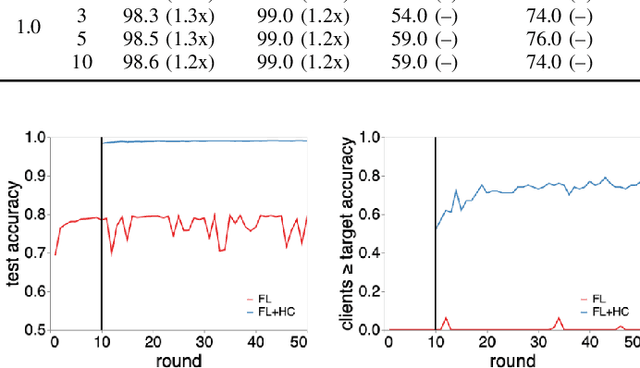
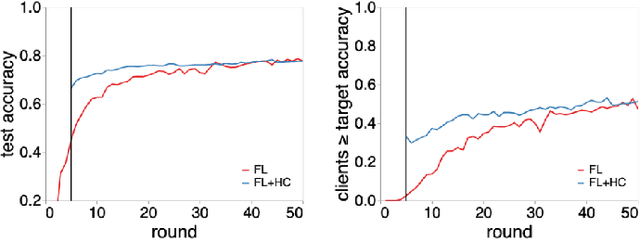
Federated learning (FL) is a well established method for performing machine learning tasks over massively distributed data. However in settings where data is distributed in a non-iid (not independent and identically distributed) fashion -- as is typical in real world situations -- the joint model produced by FL suffers in terms of test set accuracy and/or communication costs compared to training on iid data. We show that learning a single joint model is often not optimal in the presence of certain types of non-iid data. In this work we present a modification to FL by introducing a hierarchical clustering step (FL+HC) to separate clusters of clients by the similarity of their local updates to the global joint model. Once separated, the clusters are trained independently and in parallel on specialised models. We present a robust empirical analysis of the hyperparameters for FL+HC for several iid and non-iid settings. We show how FL+HC allows model training to converge in fewer communication rounds (significantly so under some non-iid settings) compared to FL without clustering. Additionally, FL+HC allows for a greater percentage of clients to reach a target accuracy compared to standard FL. Finally we make suggestions for good default hyperparameters to promote superior performing specialised models without modifying the the underlying federated learning communication protocol.
A Review of Privacy Preserving Federated Learning for Private IoT Analytics
Apr 24, 2020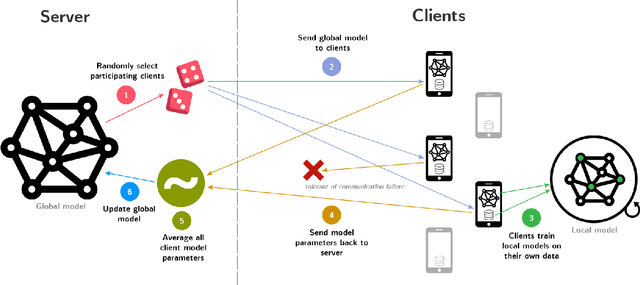
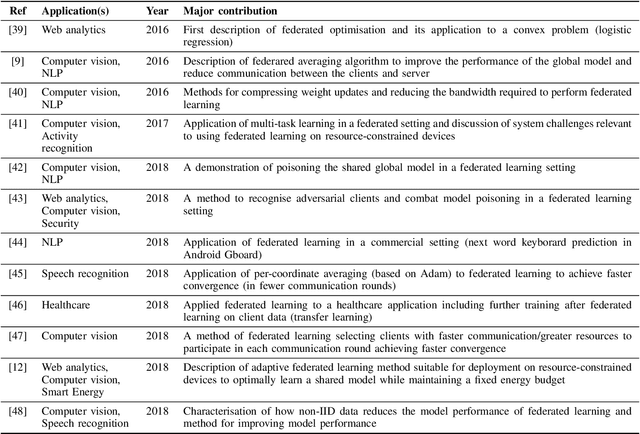
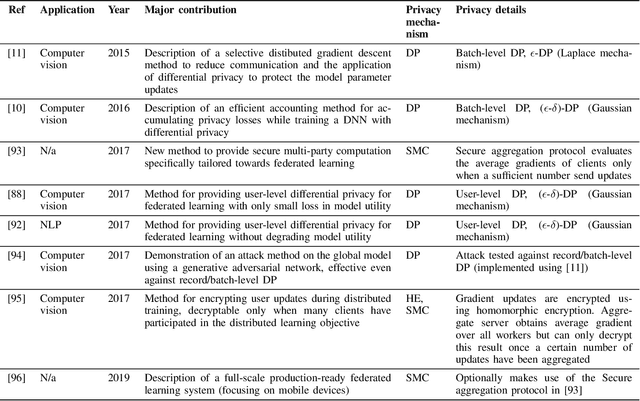
The Internet-of-Things generates vast quantities of data, much of it attributable to an individual's activity and behaviour. Holding and processing such personal data in a central location presents a significant privacy risk to individuals (of being identified or of their sensitive data being leaked). However, analytics based on machine learning and in particular deep learning benefit greatly from large amounts of data to develop high performance predictive models. Traditionally, data and models are stored and processed in a data centre environment where models are trained in a single location. This work reviews research around an alternative approach to machine learning known as federated learning which seeks to train machine learning models in a distributed fashion on devices in the user's domain, rather than by a centralised entity. Furthermore, we review additional privacy preserving methods applied to federated learning used to protect individuals from being identified during training and once a model is trained. Throughout this review, we identify the strengths and weaknesses of different methods applied to federated learning and finally, we outline future directions for privacy preserving federated learning research, particularly focusing on Internet-of-Things applications.