 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated learning with hierarchical clustering of local updates to improve training on non-IID data
Paper and Code
May 06, 2020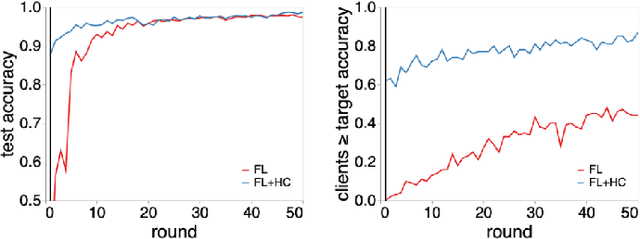
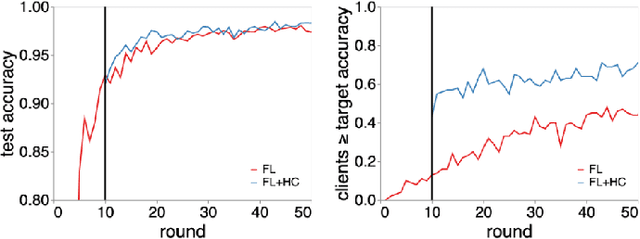
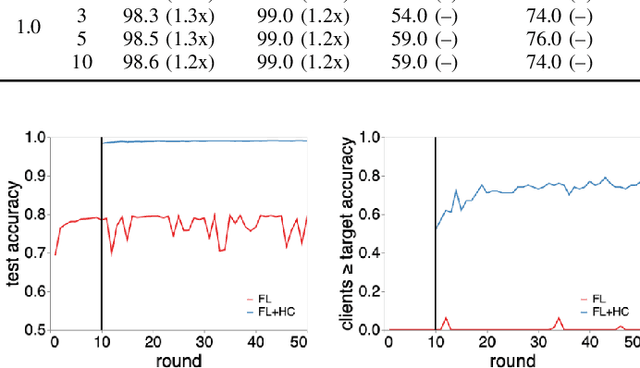
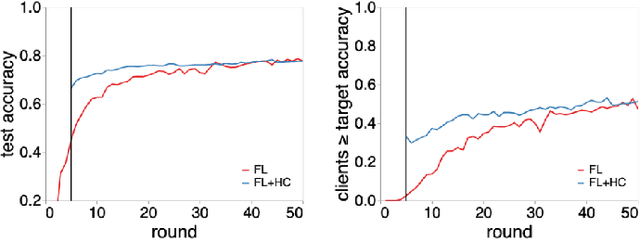
Federated learning (FL) is a well established method for performing machine learning tasks over massively distributed data. However in settings where data is distributed in a non-iid (not independent and identically distributed) fashion -- as is typical in real world situations -- the joint model produced by FL suffers in terms of test set accuracy and/or communication costs compared to training on iid data. We show that learning a single joint model is often not optimal in the presence of certain types of non-iid data. In this work we present a modification to FL by introducing a hierarchical clustering step (FL+HC) to separate clusters of clients by the similarity of their local updates to the global joint model. Once separated, the clusters are trained independently and in parallel on specialised models. We present a robust empirical analysis of the hyperparameters for FL+HC for several iid and non-iid settings. We show how FL+HC allows model training to converge in fewer communication rounds (significantly so under some non-iid settings) compared to FL without clustering. Additionally, FL+HC allows for a greater percentage of clients to reach a target accuracy compared to standard FL. Finally we make suggestions for good default hyperparameters to promote superior performing specialised models without modifying the the underlying federated learning communication protocol.