 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing the Confusion Loop: CLIP-Guided Alignment for Source-Free Domain Adaptation
Feb 09, 2026Source-Free Domain Adaptation (SFDA) tackles the problem of adapting a pre-trained source model to an unlabeled target domain without accessing any source data, which is quite suitable for the field of data security. Although recent advances have shown that pseudo-labeling strategies can be effective, they often fail in fine-grained scenarios due to subtle inter-class similarities. A critical but underexplored issue is the presence of asymmetric and dynamic class confusion, where visually similar classes are unequally and inconsistently misclassified by the source model. Existing methods typically ignore such confusion patterns, leading to noisy pseudo-labels and poor target discrimination. To address this, we propose CLIP-Guided Alignment(CGA), a novel framework that explicitly models and mitigates class confusion in SFDA. Generally, our method consists of three parts: (1) MCA: detects first directional confusion pairs by analyzing the predictions of the source model in the target domain; (2) MCC: leverages CLIP to construct confusion-aware textual prompts (e.g. a truck that looks like a bus), enabling more context-sensitive pseudo-labeling; and (3) FAM: builds confusion-guided feature banks for both CLIP and the source model and aligns them using contrastive learning to reduce ambiguity in the representation space. Extensive experiments on various datasets demonstrate that CGA consistently outperforms state-of-the-art SFDA methods, with especially notable gains in confusion-prone and fine-grained scenarios. Our results highlight the importance of explicitly modeling inter-class confusion for effective source-free adaptation. Our code can be find at https://github.com/soloiro/CGA
Single-Domain Generalized Object Detection by Balancing Domain Diversity and Invariance
Feb 06, 2025Single-domain generalization for object detection (S-DGOD) aims to transfer knowledge from a single source domain to unseen target domains. In recent years, many models have focused primarily on achieving feature invariance to enhance robustness. However, due to the inherent diversity across domains, an excessive emphasis on invariance can cause the model to overlook the actual differences between images. This overemphasis may complicate the training process and lead to a loss of valuable information. To address this issue, we propose the Diversity Invariance Detection Model (DIDM), which focuses on the balance between the diversity of domain-specific and invariance cross domains. Recognizing that domain diversity introduces variations in domain-specific features, we introduce a Diversity Learning Module (DLM). The DLM is designed to preserve the diversity of domain-specific information with proposed feature diversity loss while limiting the category semantics in the features. In addition, to maintain domain invariance, we incorporate a Weighted Aligning Module (WAM), which aligns features without compromising feature diversity. We conducted our model on five distinct datasets, which have illustrated the superior performance and effectiveness of the proposed model.
Gradually Vanishing Gap in Prototypical Network for Unsupervised Domain Adaptation
May 28, 2024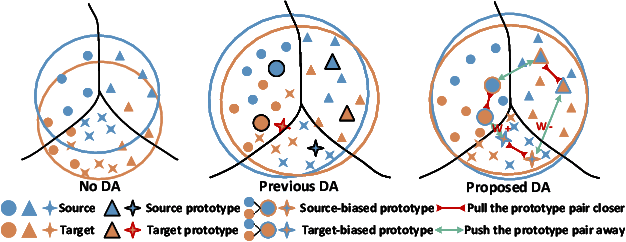

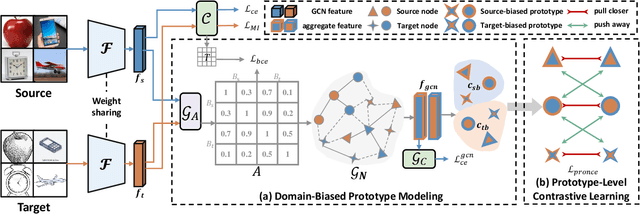
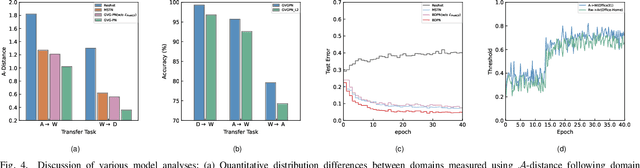
Unsupervised domain adaptation (UDA) is a critical problem for transfer learning, which aims to transfer the semantic information from labeled source domain to unlabeled target domain. Recent advancements in UDA models have demonstrated significant generalization capabilities on the target domain. However, the generalization boundary of UDA models remains unclear. When the domain discrepancy is too large, the model can not preserve the distribution structure, leading to distribution collapse during the alignment. To address this challenge, we propose an efficient UDA framework named Gradually Vanishing Gap in Prototypical Network (GVG-PN), which achieves transfer learning from both global and local perspectives. From the global alignment standpoint, our model generates a domain-biased intermediate domain that helps preserve the distribution structures. By entangling cross-domain features, our model progressively reduces the risk of distribution collapse. However, only relying on global alignment is insufficient to preserve the distribution structure. To further enhance the inner relationships of features, we introduce the local perspective. We utilize the graph convolutional network (GCN) as an intuitive method to explore the internal relationships between features, ensuring the preservation of manifold structures and generating domain-biased prototypes. Additionally, we consider the discriminability of the inner relationships between features. We propose a pro-contrastive loss to enhance the discriminability at the prototype level by separating hard negative pairs. By incorporating both GCN and the pro-contrastive loss, our model fully explores fine-grained semantic relationships. Experiments on several UDA benchmarks validated that the proposed GVG-PN can clearly outperform the SOTA models.
Learning Causal Features for Incremental Object Detection
Mar 01, 2024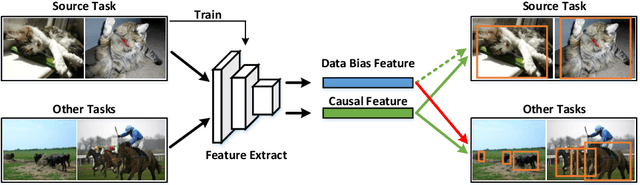
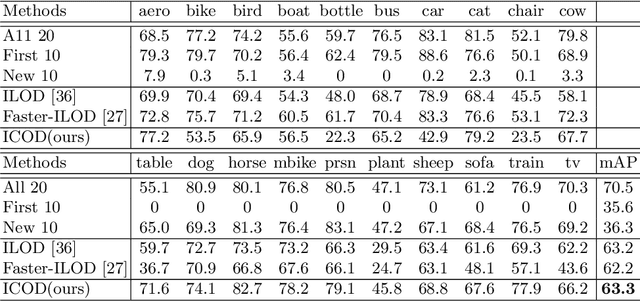
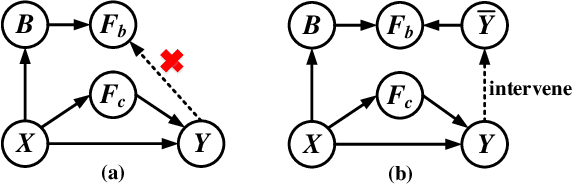
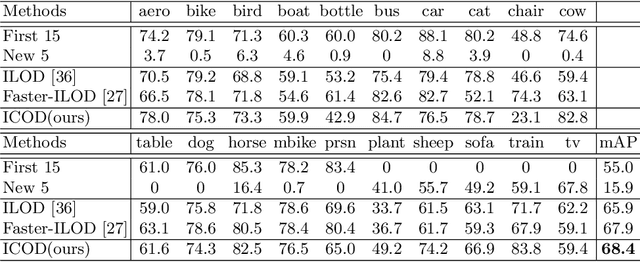
Object detection limits its recognizable categories during the training phase, in which it can not cover all objects of interest for users. To satisfy the practical necessity, the incremental learning ability of the detector becomes a critical factor for real-world applications. Unfortunately, neural networks unavoidably meet catastrophic forgetting problem when it is implemented on a new task. To this end, many incremental object detection models preserve the knowledge of previous tasks by replaying samples or distillation from previous models. However, they ignore an important factor that the performance of the model mostly depends on its feature. These models try to rouse the memory of the neural network with previous samples but not to prevent forgetting. To this end, in this paper, we propose an incremental causal object detection (ICOD) model by learning causal features, which can adapt to more tasks. Traditional object detection models, unavoidably depend on the data-bias or data-specific features to get the detection results, which can not adapt to the new task. When the model meets the requirements of incremental learning, the data-bias information is not beneficial to the new task, and the incremental learning may eliminate these features and lead to forgetting. To this end, our ICOD is introduced to learn the causal features, rather than the data-bias features when training the detector. Thus, when the model is implemented to a new task, the causal features of the old task can aid the incremental learning process to alleviate the catastrophic forgetting problem. We conduct our model on several experiments, which shows a causal feature without data-bias can make the model adapt to new tasks better. \keywords{Object detection, incremental learning, causal feature.
Tasks Integrated Networks: Joint Detection and Retrieval for Image Search
Sep 03, 2020The traditional object retrieval task aims to learn a discriminative feature representation with intra-similarity and inter-dissimilarity, which supposes that the objects in an image are manually or automatically pre-cropped exactly. However, in many real-world searching scenarios (e.g., video surveillance), the objects (e.g., persons, vehicles, etc.) are seldom accurately detected or annotated. Therefore, object-level retrieval becomes intractable without bounding-box annotation, which leads to a new but challenging topic, i.e. image-level search. In this paper, to address the image search issue, we first introduce an end-to-end Integrated Net (I-Net), which has three merits: 1) A Siamese architecture and an on-line pairing strategy for similar and dissimilar objects in the given images are designed. 2) A novel on-line pairing (OLP) loss is introduced with a dynamic feature dictionary, which alleviates the multi-task training stagnation problem, by automatically generating a number of negative pairs to restrict the positives. 3) A hard example priority (HEP) based softmax loss is proposed to improve the robustness of classification task by selecting hard categories. With the philosophy of divide and conquer, we further propose an improved I-Net, called DC-I-Net, which makes two new contributions: 1) two modules are tailored to handle different tasks separately in the integrated framework, such that the task specification is guaranteed. 2) A class-center guided HEP loss (C2HEP) by exploiting the stored class centers is proposed, such that the intra-similarity and inter-dissimilarity can be captured for ultimate retrieval. Extensive experiments on famous image-level search oriented benchmark datasets demonstrate that the proposed DC-I-Net outperforms the state-of-the-art tasks-integrated and tasks-separated image search models.
Domain Adaptive Object Detection via Asymmetric Tri-way Faster-RCNN
Jul 03, 2020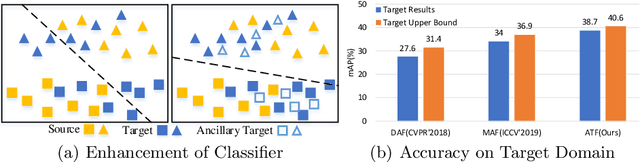
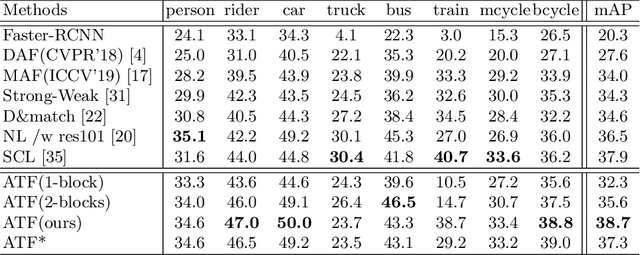
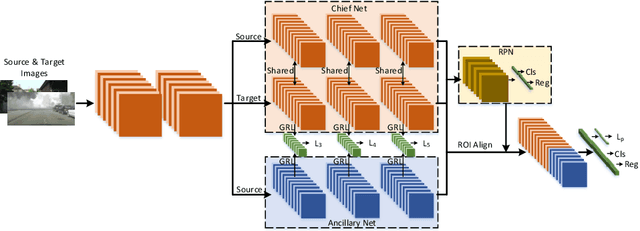

Conventional object detection models inevitably encounter a performance drop as the domain disparity exists. Unsupervised domain adaptive object detection is proposed recently to reduce the disparity between domains, where the source domain is label-rich while the target domain is label-agnostic. The existing models follow a parameter shared siamese structure for adversarial domain alignment, which, however, easily leads to the collapse and out-of-control risk of the source domain and brings negative impact to feature adaption. The main reason is that the labeling unfairness (asymmetry) between source and target makes the parameter sharing mechanism unable to adapt. Therefore, in order to avoid the source domain collapse risk caused by parameter sharing, we propose an asymmetric tri-way Faster-RCNN (ATF) for domain adaptive object detection. Our ATF model has two distinct merits: 1) A ancillary net supervised by source label is deployed to learn ancillary target features and simultaneously preserve the discrimination of source domain, which enhances the structural discrimination (object classification vs. bounding box regression) of domain alignment. 2) The asymmetric structure consisting of a chief net and an independent ancillary net essentially overcomes the parameter sharing aroused source risk collapse. The adaption safety of the proposed ATF detector is guaranteed. Extensive experiments on a number of datasets, including Cityscapes, Foggy-cityscapes, KITTI, Sim10k, Pascal VOC, Clipart and Watercolor, demonstrate the SOTA performance of our method.
Multi-adversarial Faster-RCNN for Unrestricted Object Detection
Sep 07, 2019
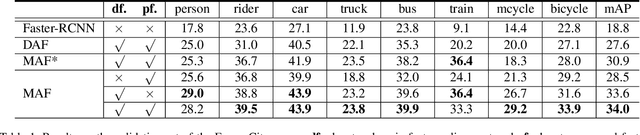
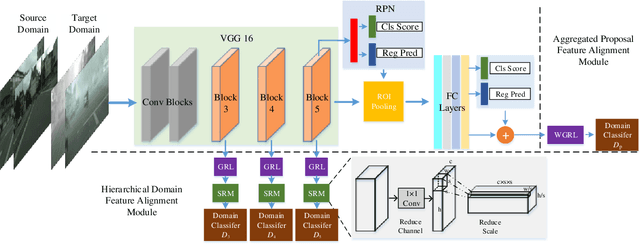
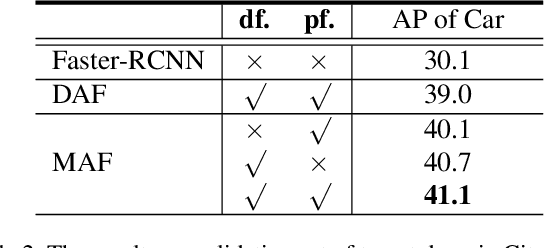
Conventional object detection methods essentially suppose that the training and testing data are collected from a restricted target domain with expensive labeling cost. For alleviating the problem of domain dependency and cumbersome labeling, this paper proposes to detect objects in an unrestricted environment by leveraging domain knowledge trained from an auxiliary source domain with sufficient labels. Specifically, we propose a multi-adversarial Faster-RCNN (MAF) framework for unrestricted object detection, which inherently addresses domain disparity minimization for domain adaptation in feature representation. The paper merits are in three-fold: 1) With the idea that object detectors often becomes domain incompatible when image distribution resulted domain disparity appears, we propose a hierarchical domain feature alignment module, in which multiple adversarial domain classifier submodules for layer-wise domain feature confusion are designed; 2) An information invariant scale reduction module (SRM) for hierarchical feature map resizing is proposed for promoting the training efficiency of adversarial domain adaptation; 3) In order to improve the domain adaptability, the aggregated proposal features with detection results are feed into a proposed weighted gradient reversal layer (WGRL) for characterizing hard confused domain samples. We evaluate our MAF on unrestricted tasks, including Cityscapes, KITTI, Sim10k, etc. and the experiments show the state-of-the-art performance over the existing detectors.
End-to-End Detection and Re-identification Integrated Net for Person Search
Apr 02, 2018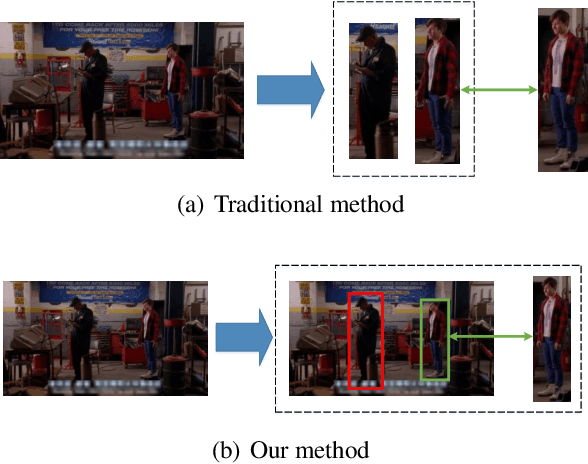
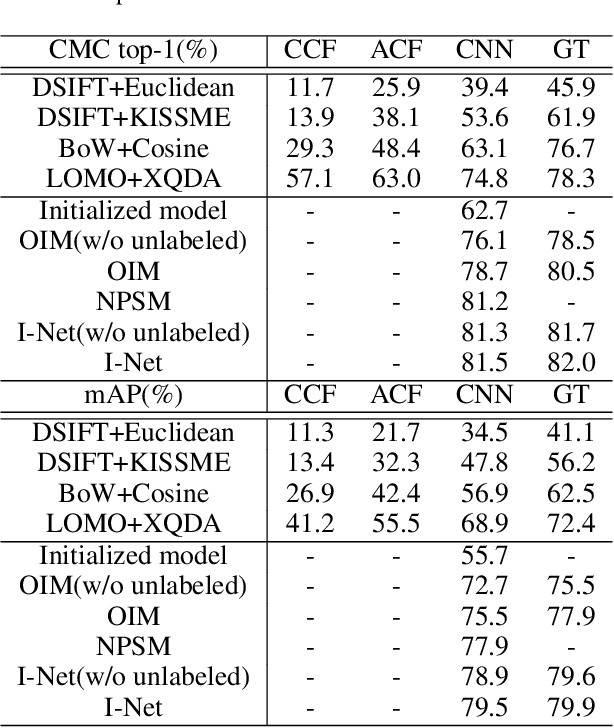
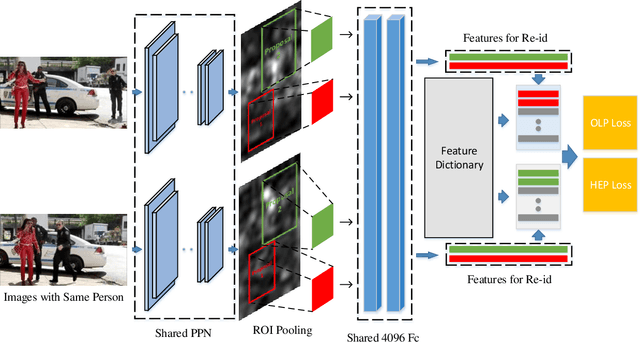

This paper proposes a pedestrian detection and re-identification (re-id) integration net (I-Net) in an end-to-end learning framework. The I-Net is used in real-world video surveillance scenarios, where the target person needs to be searched in the whole scene videos, while the annotations of pedestrian bounding boxes are unavailable. By comparing to the OIM which is a work for joint detection and re-id, we have three distinct contributions. First, we introduce a Siamese architecture of I-Net instead of 1 stream, such that a verification task can be implemented. Second, we propose a novel on-line pairing loss (OLP) and hard example priority softmax loss (HEP), such that only the hard negatives are posed much attention in loss computation. Third, an on-line dictionary for negative samples storage is designed in I-Net without recording the positive samples. We show our result on person search datasets, the gap between detection and re-identification is narrowed. The superior performance can be achieved.