 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-Boosted Decision Tree for Listwise Context Model in Multimodal Review Helpfulness Prediction
May 25, 2023



Multimodal Review Helpfulness Prediction (MRHP) aims to rank product reviews based on predicted helpfulness scores and has been widely applied in e-commerce via presenting customers with useful reviews. Previous studies commonly employ fully-connected neural networks (FCNNs) as the final score predictor and pairwise loss as the training objective. However, FCNNs have been shown to perform inefficient splitting for review features, making the model difficult to clearly differentiate helpful from unhelpful reviews. Furthermore, pairwise objective, which works on review pairs, may not completely capture the MRHP goal to produce the ranking for the entire review list, and possibly induces low generalization during testing. To address these issues, we propose a listwise attention network that clearly captures the MRHP ranking context and a listwise optimization objective that enhances model generalization. We further propose gradient-boosted decision tree as the score predictor to efficaciously partition product reviews' representations. Extensive experiments demonstrate that our method achieves state-of-the-art results and polished generalization performance on two large-scale MRHP benchmark datasets.
Improving the Inference of Topic Models via Infinite Latent State Replications
Jan 25, 2023
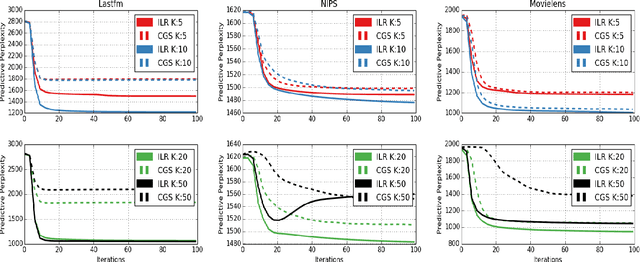


In text mining, topic models are a type of probabilistic generative models for inferring latent semantic topics from text corpus. One of the most popular inference approaches to topic models is perhaps collapsed Gibbs sampling (CGS), which typically samples one single topic label for each observed document-word pair. In this paper, we aim at improving the inference of CGS for topic models. We propose to leverage state augmentation technique by maximizing the number of topic samples to infinity, and then develop a new inference approach, called infinite latent state replication (ILR), to generate robust soft topic assignment for each given document-word pair. Experimental results on the publicly available datasets show that ILR outperforms CGS for inference of existing established topic models.
Adaptive Contrastive Learning on Multimodal Transformer for Review Helpfulness Predictions
Nov 07, 2022Modern Review Helpfulness Prediction systems are dependent upon multiple modalities, typically texts and images. Unfortunately, those contemporary approaches pay scarce attention to polish representations of cross-modal relations and tend to suffer from inferior optimization. This might cause harm to model's predictions in numerous cases. To overcome the aforementioned issues, we propose Multimodal Contrastive Learning for Multimodal Review Helpfulness Prediction (MRHP) problem, concentrating on mutual information between input modalities to explicitly elaborate cross-modal relations. In addition, we introduce Adaptive Weighting scheme for our contrastive learning approach in order to increase flexibility in optimization. Lastly, we propose Multimodal Interaction module to address the unalignment nature of multimodal data, thereby assisting the model in producing more reasonable multimodal representations. Experimental results show that our method outperforms prior baselines and achieves state-of-the-art results on two publicly available benchmark datasets for MRHP problem.
SANCL: Multimodal Review Helpfulness Prediction with Selective Attention and Natural Contrastive Learning
Sep 16, 2022
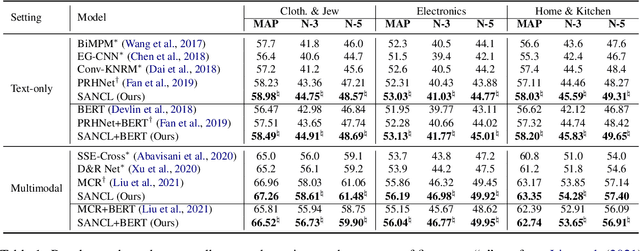


With the boom of e-commerce, Multimodal Review Helpfulness Prediction (MRHP), which aims to sort product reviews according to the predicted helpfulness scores has become a research hotspot. Previous work on this task focuses on attention-based modality fusion, information integration, and relation modeling, which primarily exposes the following drawbacks: 1) the model may fail to capture the really essential information due to its indiscriminate attention formulation; 2) lack appropriate modeling methods that take full advantage of correlation among provided data. In this paper, we propose SANCL: Selective Attention and Natural Contrastive Learning for MRHP. SANCL adopts a probe-based strategy to enforce high attention weights on the regions of greater significance. It also constructs a contrastive learning framework based on natural matching properties in the dataset. Experimental results on two benchmark datasets with three categories show that SANCL achieves state-of-the-art baseline performance with lower memory consumption.
DeepMnemonic: Password Mnemonic Generation via Deep Attentive Encoder-Decoder Model
Jun 24, 2020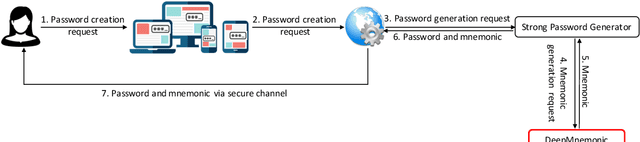

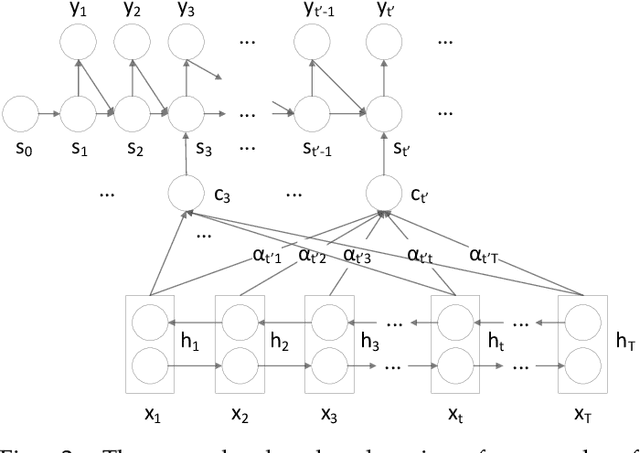
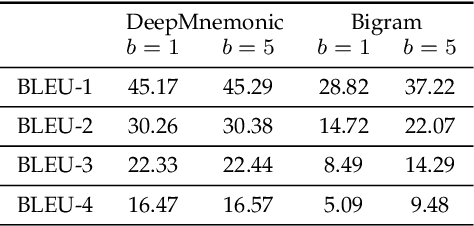
Strong passwords are fundamental to the security of password-based user authentication systems. In recent years, much effort has been made to evaluate password strength or to generate strong passwords. Unfortunately, the usability or memorability of the strong passwords has been largely neglected. In this paper, we aim to bridge the gap between strong password generation and the usability of strong passwords. We propose to automatically generate textual password mnemonics, i.e., natural language sentences, which are intended to help users better memorize passwords. We introduce \textit{DeepMnemonic}, a deep attentive encoder-decoder framework which takes a password as input and then automatically generates a mnemonic sentence for the password. We conduct extensive experiments to evaluate DeepMnemonic on the real-world data sets. The experimental results demonstrate that DeepMnemonic outperforms a well-known baseline for generating semantically meaningful mnemonic sentences. Moreover, the user study further validates that the generated mnemonic sentences by DeepMnemonic are useful in helping users memorize strong passwords.
Heron Inference for Bayesian Graphical Models
Feb 19, 2018



Bayesian graphical models have been shown to be a powerful tool for discovering uncertainty and causal structure from real-world data in many application fields. Current inference methods primarily follow different kinds of trade-offs between computational complexity and predictive accuracy. At one end of the spectrum, variational inference approaches perform well in computational efficiency, while at the other end, Gibbs sampling approaches are known to be relatively accurate for prediction in practice. In this paper, we extend an existing Gibbs sampling method, and propose a new deterministic Heron inference (Heron) for a family of Bayesian graphical models. In addition to the support for nontrivial distributability, one more benefit of Heron is that it is able to not only allow us to easily assess the convergence status but also largely improve the running efficiency. We evaluate Heron against the standard collapsed Gibbs sampler and state-of-the-art state augmentation method in inference for well-known graphical models. Experimental results using publicly available real-life data have demonstrated that Heron significantly outperforms the baseline methods for inferring Bayesian graphical models.