 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenCompass: A Universal Evaluation Platform for Large Language Models
May 19, 2026In recent years, the field of artificial intelligence has undergone a paradigm shift from task-specific small-scale models to general-purpose large language models (LLMs). With the rapid iteration of LLMs, objective, quantitative, and comprehensive evaluation of their capabilities has become a critical link in advancing technological development. Currently, the mainstream static benchmark dataset-based evaluation methods face challenges such as the diversity of task types, inconsistent evaluation criteria, and fragmentation of data and processing workflows, making it difficult to efficiently conduct cross-domain and large-scale model evaluation. To address the aforementioned issues, this paper proposes and open-sources OpenCompass, a one-stop, scalable, and high-concurrency-supported general-purpose LLM evaluation platform. Adhering to the design philosophy of modularization and component decoupling, the platform boasts three core advantages: high compatibility, flexibility, and high concurrency. The core architecture of OpenCompass comprises five key components: the Configuration System, Task Partitioning Module, Execution and Scheduling Module, Task Execution Unit, and Result Visualization Module. Its workflow provides rule-based, LLM-as-a-Judge, and cascaded evaluators to adapt to the requirements of different task scenarios. Supporting mainstream benchmark datasets across multiple domains, including knowledge, reasoning, computation, science, language, code, etc., the platform offers a unified and efficient LLM evaluation tool for both academia and industry, facilitating the accurate identification of strengths and weaknesses of LLMs as well as their subsequent optimization.
Multimodal OCR: Parse Anything from Documents
Mar 13, 2026We present Multimodal OCR (MOCR), a document parsing paradigm that jointly parses text and graphics into unified textual representations. Unlike conventional OCR systems that focus on text recognition and leave graphical regions as cropped pixels, our method, termed dots.mocr, treats visual elements such as charts, diagrams, tables, and icons as first-class parsing targets, enabling systems to parse documents while preserving semantic relationships across elements. It offers several advantages: (1) it reconstructs both text and graphics as structured outputs, enabling more faithful document reconstruction; (2) it supports end-to-end training over heterogeneous document elements, allowing models to exploit semantic relations between textual and visual components; and (3) it converts previously discarded graphics into reusable code-level supervision, unlocking multimodal supervision embedded in existing documents. To make this paradigm practical at scale, we build a comprehensive data engine from PDFs, rendered webpages, and native SVG assets, and train a compact 3B-parameter model through staged pretraining and supervised fine-tuning. We evaluate dots.mocr from two perspectives: document parsing and structured graphics parsing. On document parsing benchmarks, it ranks second only to Gemini 3 Pro on our OCR Arena Elo leaderboard, surpasses existing open-source document parsing systems, and sets a new state of the art of 83.9 on olmOCR Bench. On structured graphics parsing, dots.mocr achieves higher reconstruction quality than Gemini 3 Pro across image-to-SVG benchmarks, demonstrating strong performance on charts, UI layouts, scientific figures, and chemical diagrams. These results show a scalable path toward building large-scale image-to-code corpora for multimodal pretraining. Code and models are publicly available at https://github.com/rednote-hilab/dots.mocr.
Improving Pixel-based MIM by Reducing Wasted Modeling Capability
Aug 01, 2023
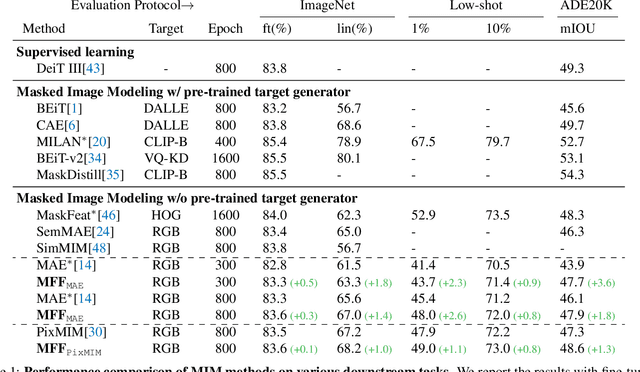

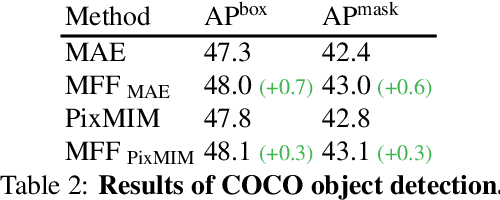
There has been significant progress in Masked Image Modeling (MIM). Existing MIM methods can be broadly categorized into two groups based on the reconstruction target: pixel-based and tokenizer-based approaches. The former offers a simpler pipeline and lower computational cost, but it is known to be biased toward high-frequency details. In this paper, we provide a set of empirical studies to confirm this limitation of pixel-based MIM and propose a new method that explicitly utilizes low-level features from shallow layers to aid pixel reconstruction. By incorporating this design into our base method, MAE, we reduce the wasted modeling capability of pixel-based MIM, improving its convergence and achieving non-trivial improvements across various downstream tasks. To the best of our knowledge, we are the first to systematically investigate multi-level feature fusion for isotropic architectures like the standard Vision Transformer (ViT). Notably, when applied to a smaller model (e.g., ViT-S), our method yields significant performance gains, such as 1.2\% on fine-tuning, 2.8\% on linear probing, and 2.6\% on semantic segmentation. Code and models are available at https://github.com/open-mmlab/mmpretrain.
A Light-Weight Object Detection Framework with FPA Module for Optical Remote Sensing Imagery
Sep 07, 2020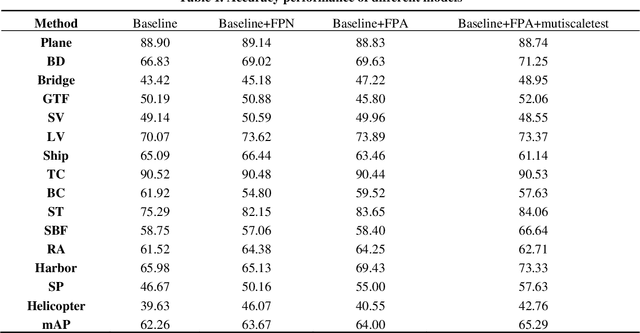
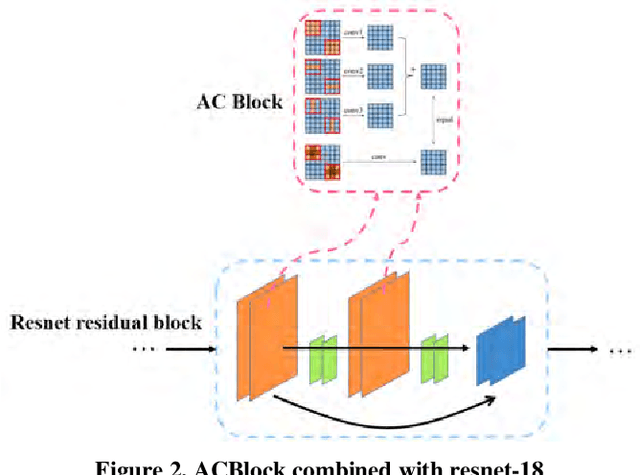
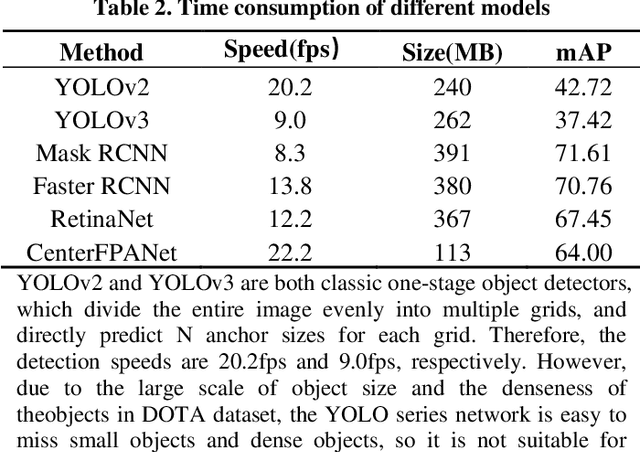
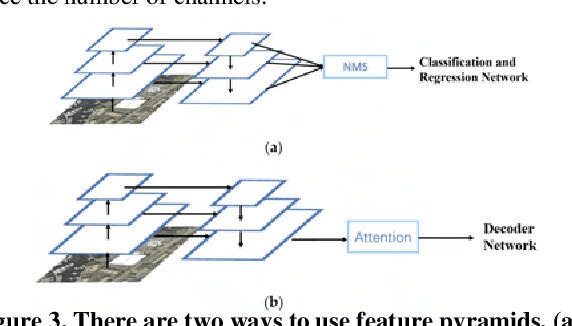
With the development of remote sensing technology, the acquisition of remote sensing images is easier and easier, which provides sufficient data resources for the task of detecting remote sensing objects. However, how to detect objects quickly and accurately from many complex optical remote sensing images is a challenging hot issue. In this paper, we propose an efficient anchor free object detector, CenterFPANet. To pursue speed, we use a lightweight backbone and introduce the asymmetric revolution block. To improve the accuracy, we designed the FPA module, which links the feature maps of different levels, and introduces the attention mechanism to dynamically adjust the weights of each level of feature maps, which solves the problem of detection difficulty caused by large size range of remote sensing objects. This strategy can improve the accuracy of remote sensing image object detection without reducing the detection speed. On the DOTA dataset, CenterFPANet mAP is 64.00%, and FPS is 22.2, which is close to the accuracy of the anchor-based methods currently used and much faster than them. Compared with Faster RCNN, mAP is 6.76% lower but 60.87% faster. All in all, CenterFPANet achieves a balance between speed and accuracy in large-scale optical remote sensing object detection.
Differentiating Features for Scene Segmentation Based on Dedicated Attention Mechanisms
Nov 19, 2019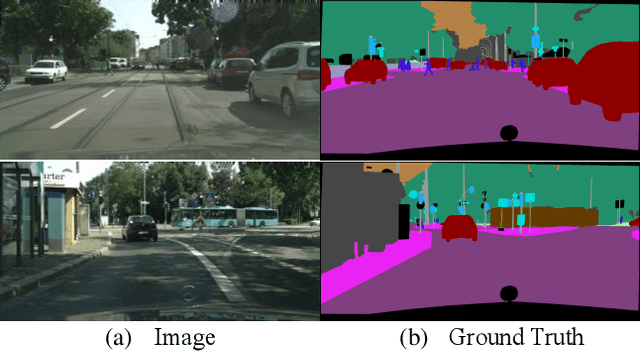

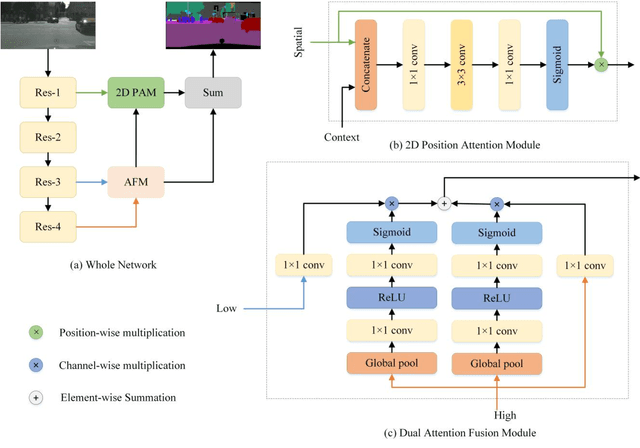
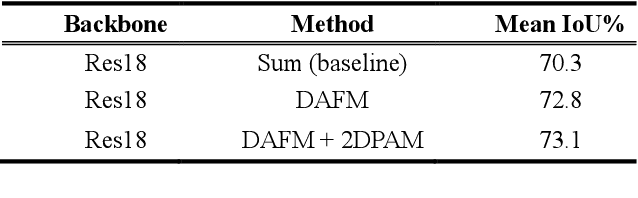
Semantic segmentation is a challenge in scene parsing. It requires both context information and rich spatial information. In this paper, we differentiate features for scene segmentation based on dedicated attention mechanisms (DF-DAM), and two attention modules are proposed to optimize the high-level and low-level features in the encoder, respectively. Specifically, we use the high-level and low-level features of ResNet as the source of context information and spatial information, respectively, and optimize them with attention fusion module and 2D position attention module, respectively. For attention fusion module, we adopt dual channel weight to selectively adjust the channel map for the highest two stage features of ResNet, and fuse them to get context information. For 2D position attention module, we use the context information obtained by attention fusion module to assist the selection of the lowest-stage features of ResNet as supplementary spatial information. Finally, the two sets of information obtained by the two modules are simply fused to obtain the prediction. We evaluate our approach on Cityscapes and PASCAL VOC 2012 datasets. In particular, there aren't complicated and redundant processing modules in our architecture, which greatly reduces the complexity, and we achieving 82.3% Mean IoU on PASCAL VOC 2012 test dataset without pre-training on MS-COCO dataset.