 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiating Features for Scene Segmentation Based on Dedicated Attention Mechanisms
Nov 19, 2019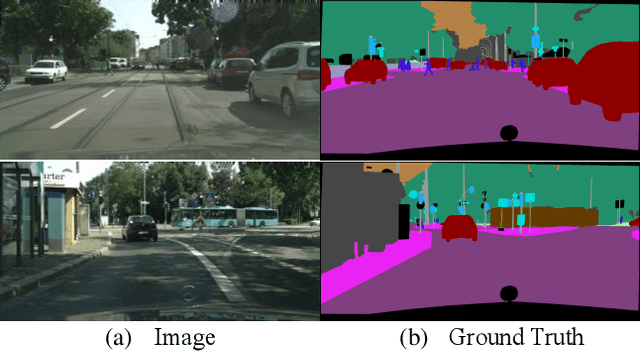

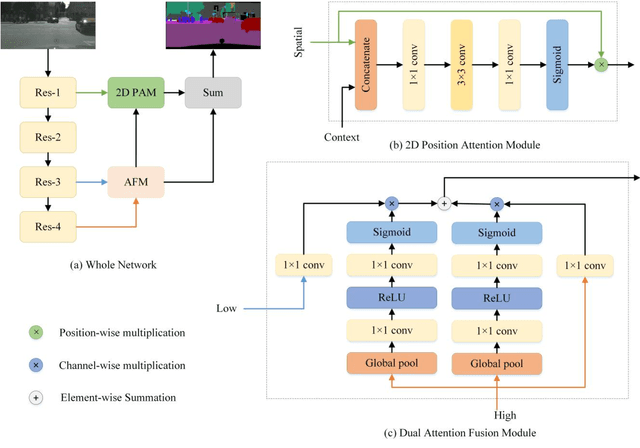
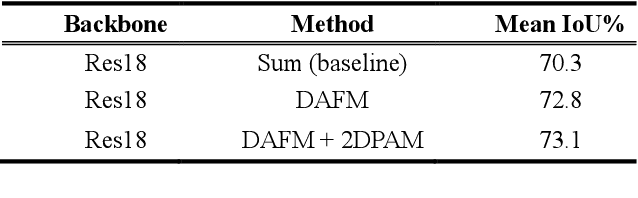
Semantic segmentation is a challenge in scene parsing. It requires both context information and rich spatial information. In this paper, we differentiate features for scene segmentation based on dedicated attention mechanisms (DF-DAM), and two attention modules are proposed to optimize the high-level and low-level features in the encoder, respectively. Specifically, we use the high-level and low-level features of ResNet as the source of context information and spatial information, respectively, and optimize them with attention fusion module and 2D position attention module, respectively. For attention fusion module, we adopt dual channel weight to selectively adjust the channel map for the highest two stage features of ResNet, and fuse them to get context information. For 2D position attention module, we use the context information obtained by attention fusion module to assist the selection of the lowest-stage features of ResNet as supplementary spatial information. Finally, the two sets of information obtained by the two modules are simply fused to obtain the prediction. We evaluate our approach on Cityscapes and PASCAL VOC 2012 datasets. In particular, there aren't complicated and redundant processing modules in our architecture, which greatly reduces the complexity, and we achieving 82.3% Mean IoU on PASCAL VOC 2012 test dataset without pre-training on MS-COCO dataset.