 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized federated learning, Row-wise fusion regularization, Multivariate modeling, Sparse estimation
Oct 16, 2025We study personalized federated learning for multivariate responses where client models are heterogeneous yet share variable-level structure. Existing entry-wise penalties ignore cross-response dependence, while matrix-wise fusion over-couples clients. We propose a Sparse Row-wise Fusion (SROF) regularizer that clusters row vectors across clients and induces within-row sparsity, and we develop RowFed, a communication-efficient federated algorithm that embeds SROF into a linearized ADMM framework with privacy-preserving partial participation. Theoretically, we establish an oracle property for SROF-achieving correct variable-level group recovery with asymptotic normality-and prove convergence of RowFed to a stationary solution. Under random client participation, the iterate gap contracts at a rate that improves with participation probability. Empirically, simulations in heterogeneous regimes show that RowFed consistently lowers estimation and prediction error and strengthens variable-level cluster recovery over NonFed, FedAvg, and a personalized matrix-fusion baseline. A real-data study further corroborates these gains while preserving interpretability. Together, our results position row-wise fusion as an effective and transparent paradigm for large-scale personalized federated multivariate learning, bridging the gap between entry-wise and matrix-wise formulations.
SOFARI-R: High-Dimensional Manifold-Based Inference for Latent Responses
Apr 24, 2025



Data reduction with uncertainty quantification plays a key role in various multi-task learning applications, where large numbers of responses and features are present. To this end, a general framework of high-dimensional manifold-based SOFAR inference (SOFARI) was introduced recently in Zheng, Zhou, Fan and Lv (2024) for interpretable multi-task learning inference focusing on the left factor vectors and singular values exploiting the latent singular value decomposition (SVD) structure. Yet, designing a valid inference procedure on the latent right factor vectors is not straightforward from that of the left ones and can be even more challenging due to asymmetry of left and right singular vectors in the response matrix. To tackle these issues, in this paper we suggest a new method of high-dimensional manifold-based SOFAR inference for latent responses (SOFARI-R), where two variants of SOFARI-R are introduced. The first variant deals with strongly orthogonal factors by coupling left singular vectors with the design matrix and then appropriately rescaling them to generate new Stiefel manifolds. The second variant handles the more general weakly orthogonal factors by employing the hard-thresholded SOFARI estimates and delicately incorporating approximation errors into the distribution. Both variants produce bias-corrected estimators for the latent right factor vectors that enjoy asymptotically normal distributions with justified asymptotic variance estimates. We demonstrate the effectiveness of the newly suggested method using extensive simulation studies and an economic application.
SOFARI: High-Dimensional Manifold-Based Inference
Sep 26, 2023Multi-task learning is a widely used technique for harnessing information from various tasks. Recently, the sparse orthogonal factor regression (SOFAR) framework, based on the sparse singular value decomposition (SVD) within the coefficient matrix, was introduced for interpretable multi-task learning, enabling the discovery of meaningful latent feature-response association networks across different layers. However, conducting precise inference on the latent factor matrices has remained challenging due to orthogonality constraints inherited from the sparse SVD constraint. In this paper, we suggest a novel approach called high-dimensional manifold-based SOFAR inference (SOFARI), drawing on the Neyman near-orthogonality inference while incorporating the Stiefel manifold structure imposed by the SVD constraints. By leveraging the underlying Stiefel manifold structure, SOFARI provides bias-corrected estimators for both latent left factor vectors and singular values, for which we show to enjoy the asymptotic mean-zero normal distributions with estimable variances. We introduce two SOFARI variants to handle strongly and weakly orthogonal latent factors, where the latter covers a broader range of applications. We illustrate the effectiveness of SOFARI and justify our theoretical results through simulation examples and a real data application in economic forecasting.
Parallel integrative learning for large-scale multi-response regression with incomplete outcomes
Apr 11, 2021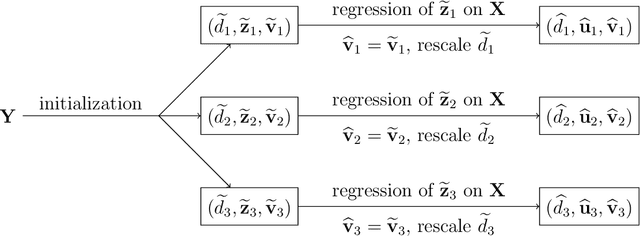
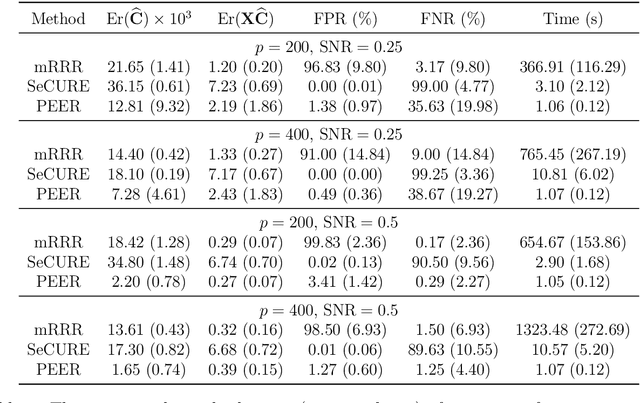
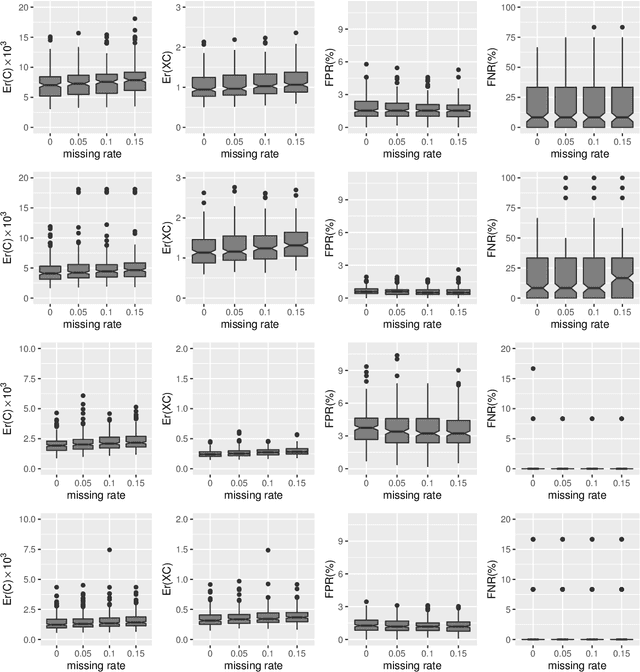

Multi-task learning is increasingly used to investigate the association structure between multiple responses and a single set of predictor variables in many applications. In the era of big data, the coexistence of incomplete outcomes, large number of responses, and high dimensionality in predictors poses unprecedented challenges in estimation, prediction, and computation. In this paper, we propose a scalable and computationally efficient procedure, called PEER, for large-scale multi-response regression with incomplete outcomes, where both the numbers of responses and predictors can be high-dimensional. Motivated by sparse factor regression, we convert the multi-response regression into a set of univariate-response regressions, which can be efficiently implemented in parallel. Under some mild regularity conditions, we show that PEER enjoys nice sampling properties including consistency in estimation, prediction, and variable selection. Extensive simulation studies show that our proposal compares favorably with several existing methods in estimation accuracy, variable selection, and computation efficiency.
* 32 pages
Statistically Guided Divide-and-Conquer for Sparse Factorization of Large Matrix
Mar 17, 2020



The sparse factorization of a large matrix is fundamental in modern statistical learning. In particular, the sparse singular value decomposition and its variants have been utilized in multivariate regression, factor analysis, biclustering, vector time series modeling, among others. The appeal of this factorization is owing to its power in discovering a highly-interpretable latent association network, either between samples and variables or between responses and predictors. However, many existing methods are either ad hoc without a general performance guarantee, or are computationally intensive, rendering them unsuitable for large-scale studies. We formulate the statistical problem as a sparse factor regression and tackle it with a divide-and-conquer approach. In the first stage of division, we consider both sequential and parallel approaches for simplifying the task into a set of co-sparse unit-rank estimation (CURE) problems, and establish the statistical underpinnings of these commonly-adopted and yet poorly understood deflation methods. In the second stage of division, we innovate a contended stagewise learning technique, consisting of a sequence of simple incremental updates, to efficiently trace out the whole solution paths of CURE. Our algorithm has a much lower computational complexity than alternating convex search, and the choice of the step size enables a flexible and principled tradeoff between statistical accuracy and computational efficiency. Our work is among the first to enable stagewise learning for non-convex problems, and the idea can be applicable in many multi-convex problems. Extensive simulation studies and an application in genetics demonstrate the effectiveness and scalability of our approach.
Nonsparse learning with latent variables
Oct 07, 2017

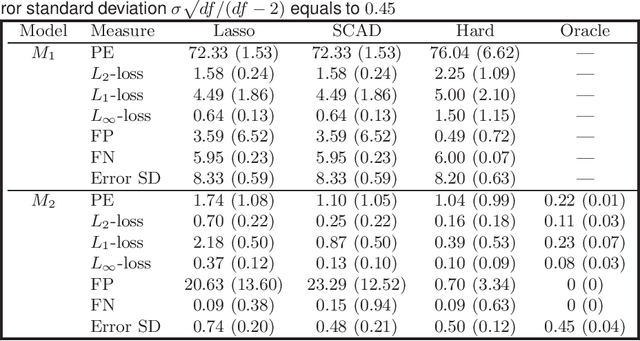
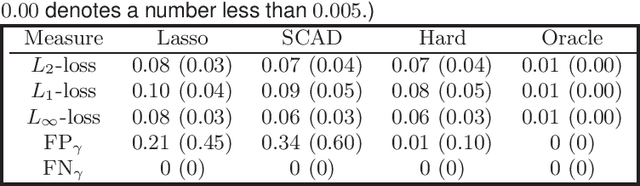
As a popular tool for producing meaningful and interpretable models, large-scale sparse learning works efficiently when the underlying structures are indeed or close to sparse. However, naively applying the existing regularization methods can result in misleading outcomes due to model misspecification. In particular, the direct sparsity assumption on coefficient vectors has been questioned in real applications. Therefore, we consider nonsparse learning with the conditional sparsity structure that the coefficient vector becomes sparse after taking out the impacts of certain unobservable latent variables. A new methodology of nonsparse learning with latent variables (NSL) is proposed to simultaneously recover the significant observable predictors and latent factors as well as their effects. We explore a common latent family incorporating population principal components and derive the convergence rates of both sample principal components and their score vectors that hold for a wide class of distributions. With the properly estimated latent variables, properties including model selection consistency and oracle inequalities under various prediction and estimation losses are established for the proposed methodology. Our new methodology and results are evidenced by simulation and real data examples.
The constrained Dantzig selector with enhanced consistency
May 11, 2016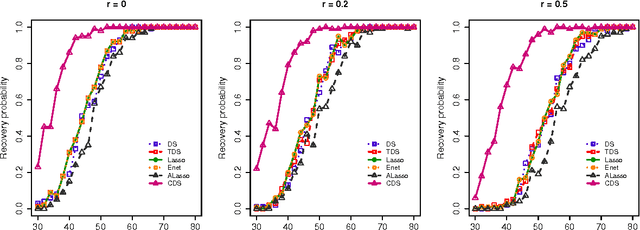


The Dantzig selector has received popularity for many applications such as compressed sensing and sparse modeling, thanks to its computational efficiency as a linear programming problem and its nice sampling properties. Existing results show that it can recover sparse signals mimicking the accuracy of the ideal procedure, up to a logarithmic factor of the dimensionality. Such a factor has been shown to hold for many regularization methods. An important question is whether this factor can be reduced to a logarithmic factor of the sample size in ultra-high dimensions under mild regularity conditions. To provide an affirmative answer, in this paper we suggest the constrained Dantzig selector, which has more flexible constraints and parameter space. We prove that the suggested method can achieve convergence rates within a logarithmic factor of the sample size of the oracle rates and improved sparsity, under a fairly weak assumption on the signal strength. Such improvement is significant in ultra-high dimensions. This method can be implemented efficiently through sequential linear programming. Numerical studies confirm that the sample size needed for a certain level of accuracy in these problems can be much reduced.
High dimensional thresholded regression and shrinkage effect
May 11, 2016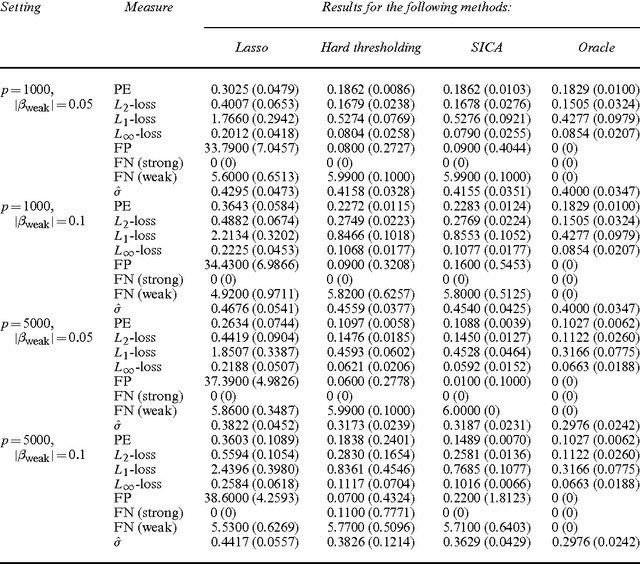
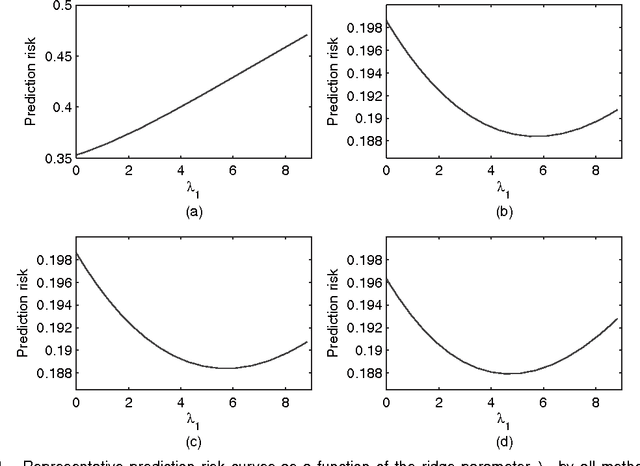

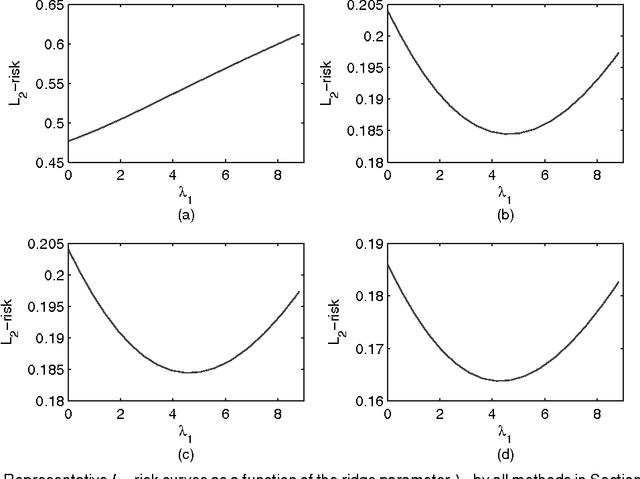
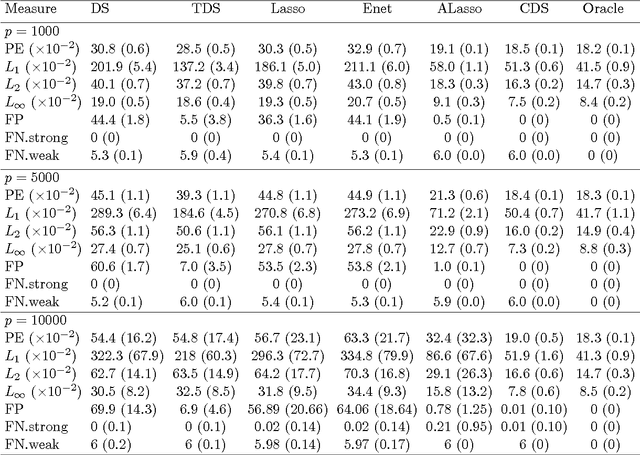
High-dimensional sparse modeling via regularization provides a powerful tool for analyzing large-scale data sets and obtaining meaningful, interpretable models. The use of nonconvex penalty functions shows advantage in selecting important features in high dimensions, but the global optimality of such methods still demands more understanding. In this paper, we consider sparse regression with hard-thresholding penalty, which we show to give rise to thresholded regression. This approach is motivated by its close connection with the $L_0$-regularization, which can be unrealistic to implement in practice but of appealing sampling properties, and its computational advantage. Under some mild regularity conditions allowing possibly exponentially growing dimensionality, we establish the oracle inequalities of the resulting regularized estimator, as the global minimizer, under various prediction and variable selection losses, as well as the oracle risk inequalities of the hard-thresholded estimator followed by a further $L_2$-regularization. The risk properties exhibit interesting shrinkage effects under both estimation and prediction losses. We identify the optimal choice of the ridge parameter, which is shown to have simultaneous advantages to both the $L_2$-loss and prediction loss. These new results and phenomena are evidenced by simulation and real data examples.
* 23 pages, 3 figures, 5 tables
Innovated interaction screening for high-dimensional nonlinear classification
Jun 03, 2015


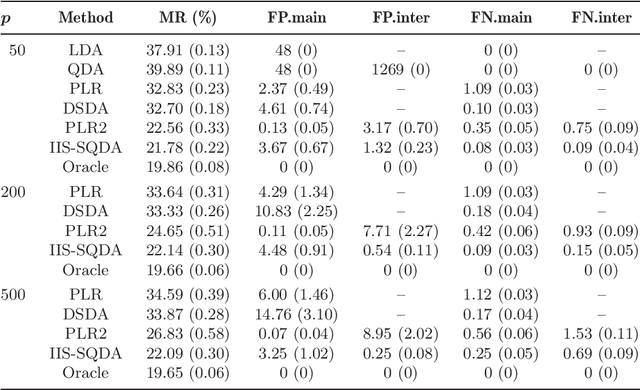
This paper is concerned with the problems of interaction screening and nonlinear classification in a high-dimensional setting. We propose a two-step procedure, IIS-SQDA, where in the first step an innovated interaction screening (IIS) approach based on transforming the original $p$-dimensional feature vector is proposed, and in the second step a sparse quadratic discriminant analysis (SQDA) is proposed for further selecting important interactions and main effects and simultaneously conducting classification. Our IIS approach screens important interactions by examining only $p$ features instead of all two-way interactions of order $O(p^2)$. Our theory shows that the proposed method enjoys sure screening property in interaction selection in the high-dimensional setting of $p$ growing exponentially with the sample size. In the selection and classification step, we establish a sparse inequality on the estimated coefficient vector for QDA and prove that the classification error of our procedure can be upper-bounded by the oracle classification error plus some smaller order term. Extensive simulation studies and real data analysis show that our proposal compares favorably with existing methods in interaction selection and high-dimensional classification.
* Published at http://dx.doi.org/10.1214/14-AOS1308 in the Annals of Statistics (http://www.imstat.org/aos/) by the Institute of Mathematical Statistics (http://www.imstat.org)