 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel integrative learning for large-scale multi-response regression with incomplete outcomes
Apr 11, 2021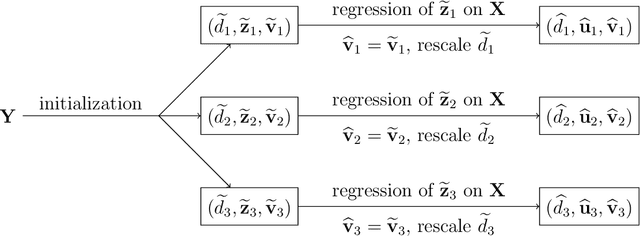
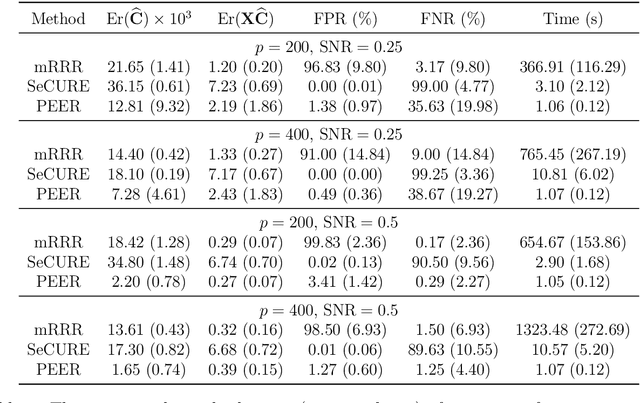
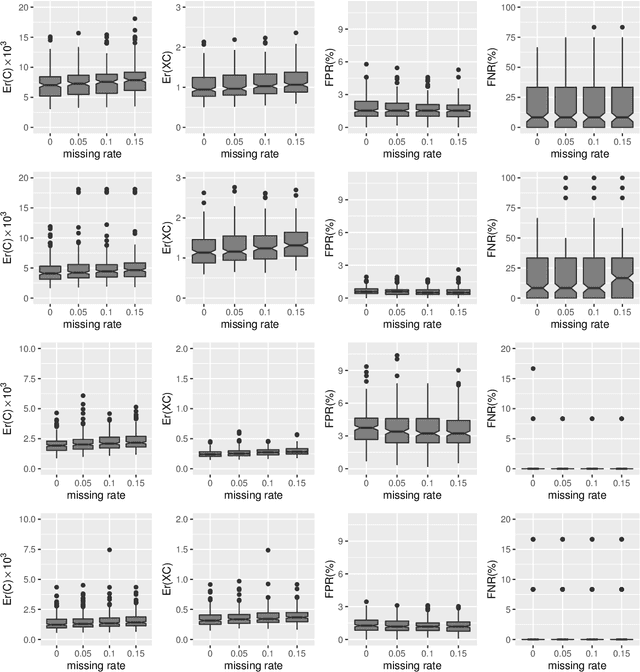

Multi-task learning is increasingly used to investigate the association structure between multiple responses and a single set of predictor variables in many applications. In the era of big data, the coexistence of incomplete outcomes, large number of responses, and high dimensionality in predictors poses unprecedented challenges in estimation, prediction, and computation. In this paper, we propose a scalable and computationally efficient procedure, called PEER, for large-scale multi-response regression with incomplete outcomes, where both the numbers of responses and predictors can be high-dimensional. Motivated by sparse factor regression, we convert the multi-response regression into a set of univariate-response regressions, which can be efficiently implemented in parallel. Under some mild regularity conditions, we show that PEER enjoys nice sampling properties including consistency in estimation, prediction, and variable selection. Extensive simulation studies show that our proposal compares favorably with several existing methods in estimation accuracy, variable selection, and computation efficiency.
* 32 pages
Interaction Pursuit with Feature Screening and Selection
May 28, 2016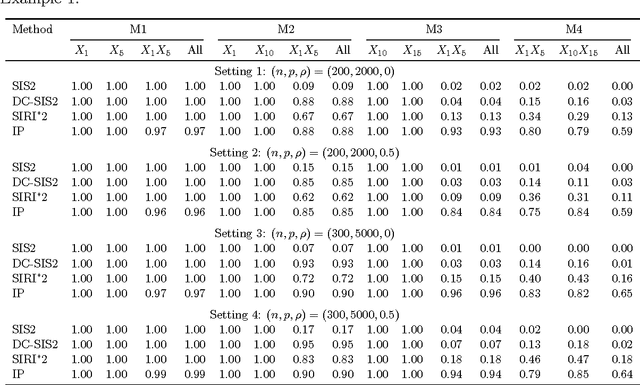
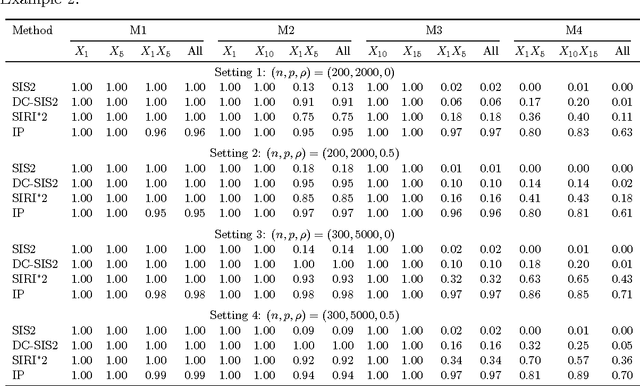
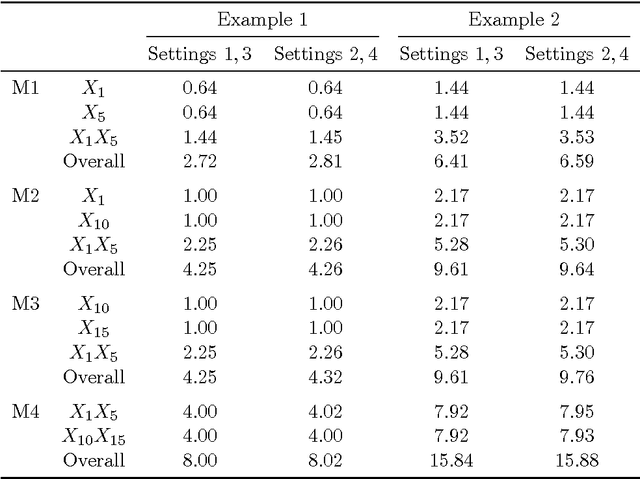
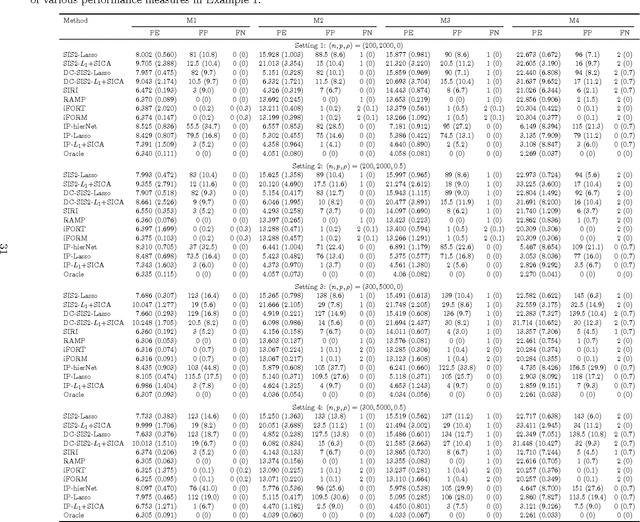
Understanding how features interact with each other is of paramount importance in many scientific discoveries and contemporary applications. Yet interaction identification becomes challenging even for a moderate number of covariates. In this paper, we suggest an efficient and flexible procedure, called the interaction pursuit (IP), for interaction identification in ultra-high dimensions. The suggested method first reduces the number of interactions and main effects to a moderate scale by a new feature screening approach, and then selects important interactions and main effects in the reduced feature space using regularization methods. Compared to existing approaches, our method screens interactions separately from main effects and thus can be more effective in interaction screening. Under a fairly general framework, we establish that for both interactions and main effects, the method enjoys the sure screening property in screening and oracle inequalities in selection. Our method and theoretical results are supported by several simulation and real data examples.
Interaction pursuit in high-dimensional multi-response regression via distance correlation
May 11, 2016
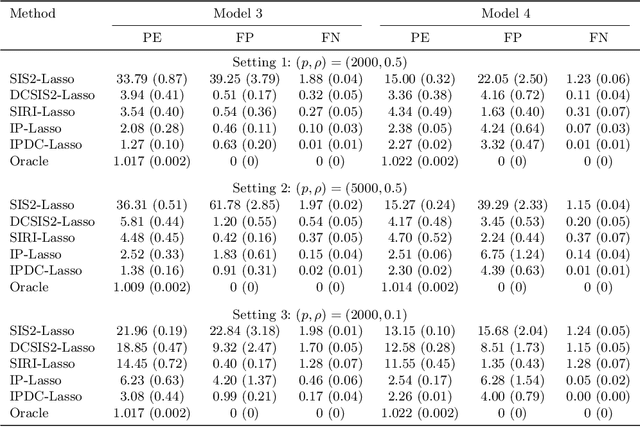
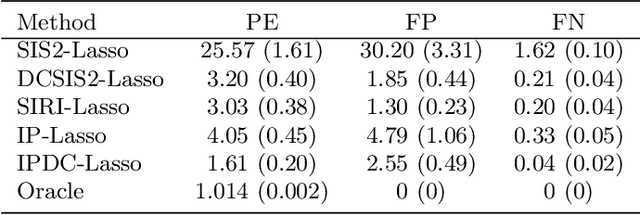
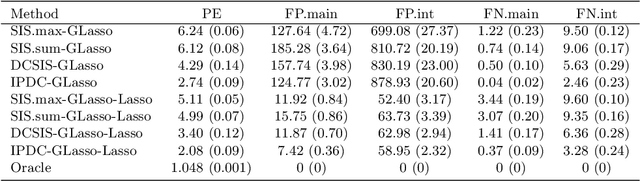
Feature interactions can contribute to a large proportion of variation in many prediction models. In the era of big data, the coexistence of high dimensionality in both responses and covariates poses unprecedented challenges in identifying important interactions. In this paper, we suggest a two-stage interaction identification method, called the interaction pursuit via distance correlation (IPDC), in the setting of high-dimensional multi-response interaction models that exploits feature screening applied to transformed variables with distance correlation followed by feature selection. Such a procedure is computationally efficient, generally applicable beyond the heredity assumption, and effective even when the number of responses diverges with the sample size. Under mild regularity conditions, we show that this method enjoys nice theoretical properties including the sure screening property, support union recovery, and oracle inequalities in prediction and estimation for both interactions and main effects. The advantages of our method are supported by several simulation studies and real data analysis.
Innovated interaction screening for high-dimensional nonlinear classification
Jun 03, 2015


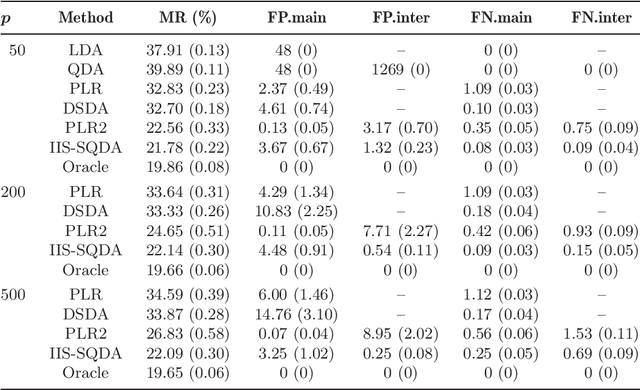
This paper is concerned with the problems of interaction screening and nonlinear classification in a high-dimensional setting. We propose a two-step procedure, IIS-SQDA, where in the first step an innovated interaction screening (IIS) approach based on transforming the original $p$-dimensional feature vector is proposed, and in the second step a sparse quadratic discriminant analysis (SQDA) is proposed for further selecting important interactions and main effects and simultaneously conducting classification. Our IIS approach screens important interactions by examining only $p$ features instead of all two-way interactions of order $O(p^2)$. Our theory shows that the proposed method enjoys sure screening property in interaction selection in the high-dimensional setting of $p$ growing exponentially with the sample size. In the selection and classification step, we establish a sparse inequality on the estimated coefficient vector for QDA and prove that the classification error of our procedure can be upper-bounded by the oracle classification error plus some smaller order term. Extensive simulation studies and real data analysis show that our proposal compares favorably with existing methods in interaction selection and high-dimensional classification.
* Published at http://dx.doi.org/10.1214/14-AOS1308 in the Annals of Statistics (http://www.imstat.org/aos/) by the Institute of Mathematical Statistics (http://www.imstat.org)