 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Parameter Efficiency and Generalization in Large-Scale Models: A Regularized and Masked Low-Rank Adaptation Approach
Jul 16, 2024



Large pre-trained models, such as large language models (LLMs), present significant resource challenges for fine-tuning due to their extensive parameter sizes, especially for applications in mobile systems. To address this, Low-Rank Adaptation (LoRA) has been developed to reduce resource consumption while maintaining satisfactory fine-tuning results. Despite its effectiveness, the original LoRA method faces challenges of suboptimal performance and overfitting. This paper investigates the intrinsic dimension of the matrix updates approximated by the LoRA method and reveals the performance benefits of increasing this intrinsic dimension. By employing regularization and a gradient masking method that encourages higher intrinsic dimension, the proposed method, termed Regularized and Masked LoRA (RM-LoRA), achieves superior generalization performance with the same or lower trainable parameter budget compared to the original LoRA and its latest variants across various open-source vision and language datasets.
FL-TAC: Enhanced Fine-Tuning in Federated Learning via Low-Rank, Task-Specific Adapter Clustering
Apr 23, 2024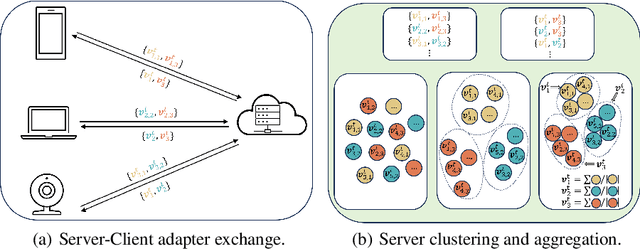

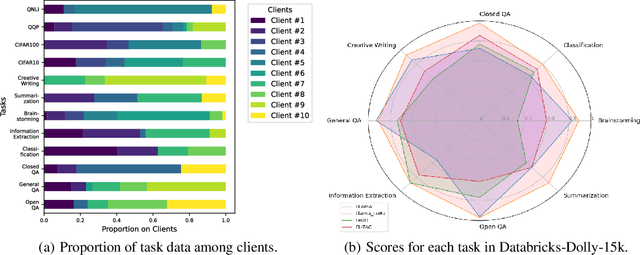
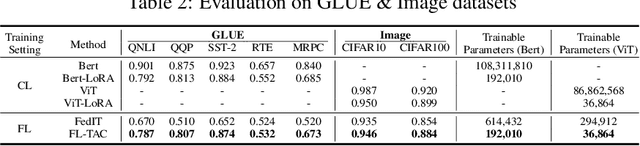
Although large-scale pre-trained models hold great potential for adapting to downstream tasks through fine-tuning, the performance of such fine-tuned models is often limited by the difficulty of collecting sufficient high-quality, task-specific data. Federated Learning (FL) offers a promising solution by enabling fine-tuning across large-scale clients with a variety of task data, but it is bottlenecked by significant communication overhead due to the pre-trained models' extensive size. This paper addresses the high communication cost for fine-tuning large pre-trained models within FL frameworks through low-rank fine-tuning. Specifically, we train a low-rank adapter for each individual task on the client side, followed by server-side clustering for similar group of adapters to achieve task-specific aggregation. Extensive experiments on various language and vision tasks, such as GLUE and CIFAR-10/100, reveal the evolution of task-specific adapters throughout the FL training process and verify the effectiveness of the proposed low-rank task-specific adapter clustering (TAC) method.
AQUILA: Communication Efficient Federated Learning with Adaptive Quantization of Lazily-Aggregated Gradients
Aug 01, 2023



The widespread adoption of Federated Learning (FL), a privacy-preserving distributed learning methodology, has been impeded by the challenge of high communication overheads, typically arising from the transmission of large-scale models. Existing adaptive quantization methods, designed to mitigate these overheads, operate under the impractical assumption of uniform device participation in every training round. Additionally, these methods are limited in their adaptability due to the necessity of manual quantization level selection and often overlook biases inherent in local devices' data, thereby affecting the robustness of the global model. In response, this paper introduces AQUILA (adaptive quantization of lazily-aggregated gradients), a novel adaptive framework devised to effectively handle these issues, enhancing the efficiency and robustness of FL. AQUILA integrates a sophisticated device selection method that prioritizes the quality and usefulness of device updates. Utilizing the exact global model stored by devices, it enables a more precise device selection criterion, reduces model deviation, and limits the need for hyperparameter adjustments. Furthermore, AQUILA presents an innovative quantization criterion, optimized to improve communication efficiency while assuring model convergence. Our experiments demonstrate that AQUILA significantly decreases communication costs compared to existing methods, while maintaining comparable model performance across diverse non-homogeneous FL settings, such as Non-IID data and heterogeneous model architectures.
SAFARI: Sparsity enabled Federated Learning with Limited and Unreliable Communications
Apr 05, 2022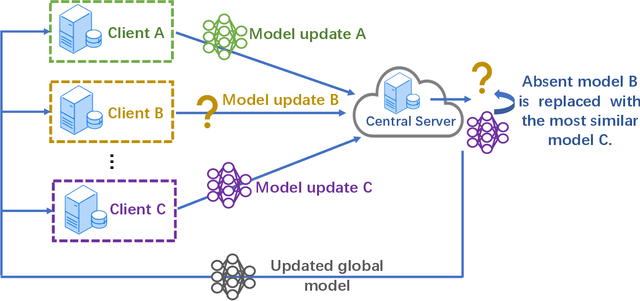
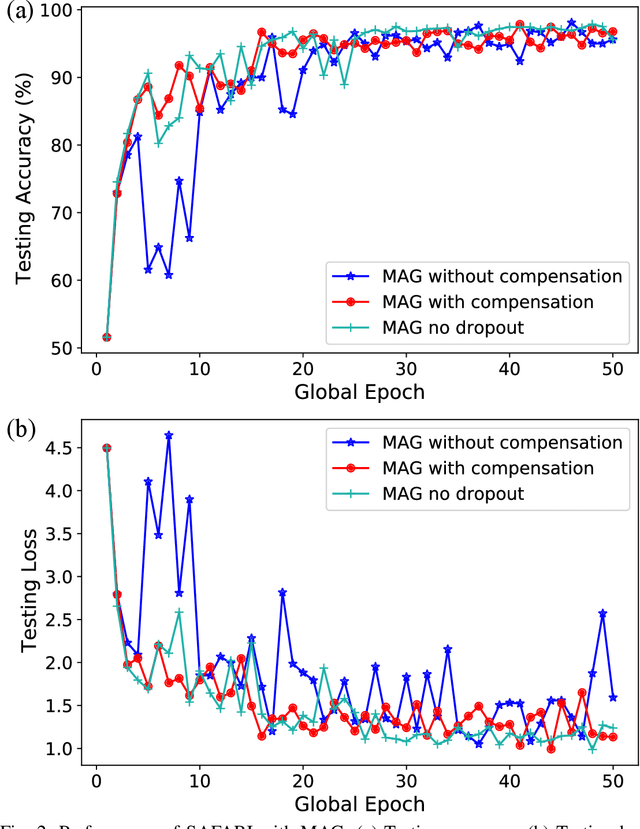
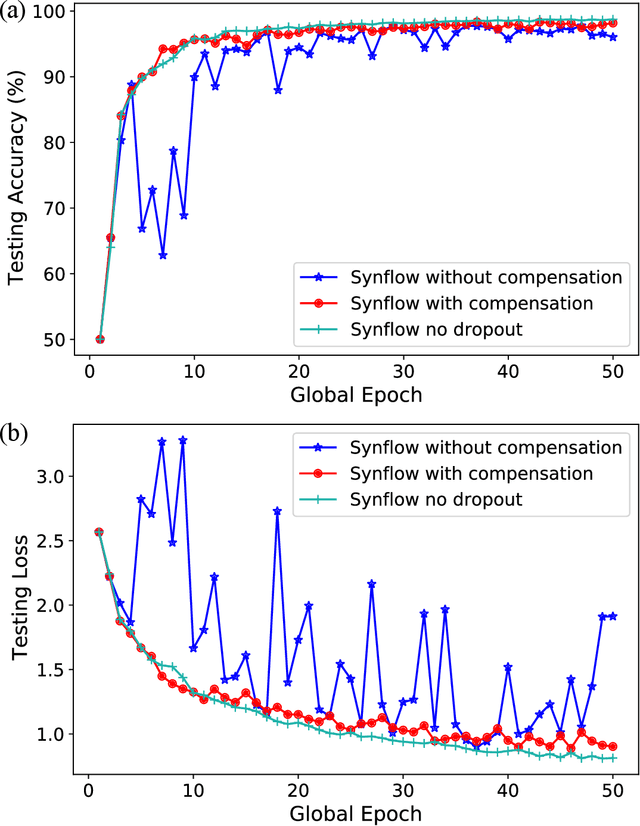
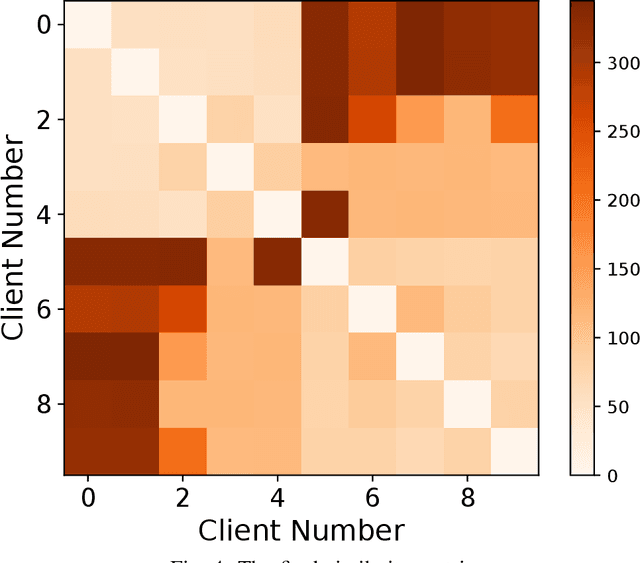
Federated learning (FL) enables edge devices to collaboratively learn a model in a distributed fashion. Many existing researches have focused on improving communication efficiency of high-dimensional models and addressing bias caused by local updates. However, most of FL algorithms are either based on reliable communications or assume fixed and known unreliability characteristics. In practice, networks could suffer from dynamic channel conditions and non-deterministic disruptions, with time-varying and unknown characteristics. To this end, in this paper we propose a sparsity enabled FL framework with both communication efficiency and bias reduction, termed as SAFARI. It makes novel use of a similarity among client models to rectify and compensate for bias that is resulted from unreliable communications. More precisely, sparse learning is implemented on local clients to mitigate communication overhead, while to cope with unreliable communications, a similarity-based compensation method is proposed to provide surrogates for missing model updates. We analyze SAFARI under bounded dissimilarity and with respect to sparse models. It is demonstrated that SAFARI under unreliable communications is guaranteed to converge at the same rate as the standard FedAvg with perfect communications. Implementations and evaluations on CIFAR-10 dataset validate the effectiveness of SAFARI by showing that it can achieve the same convergence speed and accuracy as FedAvg with perfect communications, with up to 80% of the model weights being pruned and a high percentage of client updates missing in each round.