 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Parameter Efficiency and Generalization in Large-Scale Models: A Regularized and Masked Low-Rank Adaptation Approach
Jul 16, 2024



Large pre-trained models, such as large language models (LLMs), present significant resource challenges for fine-tuning due to their extensive parameter sizes, especially for applications in mobile systems. To address this, Low-Rank Adaptation (LoRA) has been developed to reduce resource consumption while maintaining satisfactory fine-tuning results. Despite its effectiveness, the original LoRA method faces challenges of suboptimal performance and overfitting. This paper investigates the intrinsic dimension of the matrix updates approximated by the LoRA method and reveals the performance benefits of increasing this intrinsic dimension. By employing regularization and a gradient masking method that encourages higher intrinsic dimension, the proposed method, termed Regularized and Masked LoRA (RM-LoRA), achieves superior generalization performance with the same or lower trainable parameter budget compared to the original LoRA and its latest variants across various open-source vision and language datasets.
FL-TAC: Enhanced Fine-Tuning in Federated Learning via Low-Rank, Task-Specific Adapter Clustering
Apr 23, 2024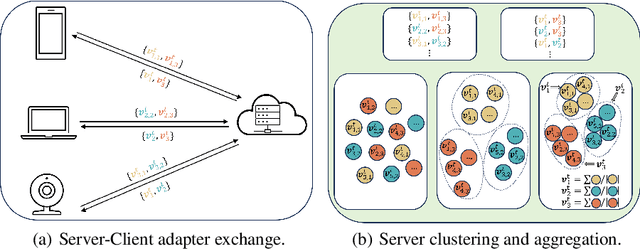

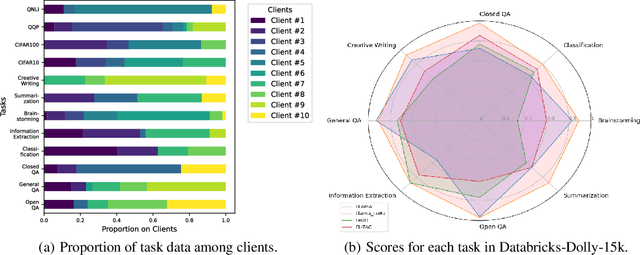
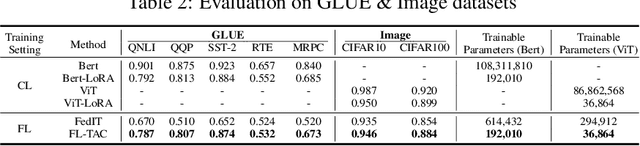
Although large-scale pre-trained models hold great potential for adapting to downstream tasks through fine-tuning, the performance of such fine-tuned models is often limited by the difficulty of collecting sufficient high-quality, task-specific data. Federated Learning (FL) offers a promising solution by enabling fine-tuning across large-scale clients with a variety of task data, but it is bottlenecked by significant communication overhead due to the pre-trained models' extensive size. This paper addresses the high communication cost for fine-tuning large pre-trained models within FL frameworks through low-rank fine-tuning. Specifically, we train a low-rank adapter for each individual task on the client side, followed by server-side clustering for similar group of adapters to achieve task-specific aggregation. Extensive experiments on various language and vision tasks, such as GLUE and CIFAR-10/100, reveal the evolution of task-specific adapters throughout the FL training process and verify the effectiveness of the proposed low-rank task-specific adapter clustering (TAC) method.
WSTac: Interactive Surface Perception based on Whisker-Inspired and Self-Illuminated Vision-Based Tactile Sensor
Aug 25, 2023



Modern Visual-Based Tactile Sensors (VBTSs) use cost-effective cameras to track elastomer deformation, but struggle with ambient light interference. Solutions typically involve using internal LEDs and blocking external light, thus adding complexity. Creating a VBTS resistant to ambient light with just a camera and an elastomer remains a challenge. In this work, we introduce WStac, a self-illuminating VBTS comprising a mechanoluminescence (ML) whisker elastomer, camera, and 3D printed parts. The ML whisker elastomer, inspired by the touch sensitivity of vibrissae, offers both light isolation and high ML intensity under stress, thereby removing the necessity for additional LED modules. With the incorporation of machine learning, the sensor effectively utilizes the dynamic contact variations of 25 whiskers to successfully perform tasks like speed regression, directional identification, and texture classification. Videos are available at: https://sites.google.com/view/wstac/.