 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFL-TAC: Enhanced Fine-Tuning in Federated Learning via Low-Rank, Task-Specific Adapter Clustering
Paper and Code
Apr 23, 2024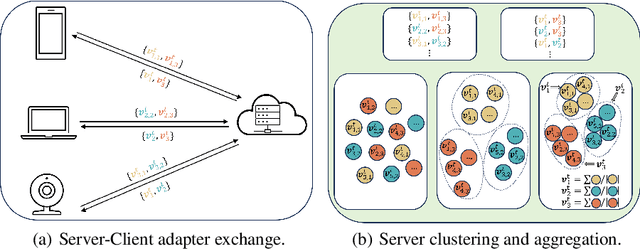

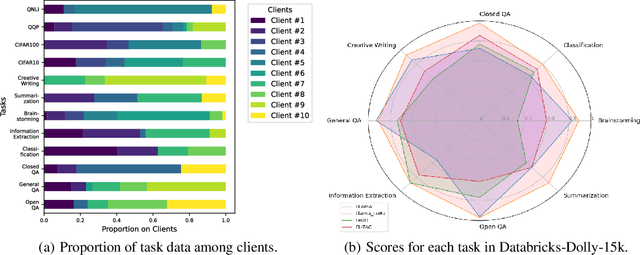
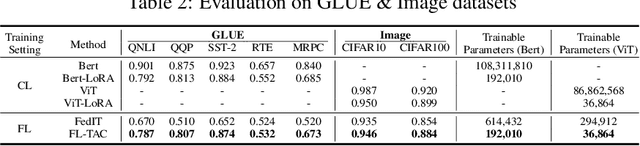
Although large-scale pre-trained models hold great potential for adapting to downstream tasks through fine-tuning, the performance of such fine-tuned models is often limited by the difficulty of collecting sufficient high-quality, task-specific data. Federated Learning (FL) offers a promising solution by enabling fine-tuning across large-scale clients with a variety of task data, but it is bottlenecked by significant communication overhead due to the pre-trained models' extensive size. This paper addresses the high communication cost for fine-tuning large pre-trained models within FL frameworks through low-rank fine-tuning. Specifically, we train a low-rank adapter for each individual task on the client side, followed by server-side clustering for similar group of adapters to achieve task-specific aggregation. Extensive experiments on various language and vision tasks, such as GLUE and CIFAR-10/100, reveal the evolution of task-specific adapters throughout the FL training process and verify the effectiveness of the proposed low-rank task-specific adapter clustering (TAC) method.