 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedHAP: Federated Hashing with Global Prototypes for Cross-silo Retrieval
Jul 12, 2022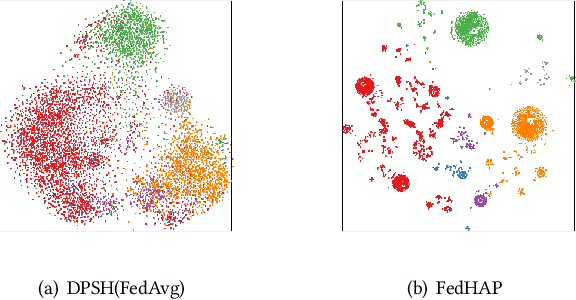
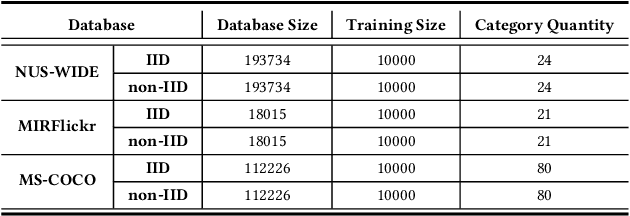
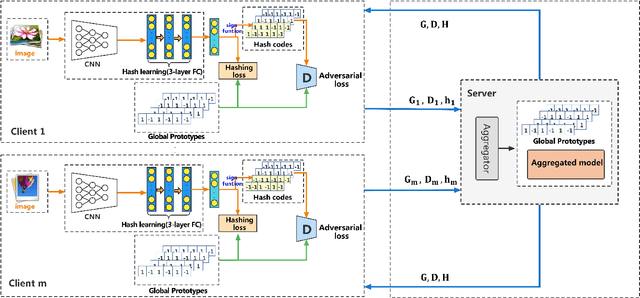
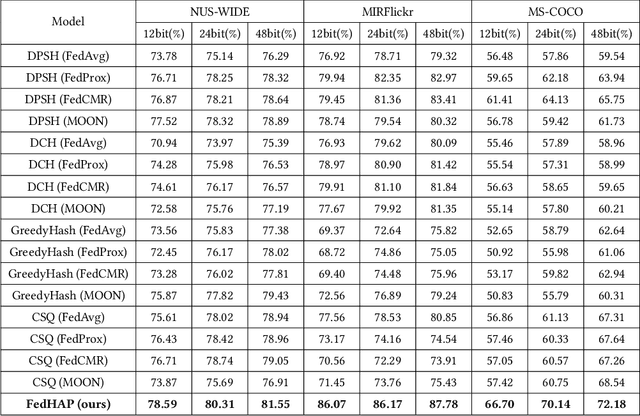
Deep hashing has been widely applied in large-scale data retrieval due to its superior retrieval efficiency and low storage cost. However, data are often scattered in data silos with privacy concerns, so performing centralized data storage and retrieval is not always possible. Leveraging the concept of federated learning (FL) to perform deep hashing is a recent research trend. However, existing frameworks mostly rely on the aggregation of the local deep hashing models, which are trained by performing similarity learning with local skewed data only. Therefore, they cannot work well for non-IID clients in a real federated environment. To overcome these challenges, we propose a novel federated hashing framework that enables participating clients to jointly train the shared deep hashing model by leveraging the prototypical hash codes for each class. Globally, the transmission of global prototypes with only one prototypical hash code per class will minimize the impact of communication cost and privacy risk. Locally, the use of global prototypes are maximized by jointly training a discriminator network and the local hashing network. Extensive experiments on benchmark datasets are conducted to demonstrate that our method can significantly improve the performance of the deep hashing model in the federated environments with non-IID data distributions.
SAFARI: Sparsity enabled Federated Learning with Limited and Unreliable Communications
Apr 05, 2022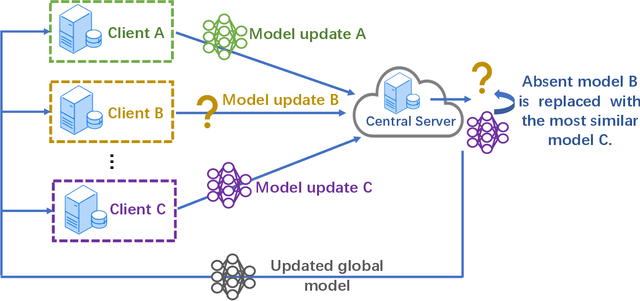
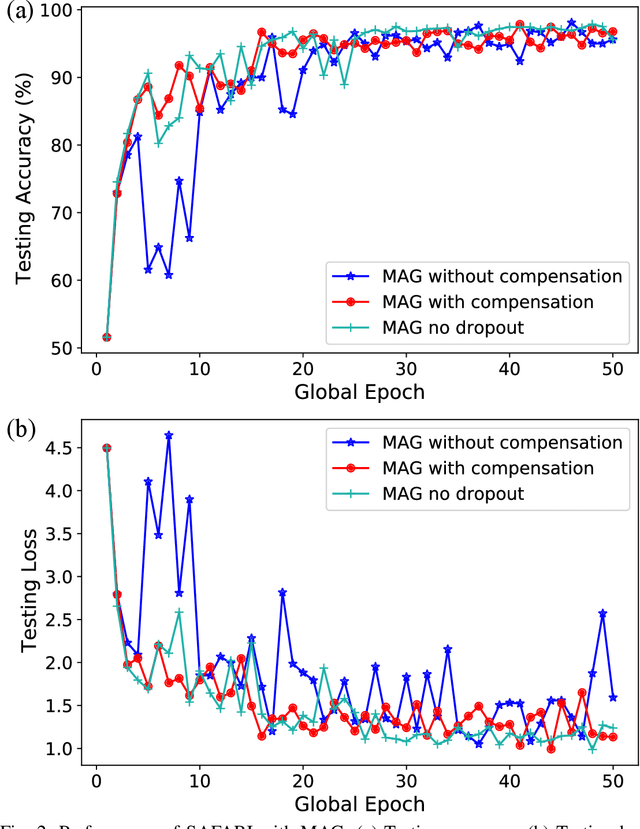
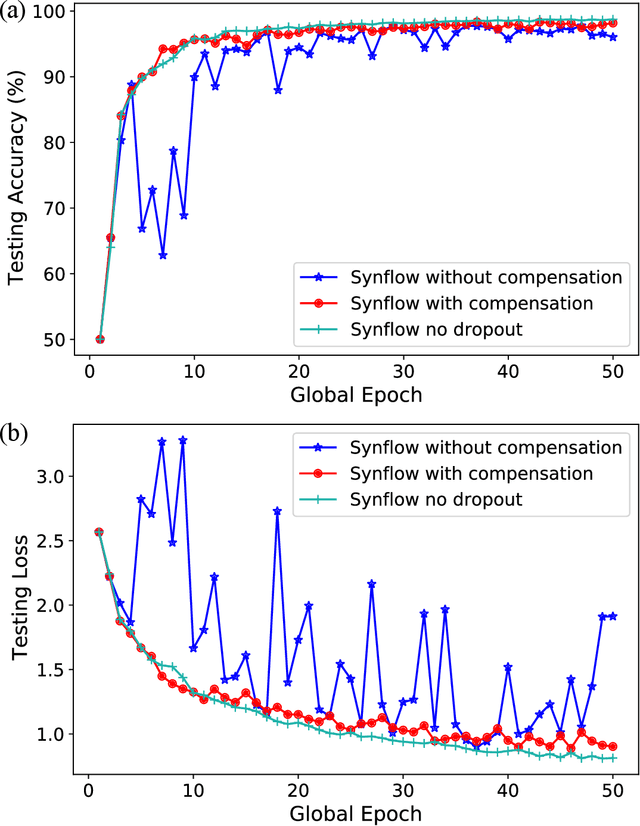
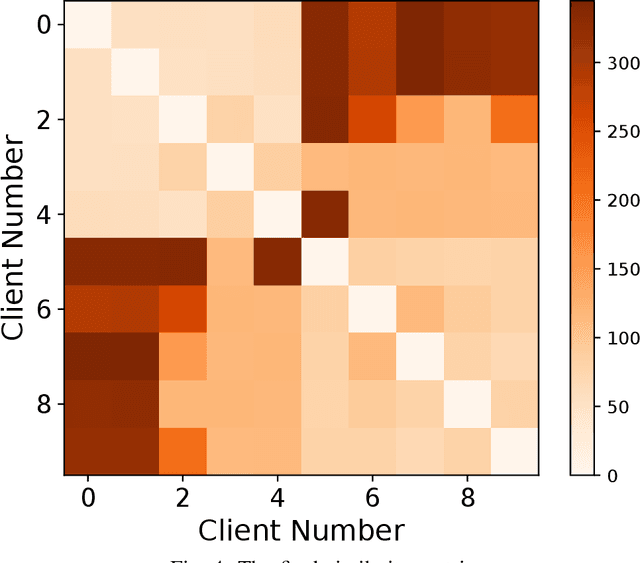
Federated learning (FL) enables edge devices to collaboratively learn a model in a distributed fashion. Many existing researches have focused on improving communication efficiency of high-dimensional models and addressing bias caused by local updates. However, most of FL algorithms are either based on reliable communications or assume fixed and known unreliability characteristics. In practice, networks could suffer from dynamic channel conditions and non-deterministic disruptions, with time-varying and unknown characteristics. To this end, in this paper we propose a sparsity enabled FL framework with both communication efficiency and bias reduction, termed as SAFARI. It makes novel use of a similarity among client models to rectify and compensate for bias that is resulted from unreliable communications. More precisely, sparse learning is implemented on local clients to mitigate communication overhead, while to cope with unreliable communications, a similarity-based compensation method is proposed to provide surrogates for missing model updates. We analyze SAFARI under bounded dissimilarity and with respect to sparse models. It is demonstrated that SAFARI under unreliable communications is guaranteed to converge at the same rate as the standard FedAvg with perfect communications. Implementations and evaluations on CIFAR-10 dataset validate the effectiveness of SAFARI by showing that it can achieve the same convergence speed and accuracy as FedAvg with perfect communications, with up to 80% of the model weights being pruned and a high percentage of client updates missing in each round.