 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning What and Where to Transfer
May 15, 2019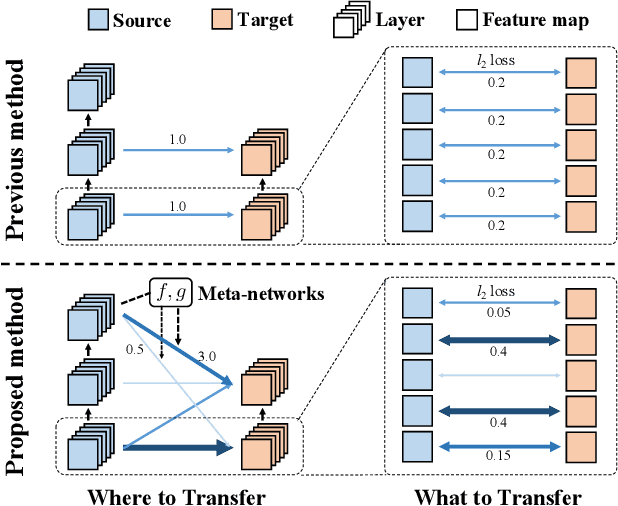
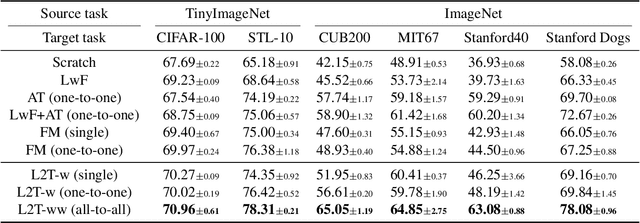
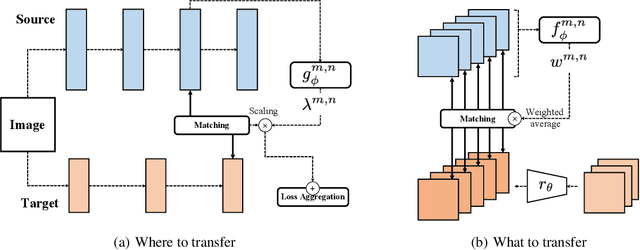

As the application of deep learning has expanded to real-world problems with insufficient volume of training data, transfer learning recently has gained much attention as means of improving the performance in such small-data regime. However, when existing methods are applied between heterogeneous architectures and tasks, it becomes more important to manage their detailed configurations and often requires exhaustive tuning on them for the desired performance. To address the issue, we propose a novel transfer learning approach based on meta-learning that can automatically learn what knowledge to transfer from the source network to where in the target network. Given source and target networks, we propose an efficient training scheme to learn meta-networks that decide (a) which pairs of layers between the source and target networks should be matched for knowledge transfer and (b) which features and how much knowledge from each feature should be transferred. We validate our meta-transfer approach against recent transfer learning methods on various datasets and network architectures, on which our automated scheme significantly outperforms the prior baselines that find "what and where to transfer" in a hand-crafted manner.
Iterative Bayesian Learning for Crowdsourced Regression
Oct 08, 2018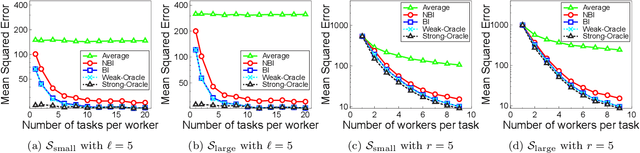

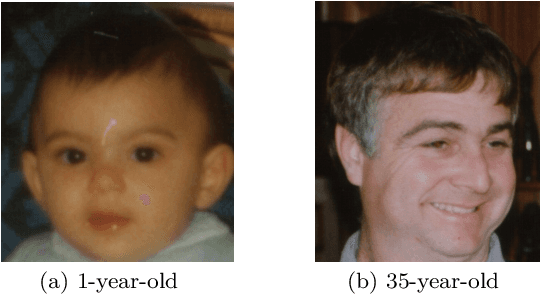
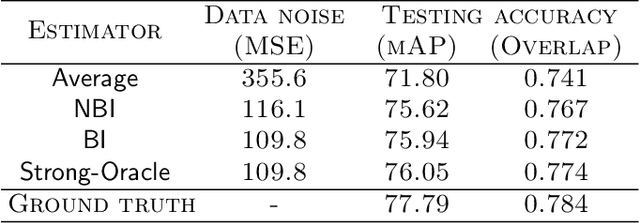
Crowdsourcing platforms emerged as popular venues for purchasing human intelligence at low cost for large volume of tasks. As many low-paid workers are prone to give noisy answers, a common practice is to add redundancy by assigning multiple workers to each task and then simply average out these answers. However, to fully harness the wisdom of the crowd, one needs to learn the heterogeneous quality of each worker. We resolve this fundamental challenge in crowdsourced regression tasks, i.e., the answer takes continuous labels, where identifying good or bad workers becomes much more non-trivial compared to a classification setting of discrete labels. In particular, we introduce a Bayesian iterative scheme and show that it provably achieves the optimal mean squared error. Our evaluations on synthetic and real-world datasets support our theoretical results and show the superiority of the proposed scheme.
Rapid Mixing Swendsen-Wang Sampler for Stochastic Partitioned Attractive Models
Apr 06, 2017
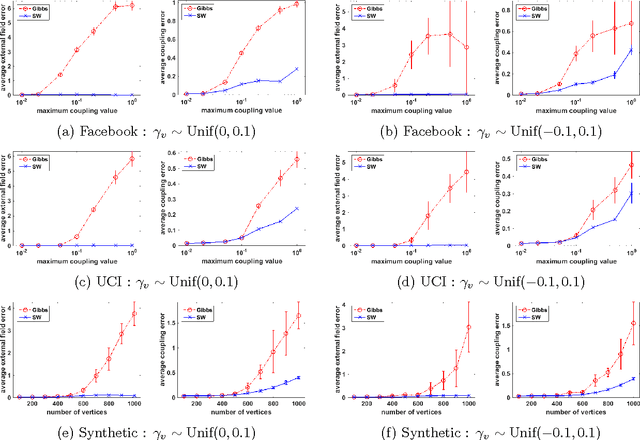
The Gibbs sampler is a particularly popular Markov chain used for learning and inference problems in Graphical Models (GMs). These tasks are computationally intractable in general, and the Gibbs sampler often suffers from slow mixing. In this paper, we study the Swendsen-Wang dynamics which is a more sophisticated Markov chain designed to overcome bottlenecks that impede the Gibbs sampler. We prove O(\log n) mixing time for attractive binary pairwise GMs (i.e., ferromagnetic Ising models) on stochastic partitioned graphs having n vertices, under some mild conditions, including low temperature regions where the Gibbs sampler provably mixes exponentially slow. Our experiments also confirm that the Swendsen-Wang sampler significantly outperforms the Gibbs sampler when they are used for learning parameters of attractive GMs.