 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMHSCNet: A Multimodal Hierarchical Shot-aware Convolutional Network for Video Summarization
Apr 19, 2022

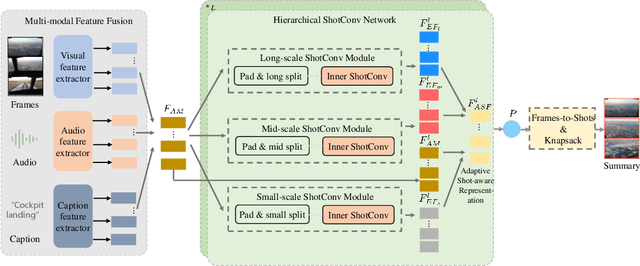

Video summarization intends to produce a concise video summary by effectively capturing and combining the most informative parts of the whole content. Existing approaches for video summarization regard the task as a frame-wise keyframe selection problem and generally construct the frame-wise representation by combining the long-range temporal dependency with the unimodal or bimodal information. However, the optimal video summaries need to reflect the most valuable keyframe with its own information, and one with semantic power of the whole content. Thus, it is critical to construct a more powerful and robust frame-wise representation and predict the frame-level importance score in a fair and comprehensive manner. To tackle the above issues, we propose a multimodal hierarchical shot-aware convolutional network, denoted as MHSCNet, to enhance the frame-wise representation via combining the comprehensive available multimodal information. Specifically, we design a hierarchical ShotConv network to incorporate the adaptive shot-aware frame-level representation by considering the short-range and long-range temporal dependency. Based on the learned shot-aware representations, MHSCNet can predict the frame-level importance score in the local and global view of the video. Extensive experiments on two standard video summarization datasets demonstrate that our proposed method consistently outperforms state-of-the-art baselines. Source code will be made publicly available.
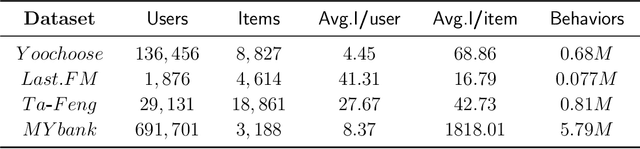
HCGR: Hyperbolic Contrastive Graph Representation Learning for Session-based Recommendation
Jul 06, 2021

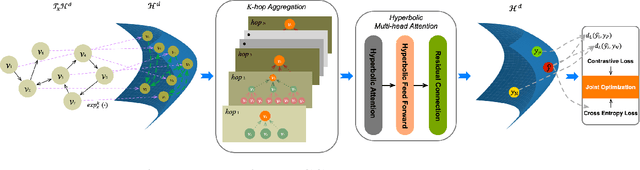
Session-based recommendation (SBR) learns users' preferences by capturing the short-term and sequential patterns from the evolution of user behaviors. Among the studies in the SBR field, graph-based approaches are a relatively powerful kind of way, which generally extract item information by message aggregation under Euclidean space. However, such methods can't effectively extract the hierarchical information contained among consecutive items in a session, which is critical to represent users' preferences. In this paper, we present a hyperbolic contrastive graph recommender (HCGR), a principled session-based recommendation framework involving Lorentz hyperbolic space to adequately capture the coherence and hierarchical representations of the items. Within this framework, we design a novel adaptive hyperbolic attention computation to aggregate the graph message of each user's preference in a session-based behavior sequence. In addition, contrastive learning is leveraged to optimize the item representation by considering the geodesic distance between positive and negative samples in hyperbolic space. Extensive experiments on four real-world datasets demonstrate that HCGR consistently outperforms state-of-the-art baselines by 0.43$\%$-28.84$\%$ in terms of $HitRate$, $NDCG$ and $MRR$.