 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHi-Gen: Generative Retrieval For Large-Scale Personalized E-commerce Search
Apr 24, 2024Leveraging generative retrieval (GR) techniques to enhance search systems is an emerging methodology that has shown promising results in recent years. In GR, a text-to-text model maps string queries directly to relevant document identifiers (docIDs), so it dramatically simplifies the whole retrieval process. However, when applying most GR models in large-scale E-commerce for personalized item search, we have to face two key problems in encoding and decoding. (1) Existing docID generation methods ignore the encoding of efficiency information, which is critical in E-commerce. (2) The positional information is important in decoding docIDs, while prior studies have not adequately discriminated the significance of positional information or well exploited the inherent interrelation among these positions. To overcome these problems, we introduce an efficient Hierarchical encoding-decoding Generative retrieval method (Hi-Gen) for large-scale personalized E-commerce search systems. Specifically, we first design a representation learning model along with metric learning to learn discriminative feature representations of items to capture both semantic relevance and efficiency information. Then, we propose a category-guided hierarchical clustering scheme that makes full use of the semantic and efficiency information of items to facilitate docID generation. Finally, we design a position-aware loss to discriminate the importance of positions and mine the inherent interrelation between different tokens at the same position. This loss boosts the performance of the language model used in the decoding stage. Besides, we propose two variants of Hi-Gen (i.e.,Hi-Gen-I2I and Hi-Gen-Cluster) to support online real-time large-scale recall in the online serving process. Extensive experiments on both public and industry datasets demonstrate the effectiveness and efficiency of Hi-Gen.
Reinforcement-Learning based Portfolio Management with Augmented Asset Movement Prediction States
Feb 09, 2020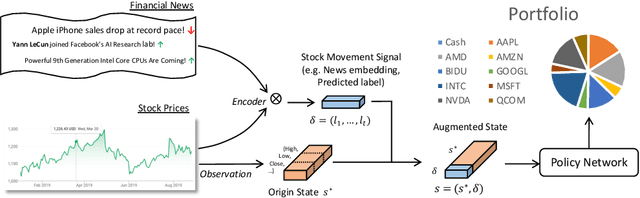

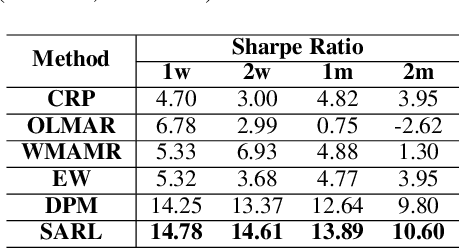
Portfolio management (PM) is a fundamental financial planning task that aims to achieve investment goals such as maximal profits or minimal risks. Its decision process involves continuous derivation of valuable information from various data sources and sequential decision optimization, which is a prospective research direction for reinforcement learning (RL). In this paper, we propose SARL, a novel State-Augmented RL framework for PM. Our framework aims to address two unique challenges in financial PM: (1) data heterogeneity -- the collected information for each asset is usually diverse, noisy and imbalanced (e.g., news articles); and (2) environment uncertainty -- the financial market is versatile and non-stationary. To incorporate heterogeneous data and enhance robustness against environment uncertainty, our SARL augments the asset information with their price movement prediction as additional states, where the prediction can be solely based on financial data (e.g., asset prices) or derived from alternative sources such as news. Experiments on two real-world datasets, (i) Bitcoin market and (ii) HighTech stock market with 7-year Reuters news articles, validate the effectiveness of SARL over existing PM approaches, both in terms of accumulated profits and risk-adjusted profits. Moreover, extensive simulations are conducted to demonstrate the importance of our proposed state augmentation, providing new insights and boosting performance significantly over standard RL-based PM method and other baselines.
Video Question Answering via Attribute-Augmented Attention Network Learning
Jul 20, 2017

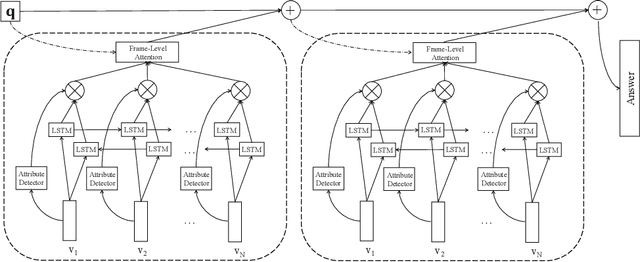
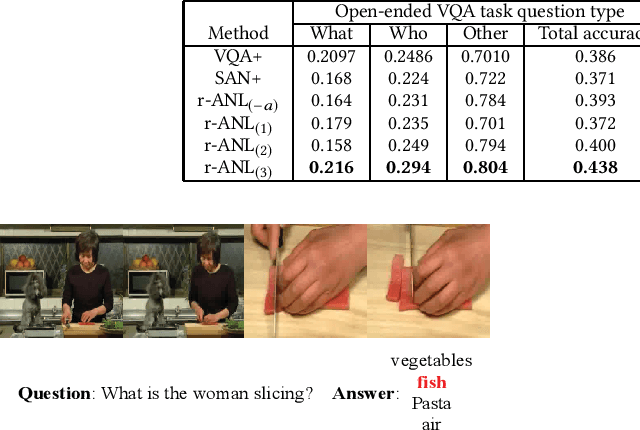
Video Question Answering is a challenging problem in visual information retrieval, which provides the answer to the referenced video content according to the question. However, the existing visual question answering approaches mainly tackle the problem of static image question, which may be ineffectively for video question answering due to the insufficiency of modeling the temporal dynamics of video contents. In this paper, we study the problem of video question answering by modeling its temporal dynamics with frame-level attention mechanism. We propose the attribute-augmented attention network learning framework that enables the joint frame-level attribute detection and unified video representation learning for video question answering. We then incorporate the multi-step reasoning process for our proposed attention network to further improve the performance. We construct a large-scale video question answering dataset. We conduct the experiments on both multiple-choice and open-ended video question answering tasks to show the effectiveness of the proposed method.