 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Stability of GNN Force Field Models by Reducing Feature Correlation
Feb 18, 2025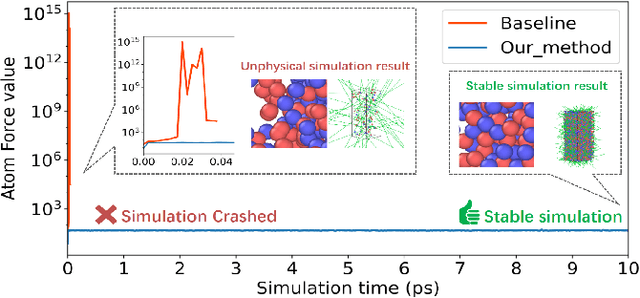
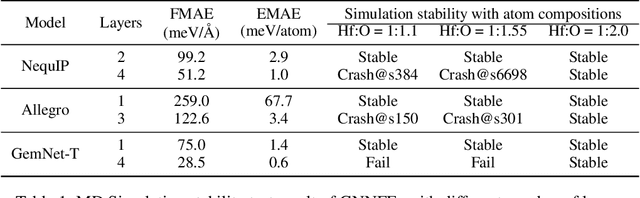
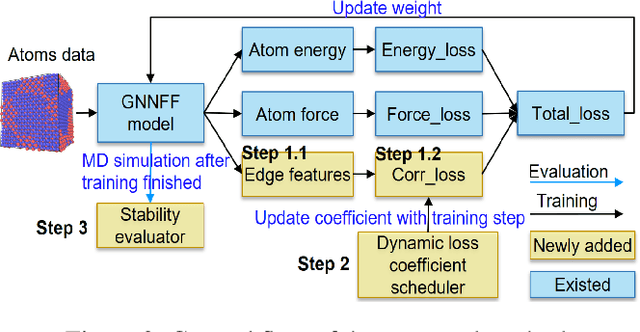
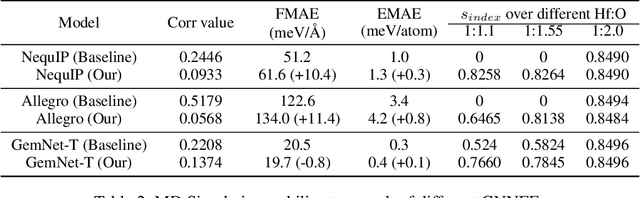
Recently, Graph Neural Network based Force Field (GNNFF) models are widely used in Molecular Dynamics (MD) simulation, which is one of the most cost-effective means in semiconductor material research. However, even such models provide high accuracy in energy and force Mean Absolute Error (MAE) over trained (in-distribution) datasets, they often become unstable during long-time MD simulation when used for out-of-distribution datasets. In this paper, we propose a feature correlation based method for GNNFF models to enhance the stability of MD simulation. We reveal the negative relationship between feature correlation and the stability of GNNFF models, and design a loss function with a dynamic loss coefficient scheduler to reduce edge feature correlation that can be applied in general GNNFF training. We also propose an empirical metric to evaluate the stability in MD simulation. Experiments show our method can significantly improve stability for GNNFF models especially in out-of-distribution data with less than 3% computational overhead. For example, we can ensure the stable MD simulation time from 0.03ps to 10ps for Allegro model.
Parallel Proportional Fusion of Spiking Quantum Neural Network for Optimizing Image Classification
Apr 01, 2024The recent emergence of the hybrid quantum-classical neural network (HQCNN) architecture has garnered considerable attention due to the potential advantages associated with integrating quantum principles to enhance various facets of machine learning algorithms and computations. However, the current investigated serial structure of HQCNN, wherein information sequentially passes from one network to another, often imposes limitations on the trainability and expressivity of the network. In this study, we introduce a novel architecture termed Parallel Proportional Fusion of Quantum and Spiking Neural Networks (PPF-QSNN). The dataset information is simultaneously fed into both the spiking neural network and the variational quantum circuits, with the outputs amalgamated in proportion to their individual contributions. We systematically assess the impact of diverse PPF-QSNN parameters on network performance for image classification, aiming to identify the optimal configuration. Numerical results on the MNIST dataset unequivocally illustrate that our proposed PPF-QSNN outperforms both the existing spiking neural network and the serial quantum neural network across metrics such as accuracy, loss, and robustness. This study introduces a novel and effective amalgamation approach for HQCNN, thereby laying the groundwork for the advancement and application of quantum advantage in artificial intelligent computations.
Breaking MLPerf Training: A Case Study on Optimizing BERT
Feb 04, 2024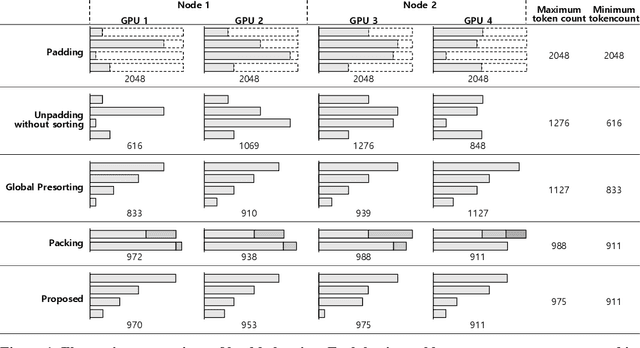
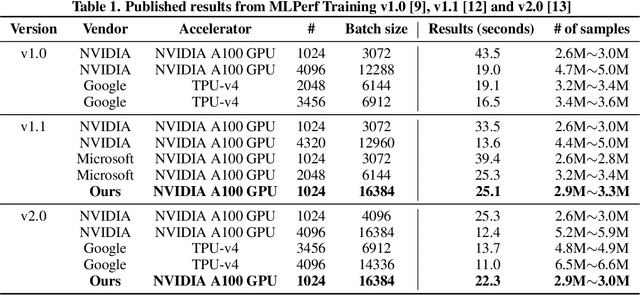
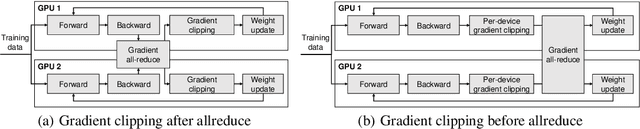
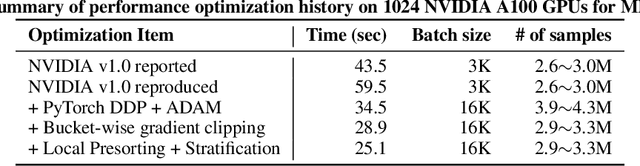
Speeding up the large-scale distributed training is challenging in that it requires improving various components of training including load balancing, communication, optimizers, etc. We present novel approaches for fast large-scale training of BERT model which individually ameliorates each component thereby leading to a new level of BERT training performance. Load balancing is imperative in distributed BERT training since its training datasets are characterized by samples with various lengths. Communication cost, which is proportional to the scale of distributed training, needs to be hidden by useful computation. In addition, the optimizers, e.g., ADAM, LAMB, etc., need to be carefully re-evaluated in the context of large-scale distributed training. We propose two new ideas, (1) local presorting based on dataset stratification for load balancing and (2) bucket-wise gradient clipping before allreduce which allows us to benefit from the overlap of gradient computation and synchronization as well as the fast training of gradient clipping before allreduce. We also re-evaluate existing optimizers via hyperparameter optimization and utilize ADAM, which also contributes to fast training via larger batches than existing methods. Our proposed methods, all combined, give the fastest MLPerf BERT training of 25.1 (22.3) seconds on 1,024 NVIDIA A100 GPUs, which is 1.33x (1.13x) and 1.57x faster than the other top two (one) submissions to MLPerf v1.1 (v2.0). Our implementation and evaluation results are available at MLPerf v1.1~v2.1.