 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Stability of GNN Force Field Models by Reducing Feature Correlation
Feb 18, 2025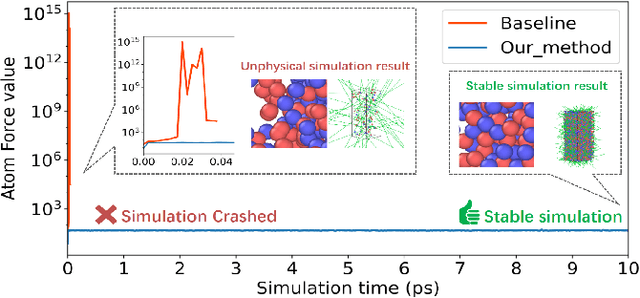
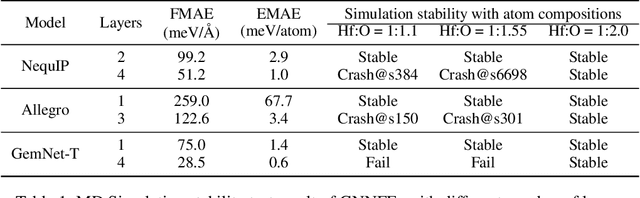
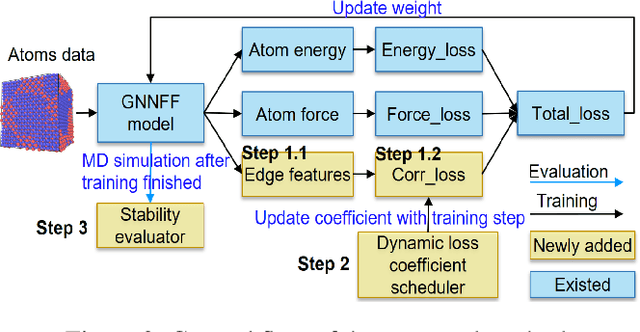
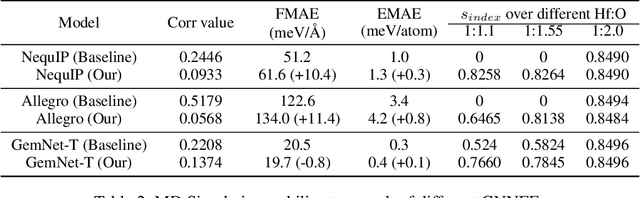
Recently, Graph Neural Network based Force Field (GNNFF) models are widely used in Molecular Dynamics (MD) simulation, which is one of the most cost-effective means in semiconductor material research. However, even such models provide high accuracy in energy and force Mean Absolute Error (MAE) over trained (in-distribution) datasets, they often become unstable during long-time MD simulation when used for out-of-distribution datasets. In this paper, we propose a feature correlation based method for GNNFF models to enhance the stability of MD simulation. We reveal the negative relationship between feature correlation and the stability of GNNFF models, and design a loss function with a dynamic loss coefficient scheduler to reduce edge feature correlation that can be applied in general GNNFF training. We also propose an empirical metric to evaluate the stability in MD simulation. Experiments show our method can significantly improve stability for GNNFF models especially in out-of-distribution data with less than 3% computational overhead. For example, we can ensure the stable MD simulation time from 0.03ps to 10ps for Allegro model.
Efficient Softmax Approximation for Deep Neural Networks with Attention Mechanism
Nov 21, 2021
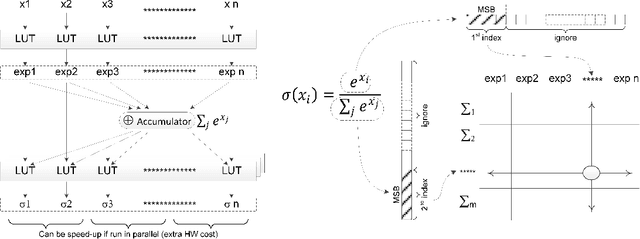
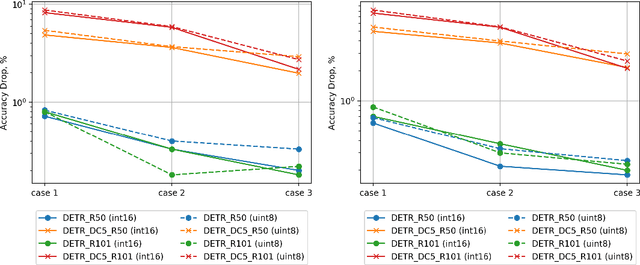
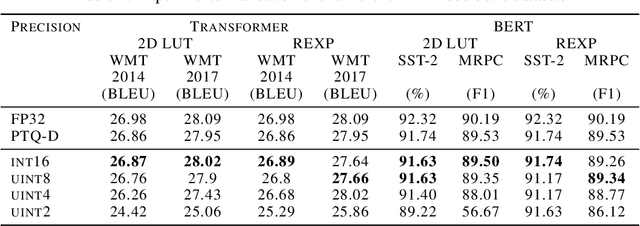
There has been a rapid advance of custom hardware (HW) for accelerating the inference speed of deep neural networks (DNNs). Previously, the softmax layer was not a main concern of DNN accelerating HW, because its portion is relatively small in multi-layer perceptron or convolutional neural networks. However, as the attention mechanisms are widely used in various modern DNNs, a cost-efficient implementation of softmax layer is becoming very important. In this paper, we propose two methods to approximate softmax computation, which are based on the usage of LookUp Tables (LUTs). The required size of LUT is quite small (about 700 Bytes) because ranges of numerators and denominators of softmax are stable if normalization is applied to the input. We have validated the proposed technique over different AI tasks (object detection, machine translation, sentiment analysis, and semantic equivalence) and DNN models (DETR, Transformer, BERT) by a variety of benchmarks (COCO17, WMT14, WMT17, GLUE). We showed that 8-bit approximation allows to obtain acceptable accuracy loss below $1.0\%$.