 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-Robust Radio Frequency Fingerprint Identification Using Denoise Diffusion Model
Mar 07, 2025Securing Internet of Things (IoT) devices presents increasing challenges due to their limited computational and energy resources. Radio Frequency Fingerprint Identification (RFFI) emerges as a promising authentication technique to identify wireless devices through hardware impairments. RFFI performance under low signal-to-noise ratio (SNR) scenarios is significantly degraded because the minute hardware features can be easily swamped in noise. In this paper, we leveraged the diffusion model to effectively restore the RFF under low SNR scenarios. Specifically, we trained a powerful noise predictor and tailored a noise removal algorithm to effectively reduce the noise level in the received signal and restore the device fingerprints. We used Wi-Fi as a case study and created a testbed involving 6 commercial off-the-shelf Wi-Fi dongles and a USRP N210 software-defined radio (SDR) platform. We conducted experimental evaluations on various SNR scenarios. The experimental results show that the proposed algorithm can improve the classification accuracy by up to 34.9%.
Towards Collaborative Anti-Money Laundering Among Financial Institutions
Feb 27, 2025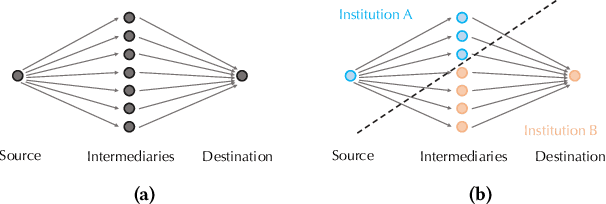
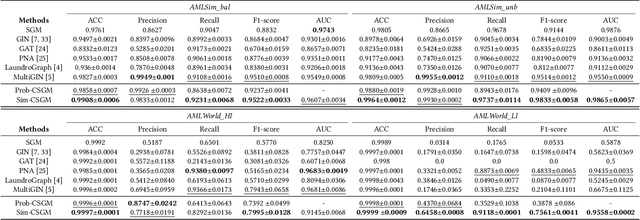
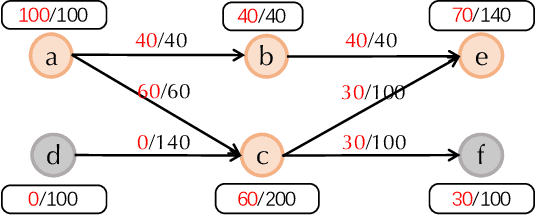

Money laundering is the process that intends to legalize the income derived from illicit activities, thus facilitating their entry into the monetary flow of the economy without jeopardizing their source. It is crucial to identify such activities accurately and reliably in order to enforce anti-money laundering (AML). Despite considerable efforts to AML, a large number of such activities still go undetected. Rule-based methods were first introduced and are still widely used in current detection systems. With the rise of machine learning, graph-based learning methods have gained prominence in detecting illicit accounts through the analysis of money transfer graphs. Nevertheless, these methods generally assume that the transaction graph is centralized, whereas in practice, money laundering activities usually span multiple financial institutions. Due to regulatory, legal, commercial, and customer privacy concerns, institutions tend not to share data, restricting their utility in practical usage. In this paper, we propose the first algorithm that supports performing AML over multiple institutions while protecting the security and privacy of local data. To evaluate, we construct Alipay-ECB, a real-world dataset comprising digital transactions from Alipay, the world's largest mobile payment platform, alongside transactions from E-Commerce Bank (ECB). The dataset includes over 200 million accounts and 300 million transactions, covering both intra-institution transactions and those between Alipay and ECB. This makes it the largest real-world transaction graph available for analysis. The experimental results demonstrate that our methods can effectively identify cross-institution money laundering subgroups. Additionally, experiments on synthetic datasets also demonstrate that our method is efficient, requiring only a few minutes on datasets with millions of transactions.
DSRRTracker: Dynamic Search Region Refinement for Attention-based Siamese Multi-Object Tracking
Mar 21, 2022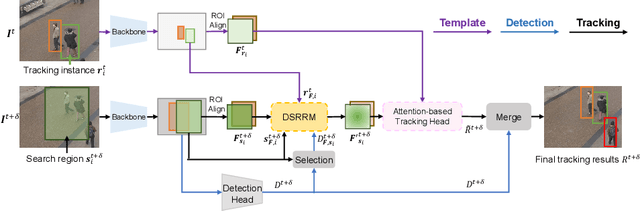
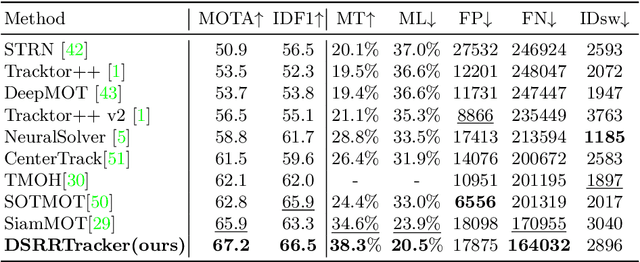
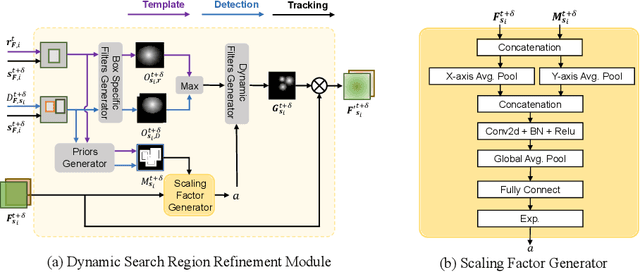
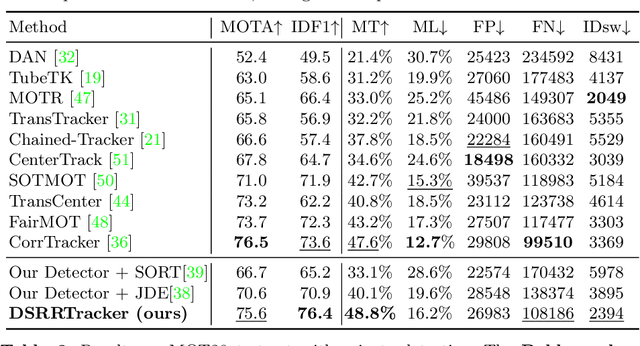
Many multi-object tracking (MOT) methods follow the framework of "tracking by detection", which associates the target objects-of-interest based on the detection results. However, due to the separate models for detection and association, the tracking results are not optimal.Moreover, the speed is limited by some cumbersome association methods to achieve high tracking performance. In this work, we propose an end-to-end MOT method, with a Gaussian filter-inspired dynamic search region refinement module to dynamically filter and refine the search region by considering both the template information from the past frames and the detection results from the current frame with little computational burden, and a lightweight attention-based tracking head to achieve the effective fine-grained instance association. Extensive experiments and ablation study on MOT17 and MOT20 datasets demonstrate that our method can achieve the state-of-the-art performance with reasonable speed.
"Adversarial Examples" for Proof-of-Learning
Aug 25, 2021
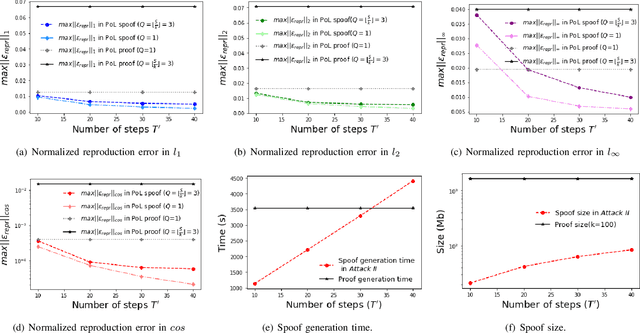
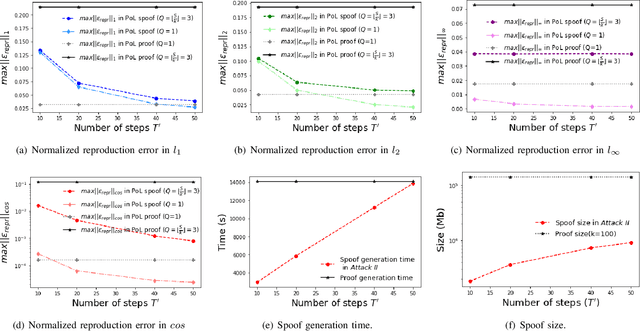
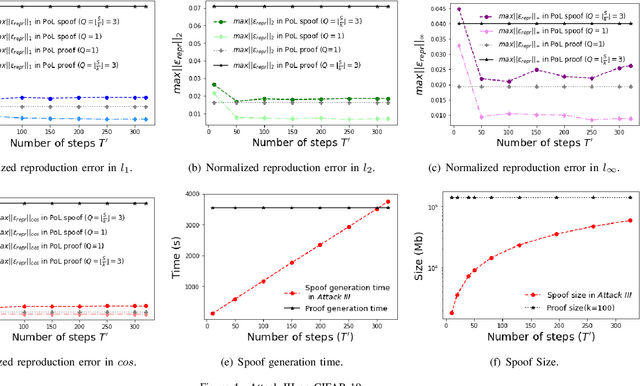
In S&P '21, Jia et al. proposed a new concept/mechanism named proof-of-learning (PoL), which allows a prover to demonstrate ownership of a machine learning model by proving integrity of the training procedure. It guarantees that an adversary cannot construct a valid proof with less cost (in both computation and storage) than that made by the prover in generating the proof. A PoL proof includes a set of intermediate models recorded during training, together with the corresponding data points used to obtain each recorded model. Jia et al. claimed that an adversary merely knowing the final model and training dataset cannot efficiently find a set of intermediate models with correct data points. In this paper, however, we show that PoL is vulnerable to "adversarial examples"! Specifically, in a similar way as optimizing an adversarial example, we could make an arbitrarily-chosen data point "generate" a given model, hence efficiently generating intermediate models with correct data points. We demonstrate, both theoretically and empirically, that we are able to generate a valid proof with significantly less cost than generating a proof by the prover, thereby we successfully break PoL.