 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Robot Navigation with Adaptive ExecutionDuration (AED) in a Semi-Markov Model
Aug 30, 2021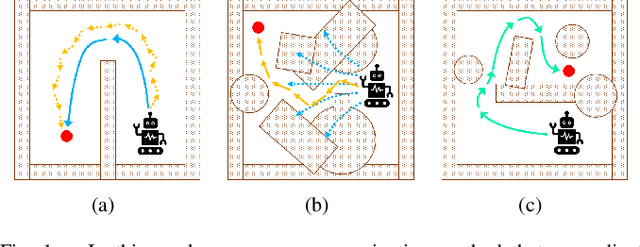
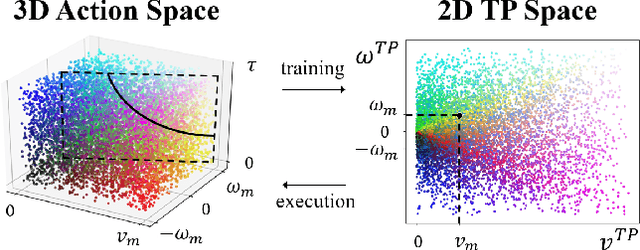
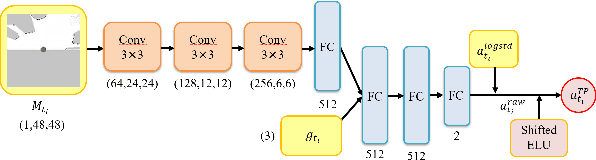
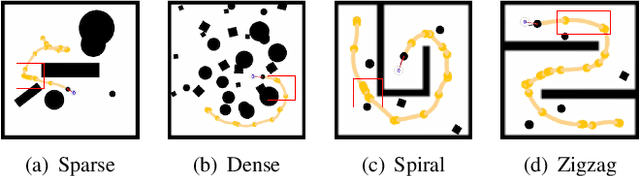
Deep reinforcement learning (DRL) algorithms have proven effective in robot navigation, especially in unknown environments, through directly mapping perception inputs into robot control commands. Most existing methods adopt uniform execution duration with robots taking commands at fixed intervals. As such, the length of execution duration becomes a crucial parameter to the navigation algorithm. In particular, if the duration is too short, then the navigation policy would be executed at a high frequency, with increased training difficulty and high computational cost. Meanwhile, if the duration is too long, then the policy becomes unable to handle complex situations, like those with crowded obstacles. It is thus tricky to find the "sweet" duration range; some duration values may render a DRL model to fail to find a navigation path. In this paper, we propose to employ adaptive execution duration to overcome this problem. Specifically, we formulate the navigation task as a Semi-Markov Decision Process (SMDP) problem to handle adaptive execution duration. We also improve the distributed proximal policy optimization (DPPO) algorithm and provide its theoretical guarantee for the specified SMDP problem. We evaluate our approach both in the simulator and on an actual robot. The results show that our approach outperforms the other DRL-based method (with fixed execution duration) by 10.3% in terms of the navigation success rate.
DRQN-based 3D Obstacle Avoidance with a Limited Field of View
Aug 12, 2021
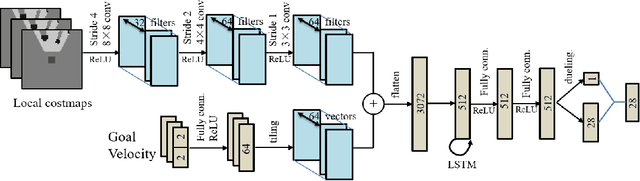
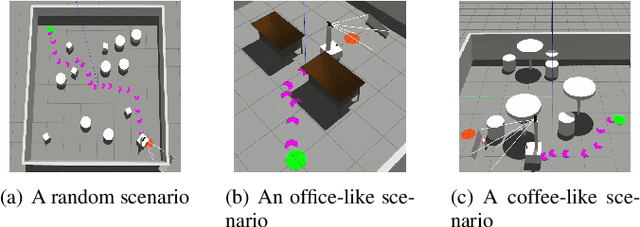
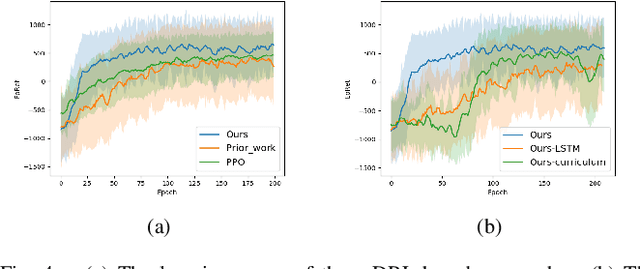
In this paper, we propose a map-based end-to-end DRL approach for three-dimensional (3D) obstacle avoidance in a partially observed environment, which is applied to achieve autonomous navigation for an indoor mobile robot using a depth camera with a narrow field of view. We first train a neural network with LSTM units in a 3D simulator of mobile robots to approximate the Q-value function in double DRQN. We also use a curriculum learning strategy to accelerate and stabilize the training process. Then we deploy the trained model to a real robot to perform 3D obstacle avoidance in its navigation. We evaluate the proposed approach both in the simulated environment and on a robot in the real world. The experimental results show that the approach is efficient and easy to be deployed, and it performs well for 3D obstacle avoidance with a narrow observation angle, which outperforms other existing DRL-based models by 15.5% on success rate.
Robot Navigation with Map-Based Deep Reinforcement Learning
Feb 11, 2020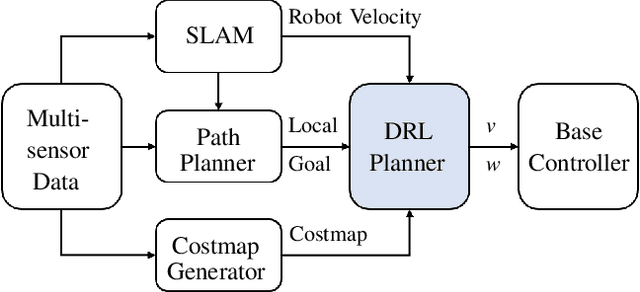
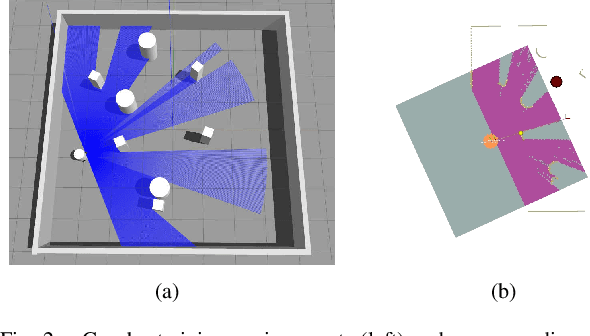
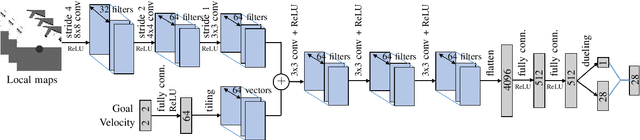
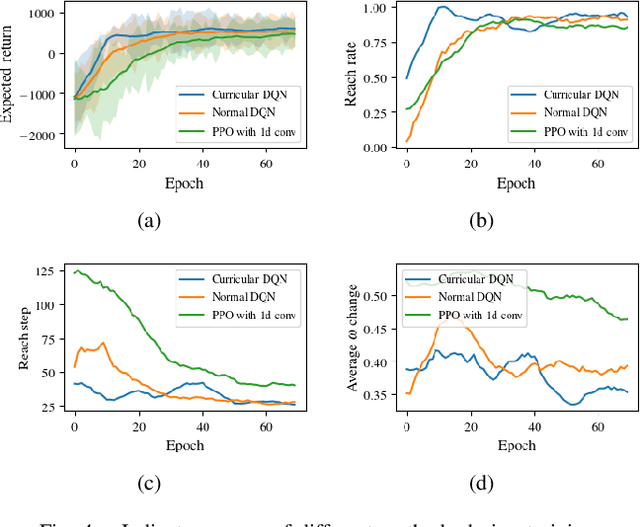
This paper proposes an end-to-end deep reinforcement learning approach for mobile robot navigation with dynamic obstacles avoidance. Using experience collected in a simulation environment, a convolutional neural network (CNN) is trained to predict proper steering actions of a robot from its egocentric local occupancy maps, which accommodate various sensors and fusion algorithms. The trained neural network is then transferred and executed on a real-world mobile robot to guide its local path planning. The new approach is evaluated both qualitatively and quantitatively in simulation and real-world robot experiments. The results show that the map-based end-to-end navigation model is easy to be deployed to a robotic platform, robust to sensor noise and outperforms other existing DRL-based models in many indicators.