 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Unsupervised Deep Unfolding Framework for robust Symbol Level Precoding
Nov 15, 2021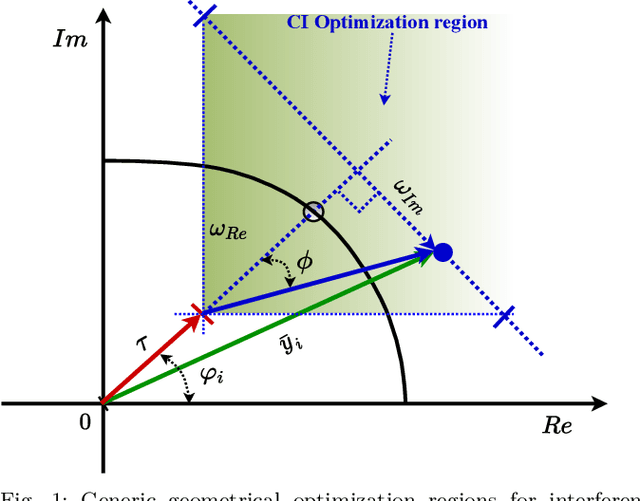
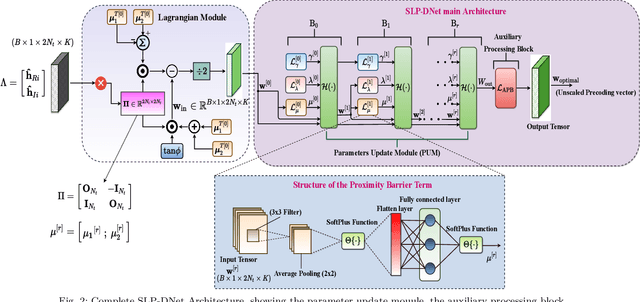
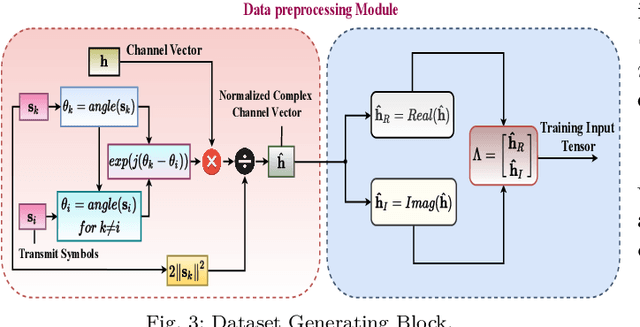
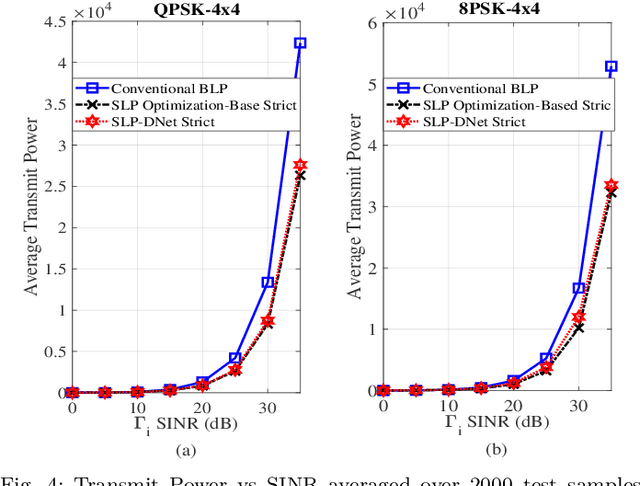
Symbol Level Precoding (SLP) has attracted significant research interest due to its ability to exploit interference for energy-efficient transmission. This paper proposes an unsupervised deep-neural network (DNN) based SLP framework. Instead of naively training a DNN architecture for SLP without considering the specifics of the optimization objective of the SLP domain, our proposal unfolds a power minimization SLP formulation based on the interior point method (IPM) proximal `log' barrier function. Furthermore, we extend our proposal to a robust precoding design under channel state information (CSI) uncertainty. The results show that our proposed learning framework provides near-optimal performance while reducing the computational cost from O(n7.5) to O(n3) for the symmetrical system case where n = number of transmit antennas = number of users. This significant complexity reduction is also reflected in a proportional decrease in the proposed approach's execution time compared to the SLP optimization-based solution.
Learning-Based Symbol Level Precoding: A Memory-Efficient Unsupervised Learning Approach
Nov 15, 2021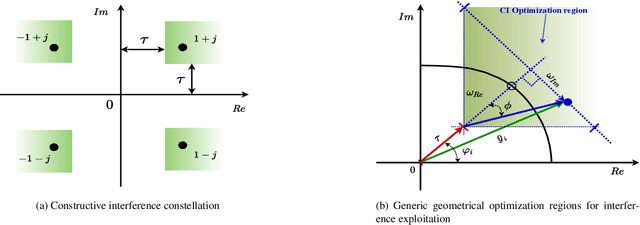
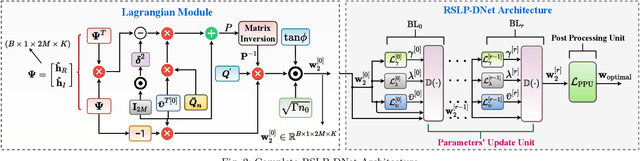
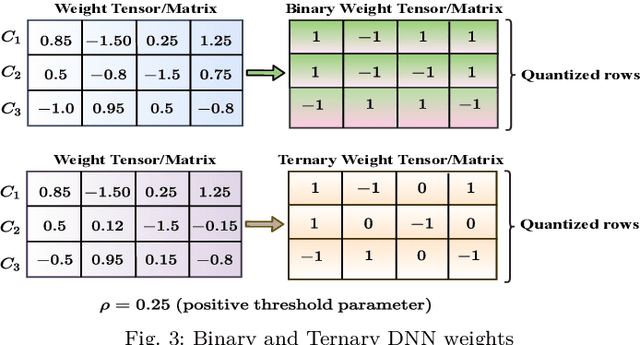
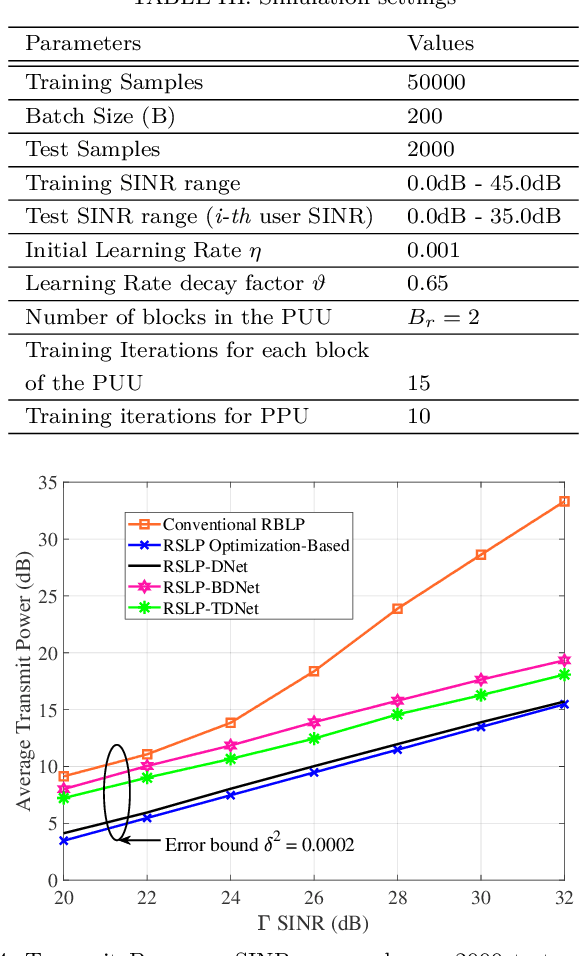
Symbol level precoding (SLP) has been proven to be an effective means of managing the interference in a multiuser downlink transmission and also enhancing the received signal power. This paper proposes an unsupervised learning based SLP that applies to quantized deep neural networks (DNNs). Rather than simply training a DNN in a supervised mode, our proposal unfolds a power minimization SLP formulation in an imperfect channel scenario using the interior point method (IPM) proximal `log' barrier function. We use binary and ternary quantizations to compress the DNN's weight values. The results show significant memory savings for our proposals compared to the existing full-precision SLP-DNet with significant model compression of ~21x and ~13x for both binary DNN-based SLP (RSLP-BDNet) and ternary DNN-based SLP (RSLP-TDNets), respectively.
A Memory-Efficient Learning Framework for SymbolLevel Precoding with Quantized NN Weights
Oct 13, 2021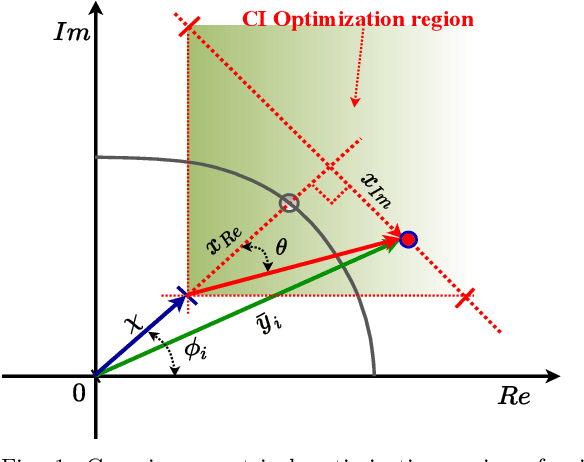
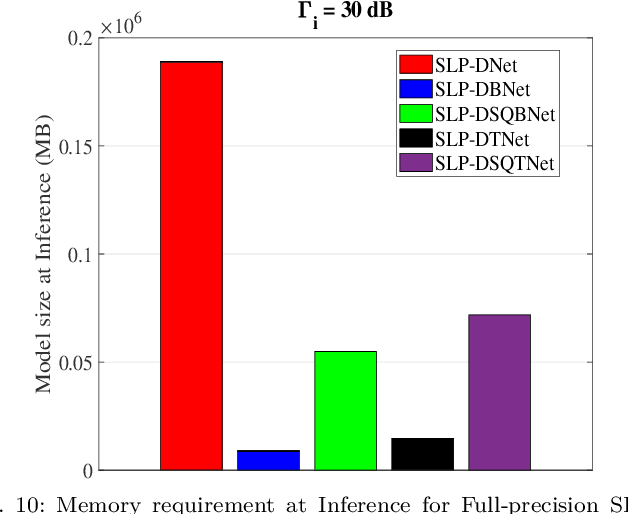
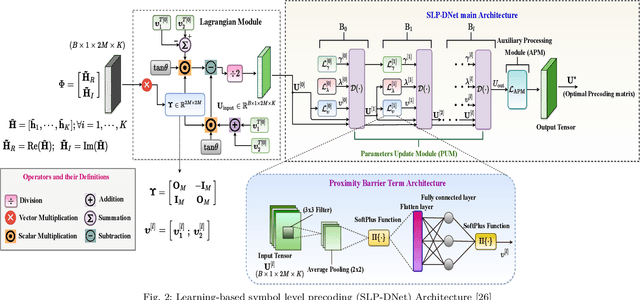
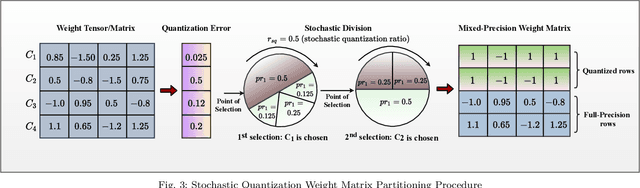
This paper proposes a memory-efficient deep neural network (DNN) framework-based symbol level precoding (SLP). We focus on a DNN with realistic finite precision weights and adopt an unsupervised deep learning (DL) based SLP model (SLP-DNet). We apply a stochastic quantization (SQ) technique to obtain its corresponding quantized version called SLP-SQDNet. The proposed scheme offers a scalable performance vs memory tradeoff, by quantizing a scale-able percentage of the DNN weights, and we explore binary and ternary quantizations. Our results show that while SLP-DNet provides near-optimal performance, its quantized versions through SQ yield 3.46x and 2.64x model compression for binary-based and ternary-based SLP-SQDNets, respectively. We also find that our proposals offer 20x and 10x computational complexity reductions compared to SLP optimization-based and SLP-DNet, respectively.
An Unsupervised Learning-Based Approach for Symbol-Level-Precoding
Apr 19, 2021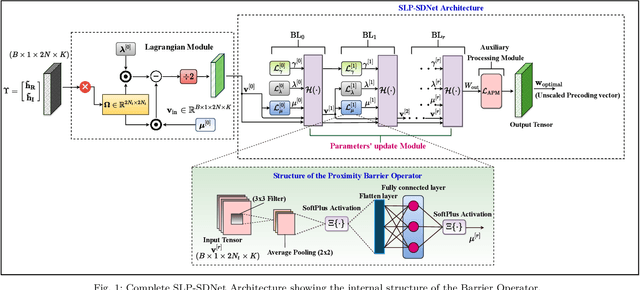
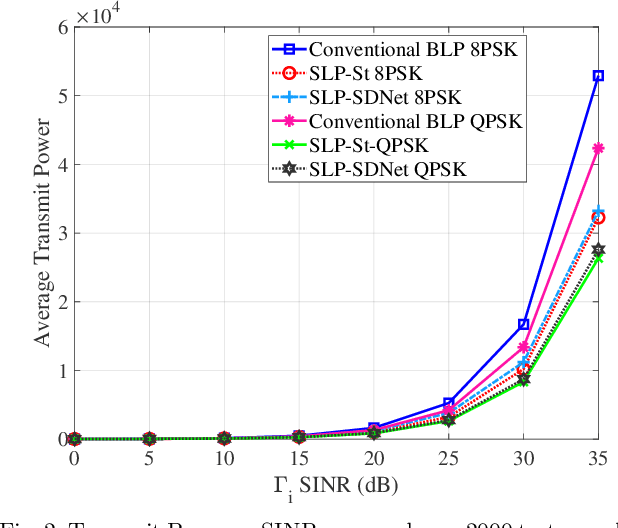
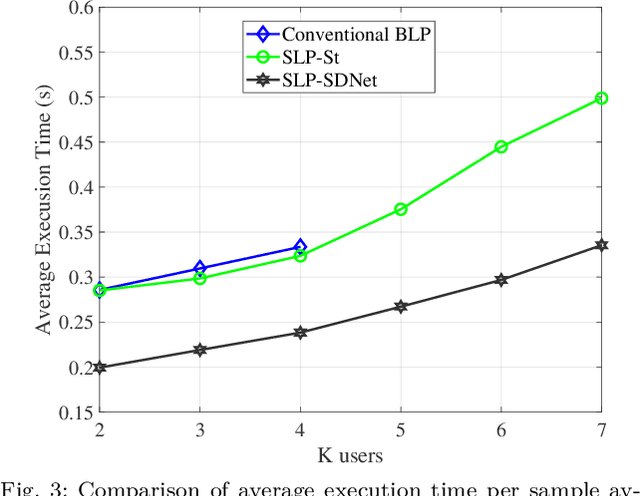
This paper proposes an unsupervised learning-based precoding framework that trains deep neural networks (DNNs) with no target labels by unfolding an interior point method (IPM) proximal `log' barrier function. The proximal `log' barrier function is derived from the strict power minimization formulation subject to signal-to-interference-plus-noise ratio (SINR) constraint. The proposed scheme exploits the known interference via symbol-level precoding (SLP) to minimize the transmit power and is named strict Symbol-Level-Precoding deep network (SLP-SDNet). The results show that SLP-SDNet outperforms the conventional block-level-precoding (Conventional BLP) scheme while achieving near-optimal performance faster than the SLP optimization-based approach
Biased Mixtures Of Experts: Enabling Computer Vision Inference Under Data Transfer Limitations
Aug 21, 2020
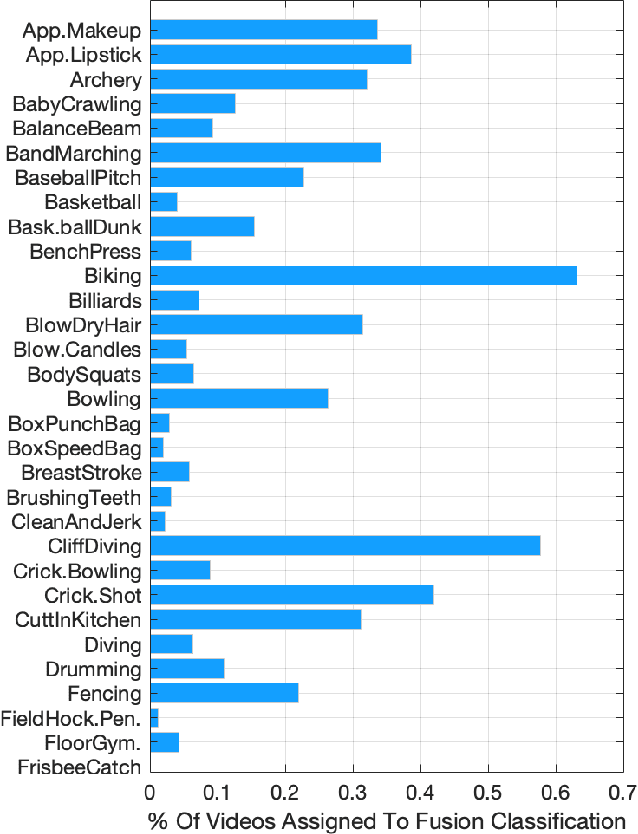
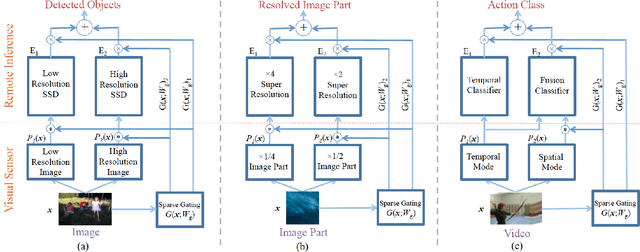
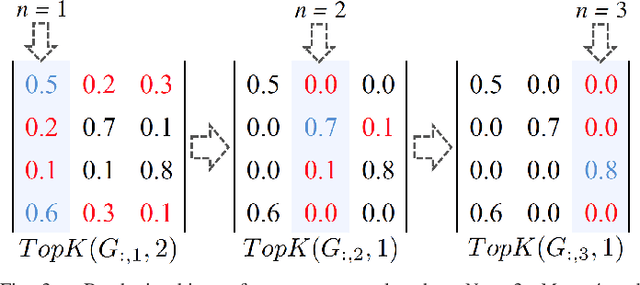
We propose a novel mixture-of-experts class to optimize computer vision models in accordance with data transfer limitations at test time. Our approach postulates that the minimum acceptable amount of data allowing for highly-accurate results can vary for different input space partitions. Therefore, we consider mixtures where experts require different amounts of data, and train a sparse gating function to divide the input space for each expert. By appropriate hyperparameter selection, our approach is able to bias mixtures of experts towards selecting specific experts over others. In this way, we show that the data transfer optimization between visual sensing and processing can be solved as a convex optimization problem.To demonstrate the relation between data availability and performance, we evaluate biased mixtures on a range of mainstream computer vision problems, namely: (i) single shot detection, (ii) image super resolution, and (iii) realtime video action classification. For all cases, and when experts constitute modified baselines to meet different limits on allowed data utility, biased mixtures significantly outperform previous work optimized to meet the same constraints on available data.
Graph-based Spatial-temporal Feature Learning for Neuromorphic Vision Sensing
Nov 11, 2019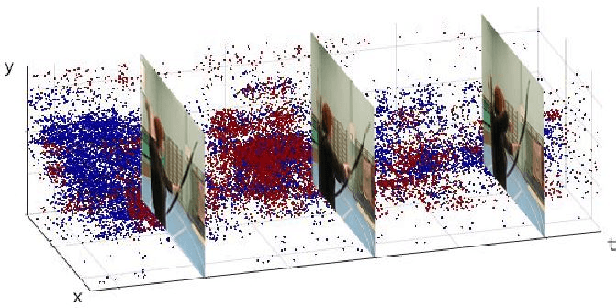

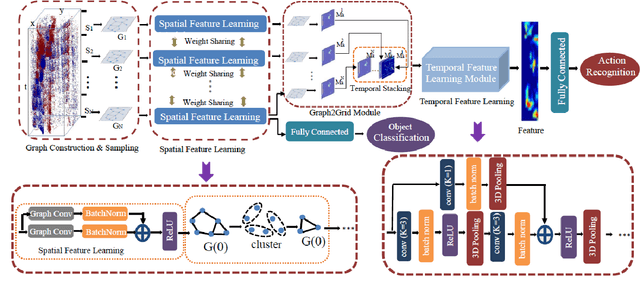

Neuromorphic vision sensing (NVS)\ devices represent visual information as sequences of asynchronous discrete events (a.k.a., "spikes") in response to changes in scene reflectance. Unlike conventional active pixel sensing (APS), NVS allows for significantly higher event sampling rates at substantially increased energy efficiency and robustness to illumination changes. However, feature representation for NVS is far behind its APS-based counterparts, resulting in lower performance in high-level computer vision tasks. To fully utilize its sparse and asynchronous nature, we propose a compact graph representation for NVS, which allows for end-to-end learning with graph convolution neural networks. We couple this with a novel end-to-end feature learning framework that accommodates both appearance-based and motion-based tasks. The core of our framework comprises a spatial feature learning module, which utilizes residual-graph convolutional neural networks (RG-CNN), for end-to-end learning of appearance-based features directly from graphs. We extend this with our proposed Graph2Grid block and temporal feature learning module for efficiently modelling temporal dependencies over multiple graphs and a long temporal extent. We show how our framework can be configured for object classification, action recognition and action similarity labeling. Importantly, our approach preserves the spatial and temporal coherence of spike events, while requiring less computation and memory. The experimental validation shows that our proposed framework outperforms all recent methods on standard datasets. Finally, to address the absence of large real-world NVS datasets for complex recognition tasks, we introduce, evaluate and make available the American Sign Language letters (ASL-DVS), as well as human action dataset (UCF101-DVS, HMDB51-DVS and ASLAN-DVS).
Complexity-Scalable Neural Network Based MIMO Detection With Learnable Weight Scaling
Sep 12, 2019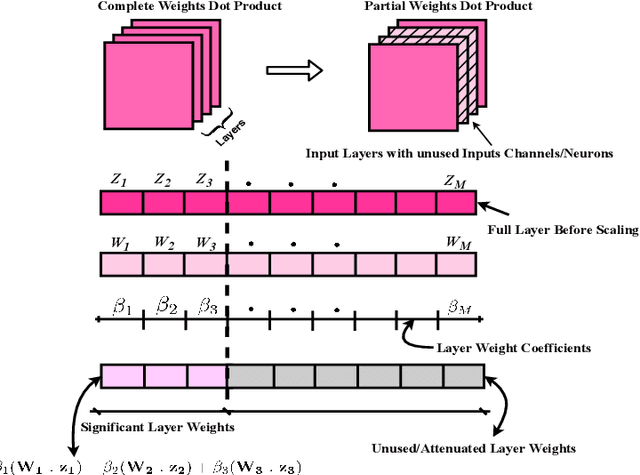
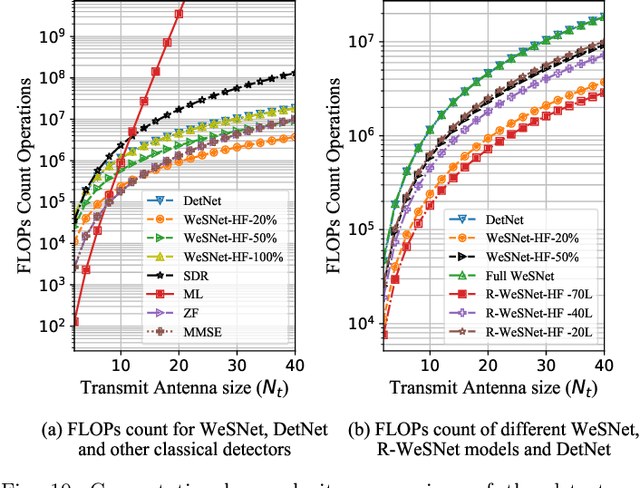
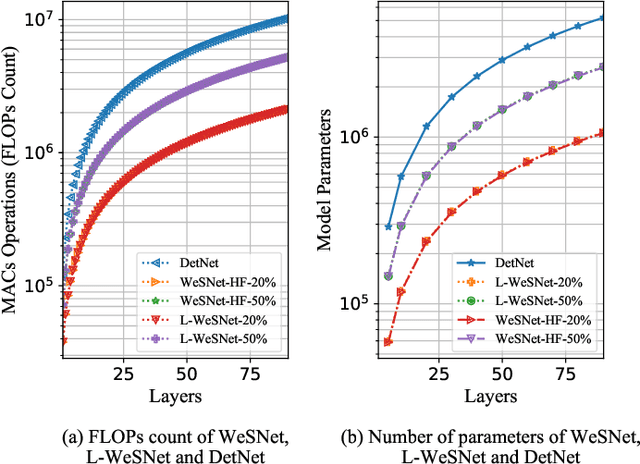
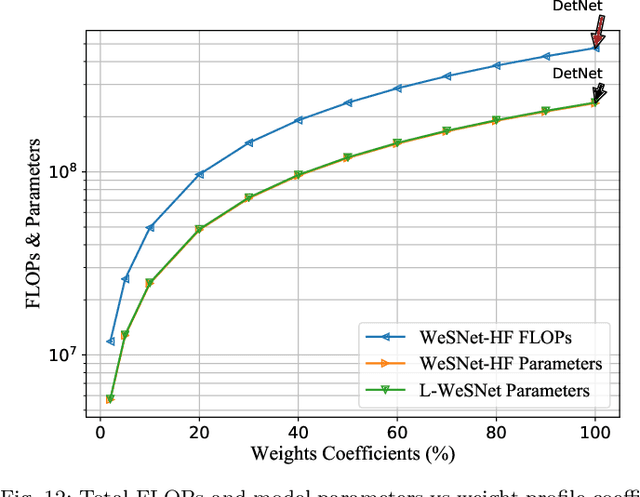
This paper introduces a framework for systematic complexity scaling of deep neural network (DNN) based MIMO detectors. The model uses a fraction of the DNN inputs by scaling their values through weights that follow monotonically non-increasing functions. This allows for weight scaling across and within the different DNN layers in order to achieve scalable complexity-accuracy results. To reduce complexity further, we introduce a regularization constraint on the layer weights such that, at inference, parts (or the entirety) of network layers can be removed with minimal impact on the detection accuracy. We also introduce trainable weight-scaling functions for increased robustness to changes in the activation patterns and a further improvement in the detection accuracy at the same inference complexity. Numerical results show that our approach is 10 and 100-fold less complex than classical approaches based on semi-definite relaxation and ML detection, respectively.
Graph-Based Object Classification for Neuromorphic Vision Sensing
Aug 19, 2019
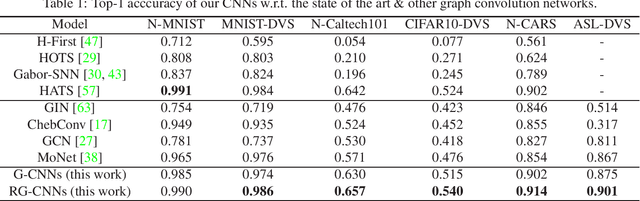
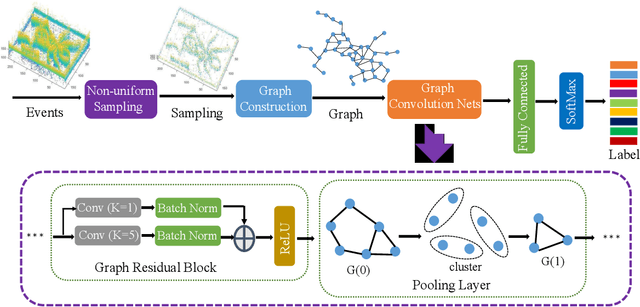

Neuromorphic vision sensing (NVS)\ devices represent visual information as sequences of asynchronous discrete events (a.k.a., ``spikes'') in response to changes in scene reflectance. Unlike conventional active pixel sensing (APS), NVS allows for significantly higher event sampling rates at substantially increased energy efficiency and robustness to illumination changes. However, object classification with NVS streams cannot leverage on state-of-the-art convolutional neural networks (CNNs), since NVS does not produce frame representations. To circumvent this mismatch between sensing and processing with CNNs, we propose a compact graph representation for NVS. We couple this with novel residual graph CNN architectures and show that, when trained on spatio-temporal NVS data for object classification, such residual graph CNNs preserve the spatial and temporal coherence of spike events, while requiring less computation and memory. Finally, to address the absence of large real-world NVS datasets for complex recognition tasks, we present and make available a 100k dataset of NVS recordings of the American sign language letters, acquired with an iniLabs DAVIS240c device under real-world conditions.
Deep Video Precoding
Aug 02, 2019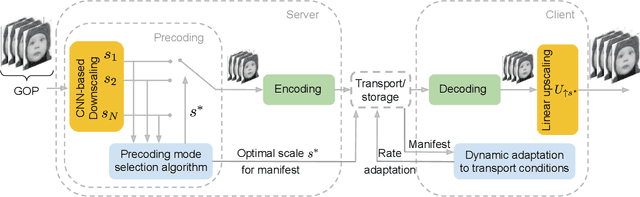
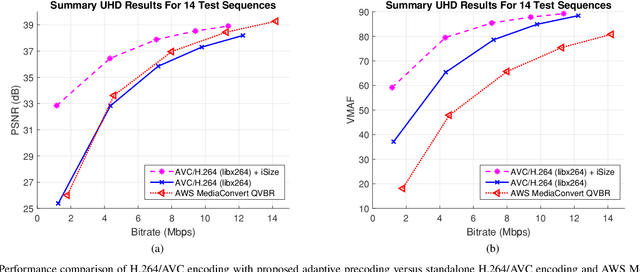
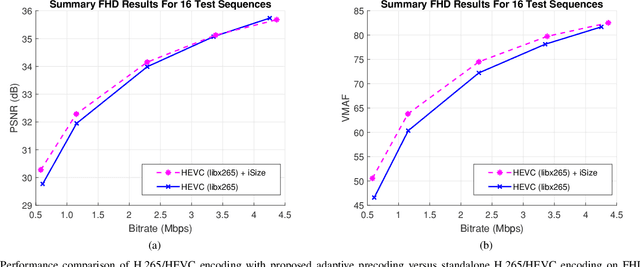
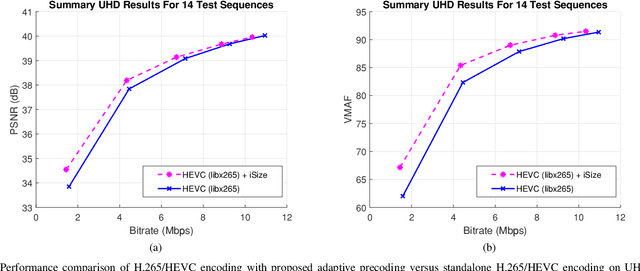
Several groups are currently investigating how deep learning may advance the state-of-the-art in image and video coding. An open question is how to make deep neural networks work in conjunction with existing (and upcoming) video codecs, such as MPEG AVC, HEVC, VVC, Google VP9 and AOM AV1, as well as existing container and transport formats, without imposing any changes at the client side. Such compatibility is a crucial aspect when it comes to practical deployment, especially due to the fact that the video content industry and hardware manufacturers are expected to remain committed to these standards for the foreseeable future. We propose to use deep neural networks as precoders for current and future video codecs and adaptive video streaming systems. In our current design, the core precoding component comprises a cascaded structure of downscaling neural networks that operates during video encoding, prior to transmission. This is coupled with a precoding mode selection algorithm for each independently-decodable stream segment, which adjusts the downscaling factor according to scene characteristics, the utilized encoder, and the desired bitrate and encoding configuration. Our framework is compatible with all current and future codec and transport standards, as our deep precoding network structure is trained in conjunction with linear upscaling filters (e.g., the bilinear filter), which are supported by all web video players. Results with FHD and UHD content and widely-used AVC, HEVC and VP9 encoders show that coupling such standards with the proposed deep video precoding allows for 15% to 45% rate reduction under encoding configurations and bitrates suitable for video-on-demand adaptive streaming systems. The use of precoding can also lead to encoding complexity reduction, which is essential for cost-effective cloud deployment of complex encoders like H.265/HEVC and VP9.
Improving Adversarial Discriminative Domain Adaptation
Oct 15, 2018



Adversarial discriminative domain adaptation (ADDA) is an efficient framework for unsupervised domain adaptation, where the source and target domains are assumed to have the same classes, but no labels are available for the target domain. While ADDA has already achieved better training efficiency and competitive accuracy in comparison to other adversarial based methods, we investigate whether we can improve performance by incorporating task knowledge into the adversarial loss functions. We achieve this by extending the discriminator output over the source classes and leverage on the distribution over the source encoder posteriors, which is fixed during adversarial training, in order to align a shared encoder distribution to the source domain. The shared encoder can receive a proportion of examples from both the source and target datasets, in order to smooth the learned distribution and improve its convergence properties during adversarial training. We additionally consider how the extended discriminator can be regularized in order to further improve performance, by treating the discriminator as a denoising autoencoder and corrupting its input. Our final design employs maximum mean discrepancy and reconstruction-based loss functions for adversarial training. We validate our framework on standard datasets like MNIST, USPS, SVHN, MNIST-M and Office-31. Our results on all datasets show that our proposal is both simple and efficient, as it competes or outperforms the state-of-the-art in unsupervised domain adaptation, whilst offering lower complexity than other recent adversarial methods such as DIFA and CoGAN.