 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-based Spatial-temporal Feature Learning for Neuromorphic Vision Sensing
Nov 11, 2019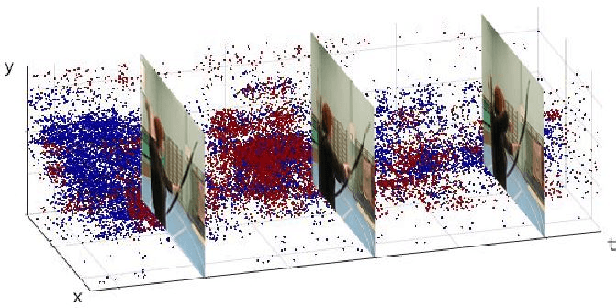

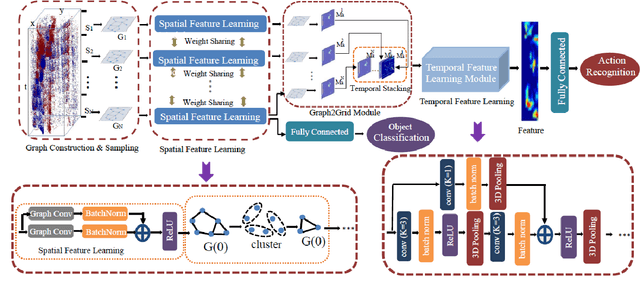

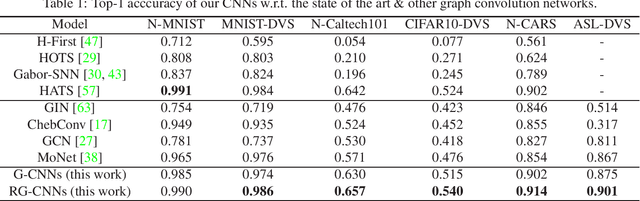
Neuromorphic vision sensing (NVS)\ devices represent visual information as sequences of asynchronous discrete events (a.k.a., "spikes") in response to changes in scene reflectance. Unlike conventional active pixel sensing (APS), NVS allows for significantly higher event sampling rates at substantially increased energy efficiency and robustness to illumination changes. However, feature representation for NVS is far behind its APS-based counterparts, resulting in lower performance in high-level computer vision tasks. To fully utilize its sparse and asynchronous nature, we propose a compact graph representation for NVS, which allows for end-to-end learning with graph convolution neural networks. We couple this with a novel end-to-end feature learning framework that accommodates both appearance-based and motion-based tasks. The core of our framework comprises a spatial feature learning module, which utilizes residual-graph convolutional neural networks (RG-CNN), for end-to-end learning of appearance-based features directly from graphs. We extend this with our proposed Graph2Grid block and temporal feature learning module for efficiently modelling temporal dependencies over multiple graphs and a long temporal extent. We show how our framework can be configured for object classification, action recognition and action similarity labeling. Importantly, our approach preserves the spatial and temporal coherence of spike events, while requiring less computation and memory. The experimental validation shows that our proposed framework outperforms all recent methods on standard datasets. Finally, to address the absence of large real-world NVS datasets for complex recognition tasks, we introduce, evaluate and make available the American Sign Language letters (ASL-DVS), as well as human action dataset (UCF101-DVS, HMDB51-DVS and ASLAN-DVS).
Graph-Based Object Classification for Neuromorphic Vision Sensing
Aug 19, 2019
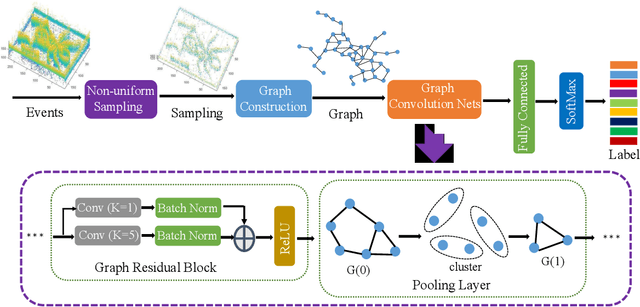

Neuromorphic vision sensing (NVS)\ devices represent visual information as sequences of asynchronous discrete events (a.k.a., ``spikes'') in response to changes in scene reflectance. Unlike conventional active pixel sensing (APS), NVS allows for significantly higher event sampling rates at substantially increased energy efficiency and robustness to illumination changes. However, object classification with NVS streams cannot leverage on state-of-the-art convolutional neural networks (CNNs), since NVS does not produce frame representations. To circumvent this mismatch between sensing and processing with CNNs, we propose a compact graph representation for NVS. We couple this with novel residual graph CNN architectures and show that, when trained on spatio-temporal NVS data for object classification, such residual graph CNNs preserve the spatial and temporal coherence of spike events, while requiring less computation and memory. Finally, to address the absence of large real-world NVS datasets for complex recognition tasks, we present and make available a 100k dataset of NVS recordings of the American sign language letters, acquired with an iniLabs DAVIS240c device under real-world conditions.
Deep Video Precoding
Aug 02, 2019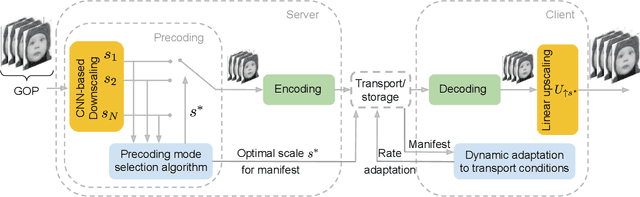
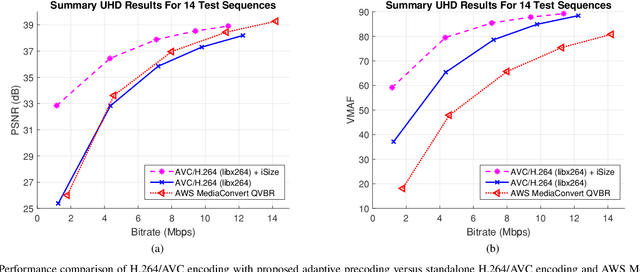
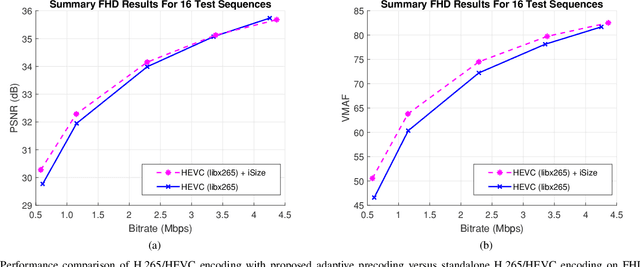
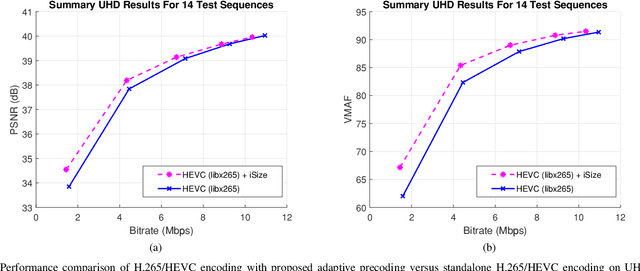
Several groups are currently investigating how deep learning may advance the state-of-the-art in image and video coding. An open question is how to make deep neural networks work in conjunction with existing (and upcoming) video codecs, such as MPEG AVC, HEVC, VVC, Google VP9 and AOM AV1, as well as existing container and transport formats, without imposing any changes at the client side. Such compatibility is a crucial aspect when it comes to practical deployment, especially due to the fact that the video content industry and hardware manufacturers are expected to remain committed to these standards for the foreseeable future. We propose to use deep neural networks as precoders for current and future video codecs and adaptive video streaming systems. In our current design, the core precoding component comprises a cascaded structure of downscaling neural networks that operates during video encoding, prior to transmission. This is coupled with a precoding mode selection algorithm for each independently-decodable stream segment, which adjusts the downscaling factor according to scene characteristics, the utilized encoder, and the desired bitrate and encoding configuration. Our framework is compatible with all current and future codec and transport standards, as our deep precoding network structure is trained in conjunction with linear upscaling filters (e.g., the bilinear filter), which are supported by all web video players. Results with FHD and UHD content and widely-used AVC, HEVC and VP9 encoders show that coupling such standards with the proposed deep video precoding allows for 15% to 45% rate reduction under encoding configurations and bitrates suitable for video-on-demand adaptive streaming systems. The use of precoding can also lead to encoding complexity reduction, which is essential for cost-effective cloud deployment of complex encoders like H.265/HEVC and VP9.
Improving Adversarial Discriminative Domain Adaptation
Oct 15, 2018



Adversarial discriminative domain adaptation (ADDA) is an efficient framework for unsupervised domain adaptation, where the source and target domains are assumed to have the same classes, but no labels are available for the target domain. While ADDA has already achieved better training efficiency and competitive accuracy in comparison to other adversarial based methods, we investigate whether we can improve performance by incorporating task knowledge into the adversarial loss functions. We achieve this by extending the discriminator output over the source classes and leverage on the distribution over the source encoder posteriors, which is fixed during adversarial training, in order to align a shared encoder distribution to the source domain. The shared encoder can receive a proportion of examples from both the source and target datasets, in order to smooth the learned distribution and improve its convergence properties during adversarial training. We additionally consider how the extended discriminator can be regularized in order to further improve performance, by treating the discriminator as a denoising autoencoder and corrupting its input. Our final design employs maximum mean discrepancy and reconstruction-based loss functions for adversarial training. We validate our framework on standard datasets like MNIST, USPS, SVHN, MNIST-M and Office-31. Our results on all datasets show that our proposal is both simple and efficient, as it competes or outperforms the state-of-the-art in unsupervised domain adaptation, whilst offering lower complexity than other recent adversarial methods such as DIFA and CoGAN.
Rate-Accuracy Trade-Off In Video Classification With Deep Convolutional Neural Networks
Sep 27, 2018



Advanced video classification systems decode video frames to derive the necessary texture and motion representations for ingestion and analysis by spatio-temporal deep convolutional neural networks (CNNs). However, when considering visual Internet-of-Things applications, surveillance systems and semantic crawlers of large video repositories, the video capture and the CNN-based semantic analysis parts do not tend to be co-located. This necessitates the transport of compressed video over networks and incurs significant overhead in bandwidth and energy consumption, thereby significantly undermining the deployment potential of such systems. In this paper, we investigate the trade-off between the encoding bitrate and the achievable accuracy of CNN-based video classification models that directly ingest AVC/H.264 and HEVC encoded videos. Instead of retaining entire compressed video bitstreams and applying complex optical flow calculations prior to CNN processing, we only retain motion vector and select texture information at significantly-reduced bitrates and apply no additional processing prior to CNN ingestion. Based on three CNN architectures and two action recognition datasets, we achieve 11%-94% saving in bitrate with marginal effect on classification accuracy. A model-based selection between multiple CNNs increases these savings further, to the point where, if up to 7% loss of accuracy can be tolerated, video classification can take place with as little as 3 kbps for the transport of the required compressed video information to the system implementing the CNN models.
Video Classification With CNNs: Using The Codec As A Spatio-Temporal Activity Sensor
Dec 19, 2017



We investigate video classification via a two-stream convolutional neural network (CNN) design that directly ingests information extracted from compressed video bitstreams. Our approach begins with the observation that all modern video codecs divide the input frames into macroblocks (MBs). We demonstrate that selective access to MB motion vector (MV) information within compressed video bitstreams can also provide for selective, motion-adaptive, MB pixel decoding (a.k.a., MB texture decoding). This in turn allows for the derivation of spatio-temporal video activity regions at extremely high speed in comparison to conventional full-frame decoding followed by optical flow estimation. In order to evaluate the accuracy of a video classification framework based on such activity data, we independently train two CNN architectures on MB texture and MV correspondences and then fuse their scores to derive the final classification of each test video. Evaluation on two standard datasets shows that the proposed approach is competitive to the best two-stream video classification approaches found in the literature. At the same time: (i) a CPU-based realization of our MV extraction is over 977 times faster than GPU-based optical flow methods; (ii) selective decoding is up to 12 times faster than full-frame decoding; (iii) our proposed spatial and temporal CNNs perform inference at 5 to 49 times lower cloud computing cost than the fastest methods from the literature.
Voronoi-based compact image descriptors: Efficient Region-of-Interest retrieval with VLAD and deep-learning-based descriptors
Mar 20, 2017


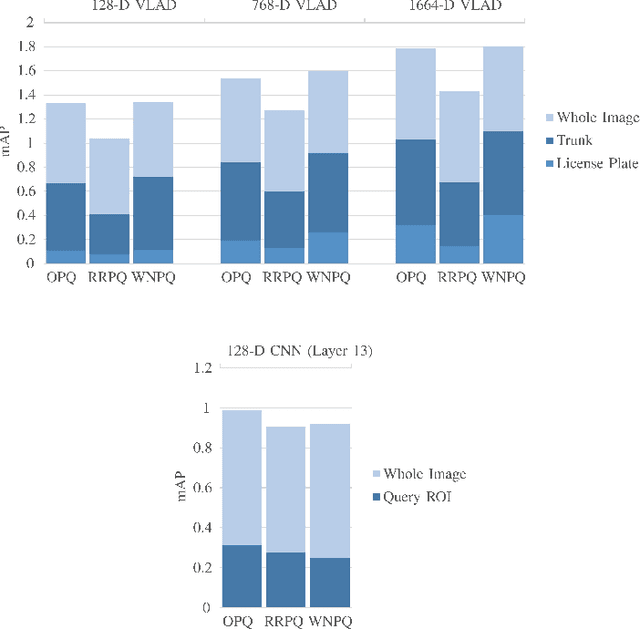
We investigate the problem of image retrieval based on visual queries when the latter comprise arbitrary regions-of-interest (ROI) rather than entire images. Our proposal is a compact image descriptor that combines the state-of-the-art in content-based descriptor extraction with a multi-level, Voronoi-based spatial partitioning of each dataset image. The proposed multi-level Voronoi-based encoding uses a spatial hierarchical K-means over interest-point locations, and computes a content-based descriptor over each cell. In order to reduce the matching complexity with minimal or no sacrifice in retrieval performance: (i) we utilize the tree structure of the spatial hierarchical K-means to perform a top-to-bottom pruning for local similarity maxima; (ii) we propose a new image similarity score that combines relevant information from all partition levels into a single measure for similarity; (iii) we combine our proposal with a novel and efficient approach for optimal bit allocation within quantized descriptor representations. By deriving both a Voronoi-based VLAD descriptor (termed as Fast-VVLAD) and a Voronoi-based deep convolutional neural network (CNN) descriptor (termed as Fast-VDCNN), we demonstrate that our Voronoi-based framework is agnostic to the descriptor basis, and can easily be slotted into existing frameworks. Via a range of ROI queries in two standard datasets, it is shown that the Voronoi-based descriptors achieve comparable or higher mean Average Precision against conventional grid-based spatial search, while offering more than two-fold reduction in complexity. Finally, beyond ROI queries, we show that Voronoi partitioning improves the geometric invariance of compact CNN descriptors, thereby resulting in competitive performance to the current state-of-the-art on whole image retrieval.