 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiased Mixtures Of Experts: Enabling Computer Vision Inference Under Data Transfer Limitations
Aug 21, 2020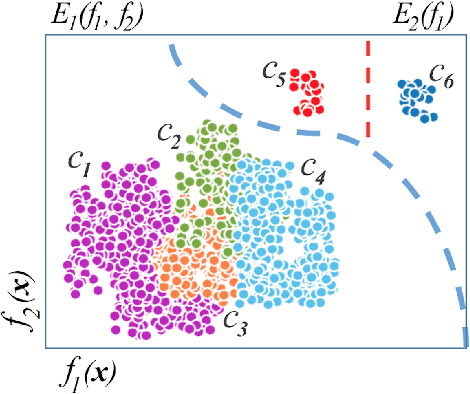
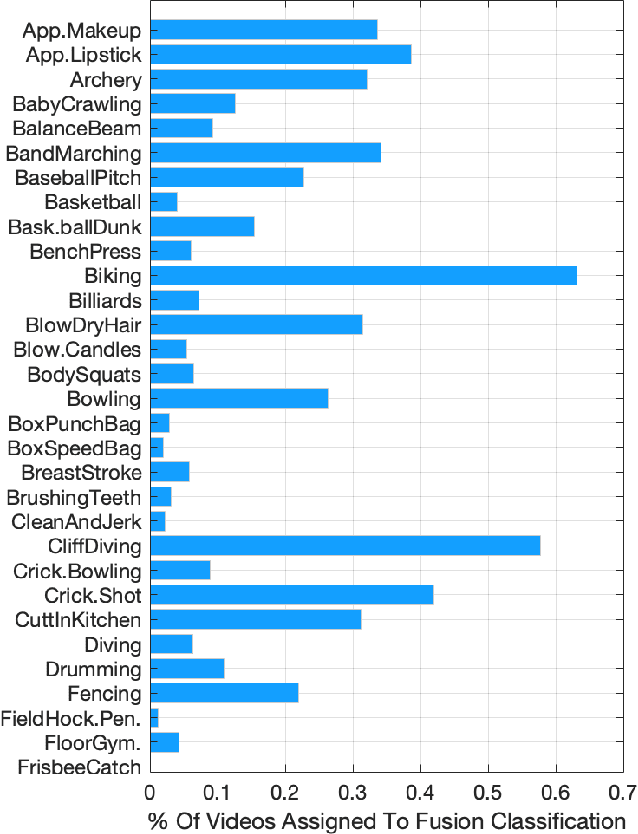
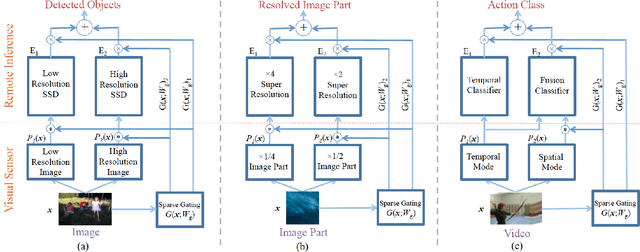
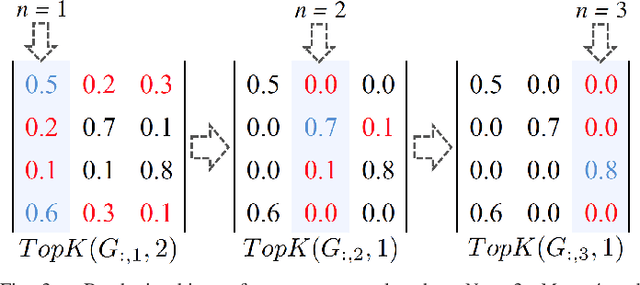
We propose a novel mixture-of-experts class to optimize computer vision models in accordance with data transfer limitations at test time. Our approach postulates that the minimum acceptable amount of data allowing for highly-accurate results can vary for different input space partitions. Therefore, we consider mixtures where experts require different amounts of data, and train a sparse gating function to divide the input space for each expert. By appropriate hyperparameter selection, our approach is able to bias mixtures of experts towards selecting specific experts over others. In this way, we show that the data transfer optimization between visual sensing and processing can be solved as a convex optimization problem.To demonstrate the relation between data availability and performance, we evaluate biased mixtures on a range of mainstream computer vision problems, namely: (i) single shot detection, (ii) image super resolution, and (iii) realtime video action classification. For all cases, and when experts constitute modified baselines to meet different limits on allowed data utility, biased mixtures significantly outperform previous work optimized to meet the same constraints on available data.
Graph-based Spatial-temporal Feature Learning for Neuromorphic Vision Sensing
Nov 11, 2019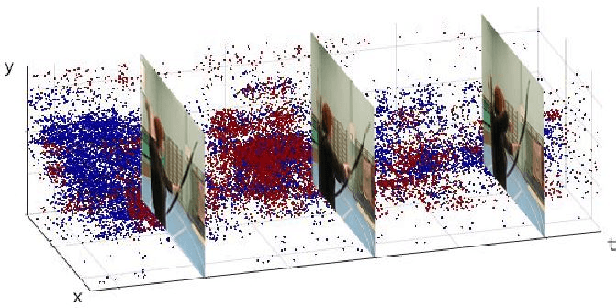

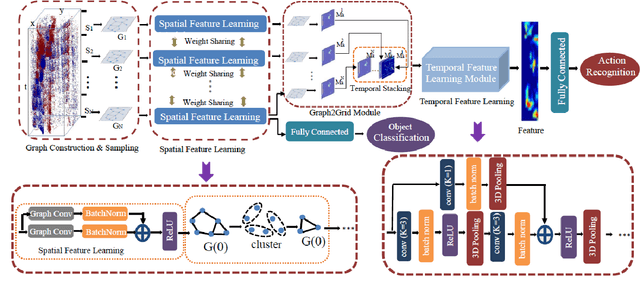

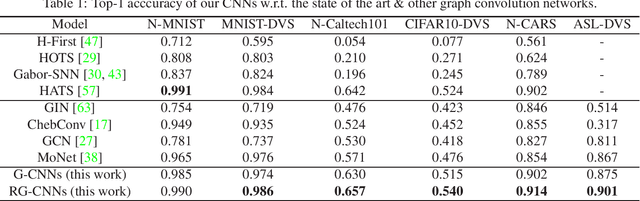
Neuromorphic vision sensing (NVS)\ devices represent visual information as sequences of asynchronous discrete events (a.k.a., "spikes") in response to changes in scene reflectance. Unlike conventional active pixel sensing (APS), NVS allows for significantly higher event sampling rates at substantially increased energy efficiency and robustness to illumination changes. However, feature representation for NVS is far behind its APS-based counterparts, resulting in lower performance in high-level computer vision tasks. To fully utilize its sparse and asynchronous nature, we propose a compact graph representation for NVS, which allows for end-to-end learning with graph convolution neural networks. We couple this with a novel end-to-end feature learning framework that accommodates both appearance-based and motion-based tasks. The core of our framework comprises a spatial feature learning module, which utilizes residual-graph convolutional neural networks (RG-CNN), for end-to-end learning of appearance-based features directly from graphs. We extend this with our proposed Graph2Grid block and temporal feature learning module for efficiently modelling temporal dependencies over multiple graphs and a long temporal extent. We show how our framework can be configured for object classification, action recognition and action similarity labeling. Importantly, our approach preserves the spatial and temporal coherence of spike events, while requiring less computation and memory. The experimental validation shows that our proposed framework outperforms all recent methods on standard datasets. Finally, to address the absence of large real-world NVS datasets for complex recognition tasks, we introduce, evaluate and make available the American Sign Language letters (ASL-DVS), as well as human action dataset (UCF101-DVS, HMDB51-DVS and ASLAN-DVS).
Graph-Based Object Classification for Neuromorphic Vision Sensing
Aug 19, 2019
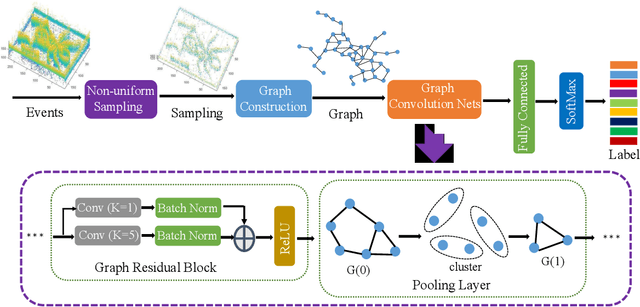

Neuromorphic vision sensing (NVS)\ devices represent visual information as sequences of asynchronous discrete events (a.k.a., ``spikes'') in response to changes in scene reflectance. Unlike conventional active pixel sensing (APS), NVS allows for significantly higher event sampling rates at substantially increased energy efficiency and robustness to illumination changes. However, object classification with NVS streams cannot leverage on state-of-the-art convolutional neural networks (CNNs), since NVS does not produce frame representations. To circumvent this mismatch between sensing and processing with CNNs, we propose a compact graph representation for NVS. We couple this with novel residual graph CNN architectures and show that, when trained on spatio-temporal NVS data for object classification, such residual graph CNNs preserve the spatial and temporal coherence of spike events, while requiring less computation and memory. Finally, to address the absence of large real-world NVS datasets for complex recognition tasks, we present and make available a 100k dataset of NVS recordings of the American sign language letters, acquired with an iniLabs DAVIS240c device under real-world conditions.
Rate-Accuracy Trade-Off In Video Classification With Deep Convolutional Neural Networks
Sep 27, 2018



Advanced video classification systems decode video frames to derive the necessary texture and motion representations for ingestion and analysis by spatio-temporal deep convolutional neural networks (CNNs). However, when considering visual Internet-of-Things applications, surveillance systems and semantic crawlers of large video repositories, the video capture and the CNN-based semantic analysis parts do not tend to be co-located. This necessitates the transport of compressed video over networks and incurs significant overhead in bandwidth and energy consumption, thereby significantly undermining the deployment potential of such systems. In this paper, we investigate the trade-off between the encoding bitrate and the achievable accuracy of CNN-based video classification models that directly ingest AVC/H.264 and HEVC encoded videos. Instead of retaining entire compressed video bitstreams and applying complex optical flow calculations prior to CNN processing, we only retain motion vector and select texture information at significantly-reduced bitrates and apply no additional processing prior to CNN ingestion. Based on three CNN architectures and two action recognition datasets, we achieve 11%-94% saving in bitrate with marginal effect on classification accuracy. A model-based selection between multiple CNNs increases these savings further, to the point where, if up to 7% loss of accuracy can be tolerated, video classification can take place with as little as 3 kbps for the transport of the required compressed video information to the system implementing the CNN models.
Video Classification With CNNs: Using The Codec As A Spatio-Temporal Activity Sensor
Dec 19, 2017



We investigate video classification via a two-stream convolutional neural network (CNN) design that directly ingests information extracted from compressed video bitstreams. Our approach begins with the observation that all modern video codecs divide the input frames into macroblocks (MBs). We demonstrate that selective access to MB motion vector (MV) information within compressed video bitstreams can also provide for selective, motion-adaptive, MB pixel decoding (a.k.a., MB texture decoding). This in turn allows for the derivation of spatio-temporal video activity regions at extremely high speed in comparison to conventional full-frame decoding followed by optical flow estimation. In order to evaluate the accuracy of a video classification framework based on such activity data, we independently train two CNN architectures on MB texture and MV correspondences and then fuse their scores to derive the final classification of each test video. Evaluation on two standard datasets shows that the proposed approach is competitive to the best two-stream video classification approaches found in the literature. At the same time: (i) a CPU-based realization of our MV extraction is over 977 times faster than GPU-based optical flow methods; (ii) selective decoding is up to 12 times faster than full-frame decoding; (iii) our proposed spatial and temporal CNNs perform inference at 5 to 49 times lower cloud computing cost than the fastest methods from the literature.
Vectors of Locally Aggregated Centers for Compact Video Representation
Sep 13, 2015
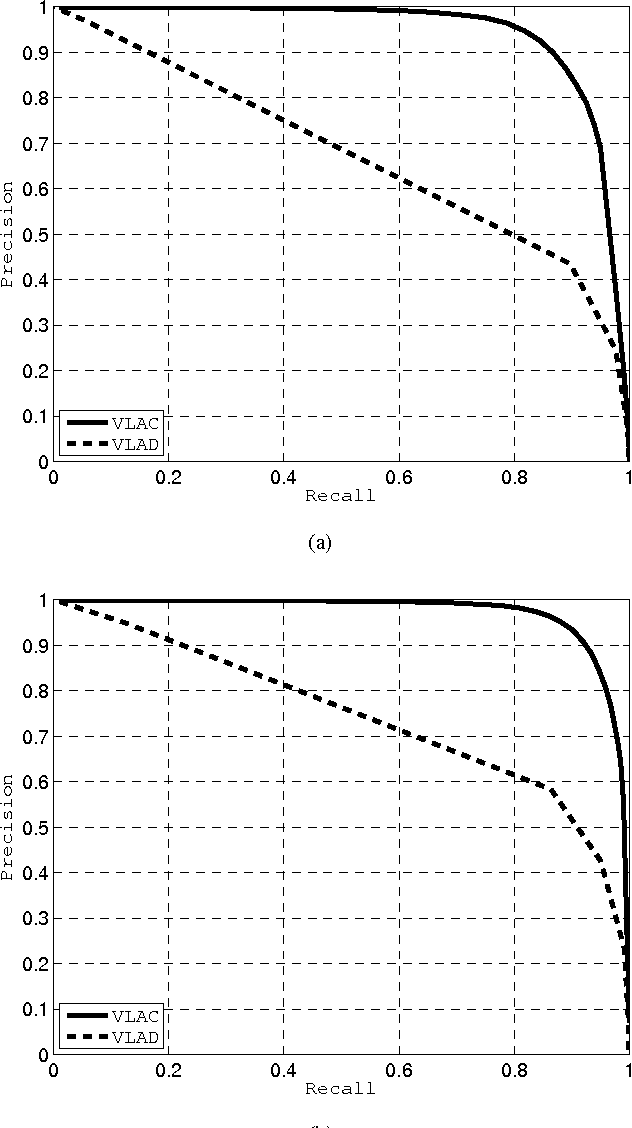

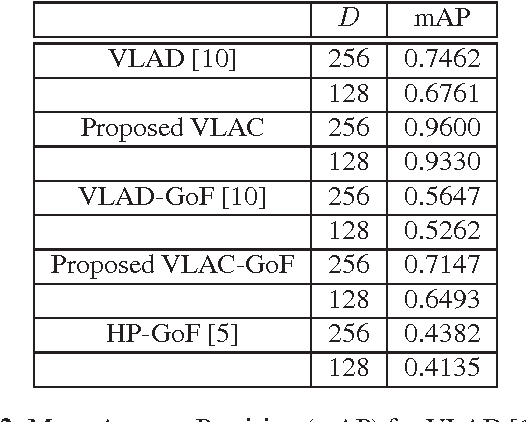
We propose a novel vector aggregation technique for compact video representation, with application in accurate similarity detection within large video datasets. The current state-of-the-art in visual search is formed by the vector of locally aggregated descriptors (VLAD) of Jegou et. al. VLAD generates compact video representations based on scale-invariant feature transform (SIFT) vectors (extracted per frame) and local feature centers computed over a training set. With the aim to increase robustness to visual distortions, we propose a new approach that operates at a coarser level in the feature representation. We create vectors of locally aggregated centers (VLAC) by first clustering SIFT features to obtain local feature centers (LFCs) and then encoding the latter with respect to given centers of local feature centers (CLFCs), extracted from a training set. The sum-of-differences between the LFCs and the CLFCs are aggregated to generate an extremely-compact video description used for accurate video segment similarity detection. Experimentation using a video dataset, comprising more than 1000 minutes of content from the Open Video Project, shows that VLAC obtains substantial gains in terms of mean Average Precision (mAP) against VLAD and the hyper-pooling method of Douze et. al., under the same compaction factor and the same set of distortions.