 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-based Spatial-temporal Feature Learning for Neuromorphic Vision Sensing
Nov 11, 2019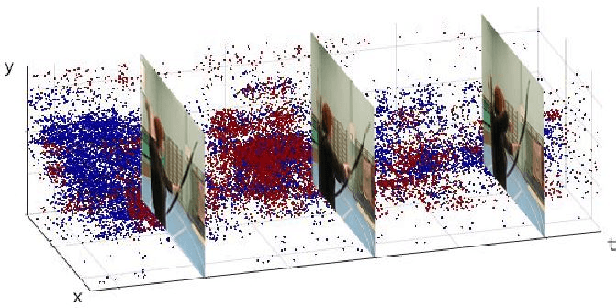

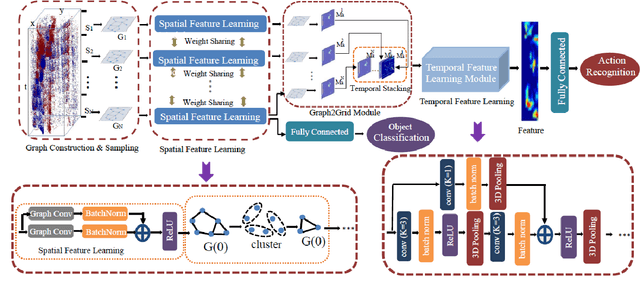

Neuromorphic vision sensing (NVS)\ devices represent visual information as sequences of asynchronous discrete events (a.k.a., "spikes") in response to changes in scene reflectance. Unlike conventional active pixel sensing (APS), NVS allows for significantly higher event sampling rates at substantially increased energy efficiency and robustness to illumination changes. However, feature representation for NVS is far behind its APS-based counterparts, resulting in lower performance in high-level computer vision tasks. To fully utilize its sparse and asynchronous nature, we propose a compact graph representation for NVS, which allows for end-to-end learning with graph convolution neural networks. We couple this with a novel end-to-end feature learning framework that accommodates both appearance-based and motion-based tasks. The core of our framework comprises a spatial feature learning module, which utilizes residual-graph convolutional neural networks (RG-CNN), for end-to-end learning of appearance-based features directly from graphs. We extend this with our proposed Graph2Grid block and temporal feature learning module for efficiently modelling temporal dependencies over multiple graphs and a long temporal extent. We show how our framework can be configured for object classification, action recognition and action similarity labeling. Importantly, our approach preserves the spatial and temporal coherence of spike events, while requiring less computation and memory. The experimental validation shows that our proposed framework outperforms all recent methods on standard datasets. Finally, to address the absence of large real-world NVS datasets for complex recognition tasks, we introduce, evaluate and make available the American Sign Language letters (ASL-DVS), as well as human action dataset (UCF101-DVS, HMDB51-DVS and ASLAN-DVS).
Graph-Based Object Classification for Neuromorphic Vision Sensing
Aug 19, 2019
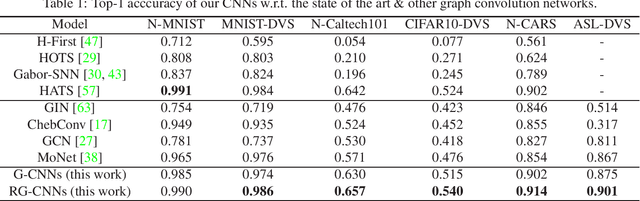
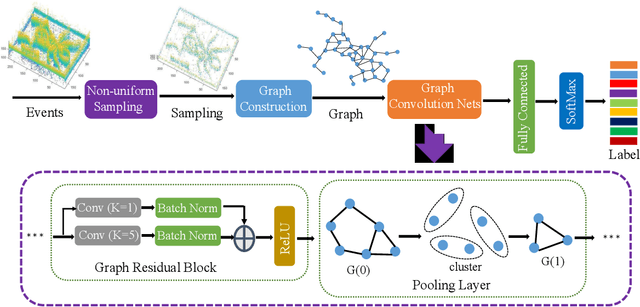

Neuromorphic vision sensing (NVS)\ devices represent visual information as sequences of asynchronous discrete events (a.k.a., ``spikes'') in response to changes in scene reflectance. Unlike conventional active pixel sensing (APS), NVS allows for significantly higher event sampling rates at substantially increased energy efficiency and robustness to illumination changes. However, object classification with NVS streams cannot leverage on state-of-the-art convolutional neural networks (CNNs), since NVS does not produce frame representations. To circumvent this mismatch between sensing and processing with CNNs, we propose a compact graph representation for NVS. We couple this with novel residual graph CNN architectures and show that, when trained on spatio-temporal NVS data for object classification, such residual graph CNNs preserve the spatial and temporal coherence of spike events, while requiring less computation and memory. Finally, to address the absence of large real-world NVS datasets for complex recognition tasks, we present and make available a 100k dataset of NVS recordings of the American sign language letters, acquired with an iniLabs DAVIS240c device under real-world conditions.
Deep Video Precoding
Aug 02, 2019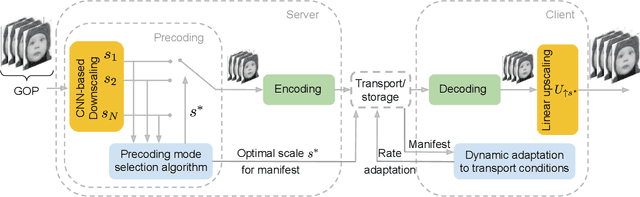
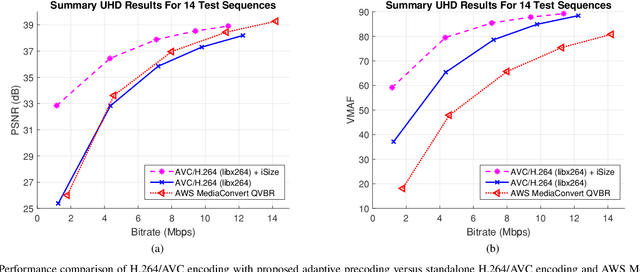
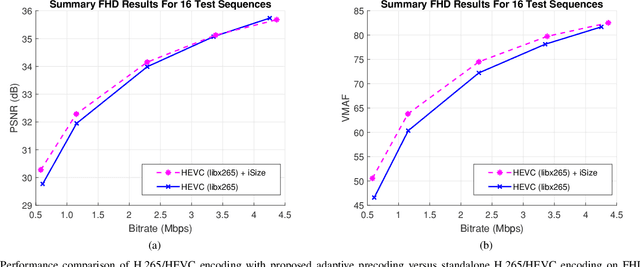
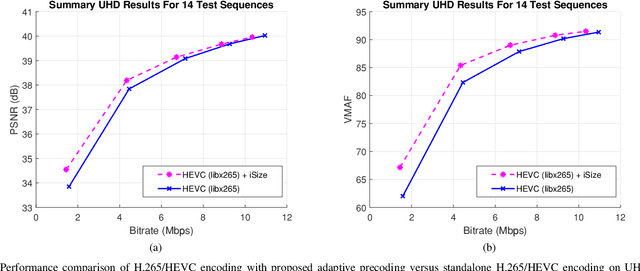
Several groups are currently investigating how deep learning may advance the state-of-the-art in image and video coding. An open question is how to make deep neural networks work in conjunction with existing (and upcoming) video codecs, such as MPEG AVC, HEVC, VVC, Google VP9 and AOM AV1, as well as existing container and transport formats, without imposing any changes at the client side. Such compatibility is a crucial aspect when it comes to practical deployment, especially due to the fact that the video content industry and hardware manufacturers are expected to remain committed to these standards for the foreseeable future. We propose to use deep neural networks as precoders for current and future video codecs and adaptive video streaming systems. In our current design, the core precoding component comprises a cascaded structure of downscaling neural networks that operates during video encoding, prior to transmission. This is coupled with a precoding mode selection algorithm for each independently-decodable stream segment, which adjusts the downscaling factor according to scene characteristics, the utilized encoder, and the desired bitrate and encoding configuration. Our framework is compatible with all current and future codec and transport standards, as our deep precoding network structure is trained in conjunction with linear upscaling filters (e.g., the bilinear filter), which are supported by all web video players. Results with FHD and UHD content and widely-used AVC, HEVC and VP9 encoders show that coupling such standards with the proposed deep video precoding allows for 15% to 45% rate reduction under encoding configurations and bitrates suitable for video-on-demand adaptive streaming systems. The use of precoding can also lead to encoding complexity reduction, which is essential for cost-effective cloud deployment of complex encoders like H.265/HEVC and VP9.
Deep Joint Source-Channel Coding for Wireless Image Transmission
Sep 15, 2018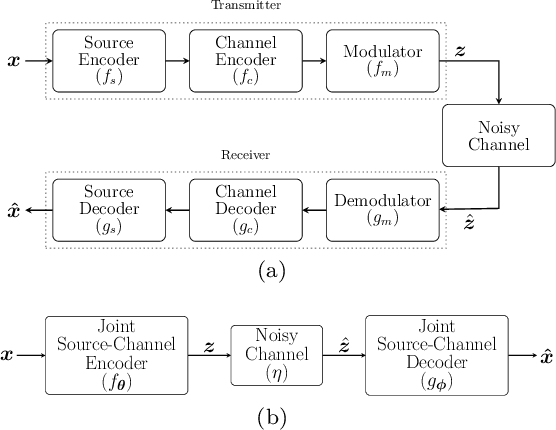
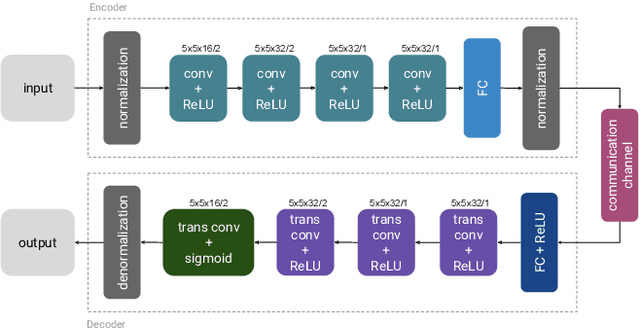
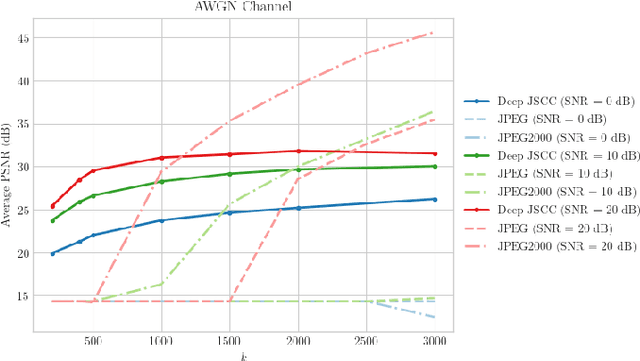
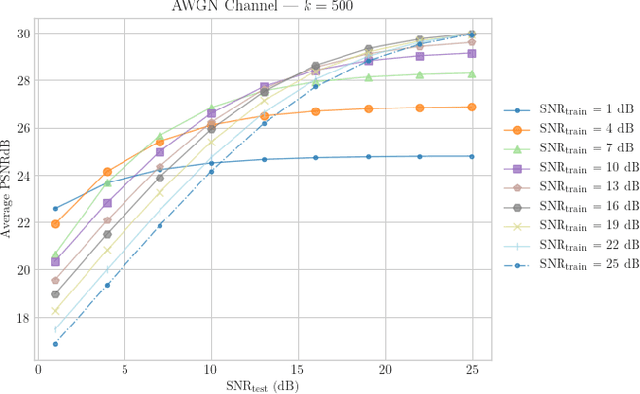
We propose a joint source and channel coding (JSCC) technique for wireless image transmission that does not rely on explicit codes for either compression or error correction; instead, it directly maps the image pixel values to the real/complex - valued channel input symbols. We parameterize the encoder and decoder functions by two convolutional neural networks (CNNs), which are trained jointly, and can be considered as an autoencoder with a non-trainable layer in the middle that represents the noisy communication channel. Our results show that the proposed deep JSCC scheme outperforms digital transmission concatenating JPEG or JPEG2000 compression with a capacity achieving channel code at low signal-to-noise ratio (SNR) and channel bandwidth values in the presence of additive white Gaussian noise. More strikingly, deep JSCC does not suffer from the `cliff effect', and it provides a graceful performance degradation as the channel SNR varies with respect to the training SNR. In the case of a slow Rayleigh fading channel, deep JSCC can learn to communicate without explicit pilot signals or channel estimation, and significantly outperforms separation-based digital communication at all SNR and channel bandwidth values.