 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-based Spatial-temporal Feature Learning for Neuromorphic Vision Sensing
Paper and Code
Nov 11, 2019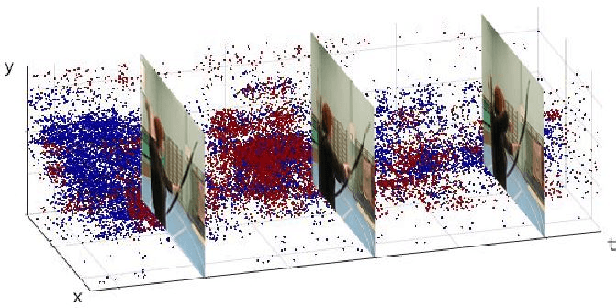

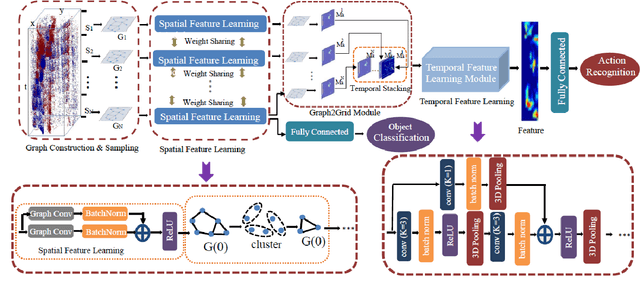

Neuromorphic vision sensing (NVS)\ devices represent visual information as sequences of asynchronous discrete events (a.k.a., "spikes") in response to changes in scene reflectance. Unlike conventional active pixel sensing (APS), NVS allows for significantly higher event sampling rates at substantially increased energy efficiency and robustness to illumination changes. However, feature representation for NVS is far behind its APS-based counterparts, resulting in lower performance in high-level computer vision tasks. To fully utilize its sparse and asynchronous nature, we propose a compact graph representation for NVS, which allows for end-to-end learning with graph convolution neural networks. We couple this with a novel end-to-end feature learning framework that accommodates both appearance-based and motion-based tasks. The core of our framework comprises a spatial feature learning module, which utilizes residual-graph convolutional neural networks (RG-CNN), for end-to-end learning of appearance-based features directly from graphs. We extend this with our proposed Graph2Grid block and temporal feature learning module for efficiently modelling temporal dependencies over multiple graphs and a long temporal extent. We show how our framework can be configured for object classification, action recognition and action similarity labeling. Importantly, our approach preserves the spatial and temporal coherence of spike events, while requiring less computation and memory. The experimental validation shows that our proposed framework outperforms all recent methods on standard datasets. Finally, to address the absence of large real-world NVS datasets for complex recognition tasks, we introduce, evaluate and make available the American Sign Language letters (ASL-DVS), as well as human action dataset (UCF101-DVS, HMDB51-DVS and ASLAN-DVS).