 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Memory-Efficient Learning Framework for SymbolLevel Precoding with Quantized NN Weights
Paper and Code
Oct 13, 2021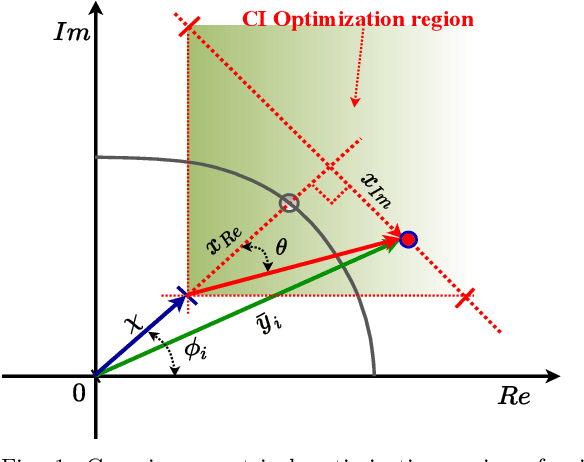
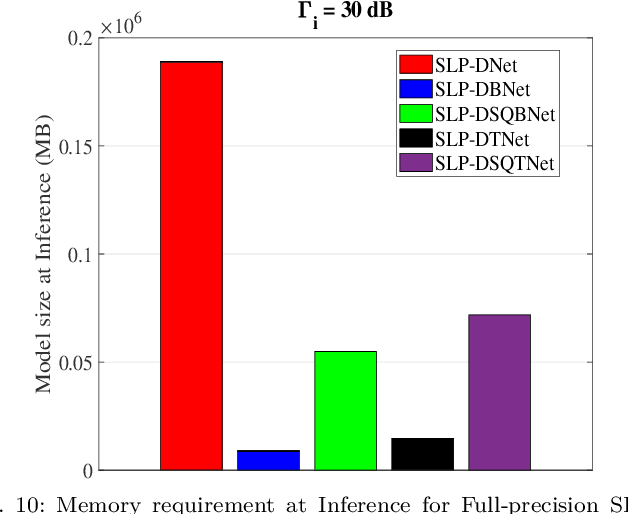
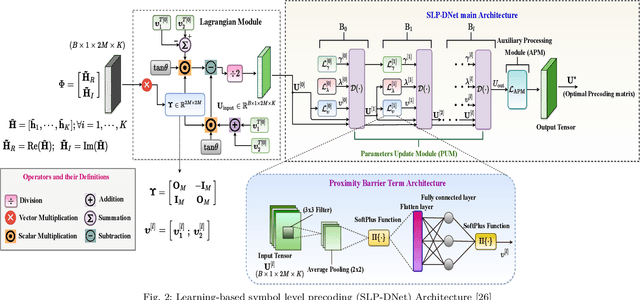
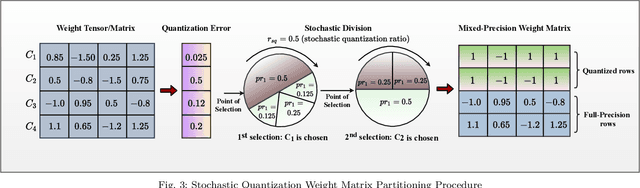
This paper proposes a memory-efficient deep neural network (DNN) framework-based symbol level precoding (SLP). We focus on a DNN with realistic finite precision weights and adopt an unsupervised deep learning (DL) based SLP model (SLP-DNet). We apply a stochastic quantization (SQ) technique to obtain its corresponding quantized version called SLP-SQDNet. The proposed scheme offers a scalable performance vs memory tradeoff, by quantizing a scale-able percentage of the DNN weights, and we explore binary and ternary quantizations. Our results show that while SLP-DNet provides near-optimal performance, its quantized versions through SQ yield 3.46x and 2.64x model compression for binary-based and ternary-based SLP-SQDNets, respectively. We also find that our proposals offer 20x and 10x computational complexity reductions compared to SLP optimization-based and SLP-DNet, respectively.