 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRO-SPECT: Probabilistically Safe Scalable Planning for Energy-Aware Coordinated UAV-UGV Teams in Stochastic Environments
Apr 02, 2026We consider energy-aware planning for an unmanned aerial vehicle (UAV) and unmanned ground vehicle (UGV) team operating in a stochastic environment. The UAV must visit a set of air points in minimum time while respecting energy constraints, relying on the UGV as a mobile charging station. Unlike prior work that assumed deterministic travel times or used fixed robustness margins, we model travel times as random variables and bound the probability of failure (energy depletion) across the entire mission to a user-specified risk level. We formulate the problem as a Mixed-Integer Program and propose PRO-SPECT, a polynomial-time algorithm that generates risk-bounded plans. The algorithm supports both offline planning and online re-planning, enabling the team to adapt to disturbances while preserving the risk bound. We provide theoretical results on solution feasibility and time complexity. We also demonstrate the performance of our method via numerical comparisons and simulations.
Energy-Aware Collaborative Exploration for a UAV-UGV Team
Mar 23, 2026We present an energy-aware collaborative exploration framework for a UAV-UGV team operating in unknown environments, where the UAV's energy constraint is modeled as a maximum flight-time limit. The UAV executes a sequence of energy-bounded exploration tours, while the UGV simultaneously explores on the ground and serves as a mobile charging station. Rendezvous is enforced under a shared time budget so that the vehicles meet at the end of each tour before the UAV reaches its flight-time limit. We construct a sparsely coupled air-ground roadmap using a density-aware layered probabilistic roadmap (PRM) and formulate tour selection over the roadmap as coupled orienteering problems (OPs) to maximize information gain subject to the rendezvous constraint. The resulting tours are constructed over collision-validated roadmap edges. We validate our method through simulation studies, benchmark comparisons, and real-world experiments.
Reinforcement Learning Under Probabilistic Spatio-Temporal Constraints with Time Windows
Jul 29, 2023We propose an automata-theoretic approach for reinforcement learning (RL) under complex spatio-temporal constraints with time windows. The problem is formulated using a Markov decision process under a bounded temporal logic constraint. Different from existing RL methods that can eventually learn optimal policies satisfying such constraints, our proposed approach enforces a desired probability of constraint satisfaction throughout learning. This is achieved by translating the bounded temporal logic constraint into a total automaton and avoiding "unsafe" actions based on the available prior information regarding the transition probabilities, i.e., a pair of upper and lower bounds for each transition probability. We provide theoretical guarantees on the resulting probability of constraint satisfaction. We also provide numerical results in a scenario where a robot explores the environment to discover high-reward regions while fulfilling some periodic pick-up and delivery tasks that are encoded as temporal logic constraints.
Distributed Planning for Serving Cooperative Tasks with Time Windows: A Game Theoretic Approach
Jul 18, 2021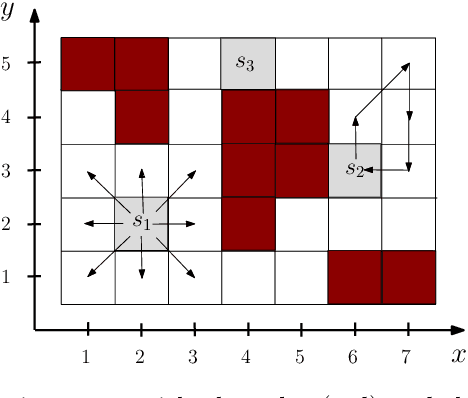
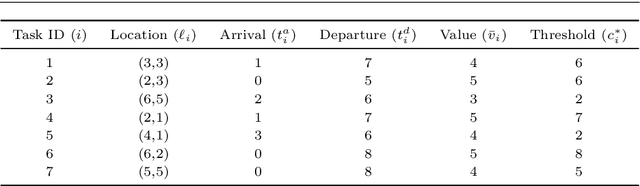
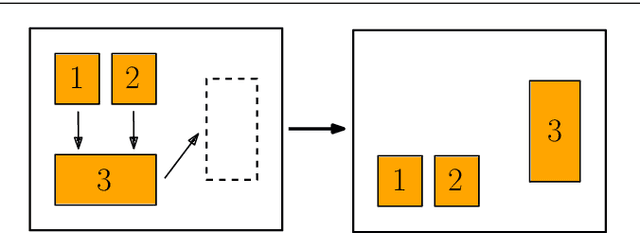
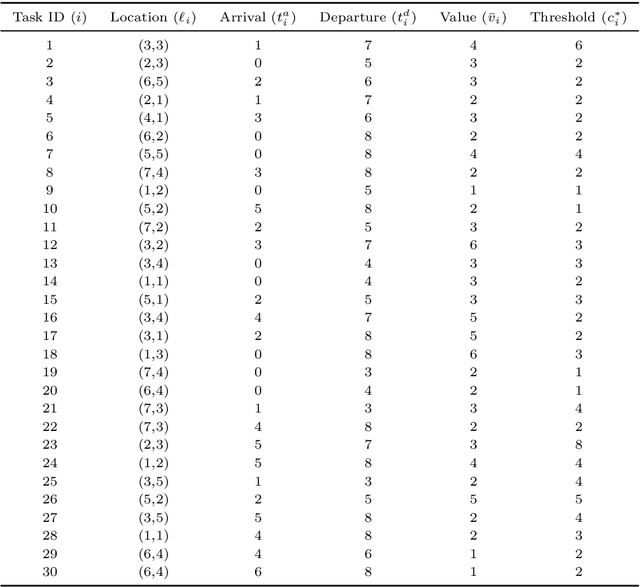
We study distributed planning for multi-robot systems to provide optimal service to cooperative tasks that are distributed over space and time. Each task requires service by sufficiently many robots at the specified location within the specified time window. Tasks arrive over episodes and the robots try to maximize the total value of service in each episode by planning their own trajectories based on the specifications of incoming tasks. Robots are required to start and end each episode at their assigned stations in the environment. We present a game theoretic solution to this problem by mapping it to a game, where the action of each robot is its trajectory in an episode, and using a suitable learning algorithm to obtain optimal joint plans in a distributed manner. We present a systematic way to design minimal action sets (subsets of feasible trajectories) for robots based on the specifications of incoming tasks to facilitate fast learning. We then provide the performance guarantees for the cases where all the robots follow a best response or noisy best response algorithm to iteratively plan their trajectories. While the best response algorithm leads to a Nash equilibrium, the noisy best response algorithm leads to globally optimal joint plans with high probability. We show that the proposed game can in general have arbitrarily poor Nash equilibria, which makes the noisy best response algorithm preferable unless the task specifications are known to have some special structure. We also describe a family of special cases where all the equilibria are guaranteed to have bounded suboptimality. Simulations and experimental results are provided to demonstrate the proposed approach.
Probabilistically Guaranteed Satisfaction of Temporal Logic Constraints During Reinforcement Learning
Feb 19, 2021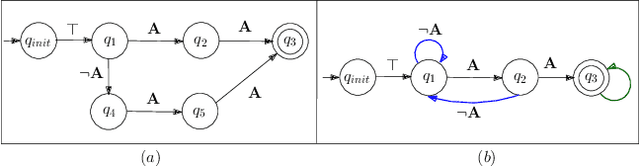
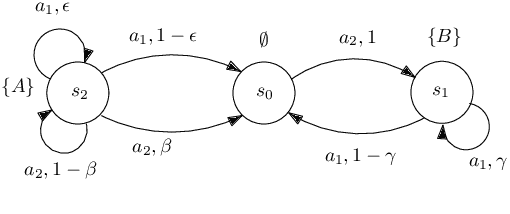
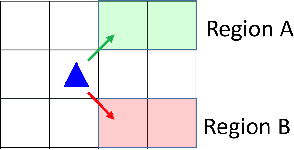
We present a novel reinforcement learning algorithm for finding optimal policies in Markov Decision Processes while satisfying temporal logic constraints with a desired probability throughout the learning process. An automata-theoretic approach is proposed to ensure probabilistic satisfaction of the constraint in each episode, which is different from penalizing violations to achieve constraint satisfaction after a sufficiently large number of episodes. The proposed approach is based on computing a lower bound on the probability of constraint satisfaction and adjusting the exploration behavior as needed. We present theoretical results on the probabilistic constraint satisfaction achieved by the proposed approach. We also numerically demonstrate the proposed idea in a drone scenario, where the constraint is to perform periodically arriving pick-up and delivery tasks and the objective is to fly over high-reward zones to simultaneously perform aerial monitoring.
Decentralized Safe Reactive Planning under TWTL Specifications
Jul 23, 2020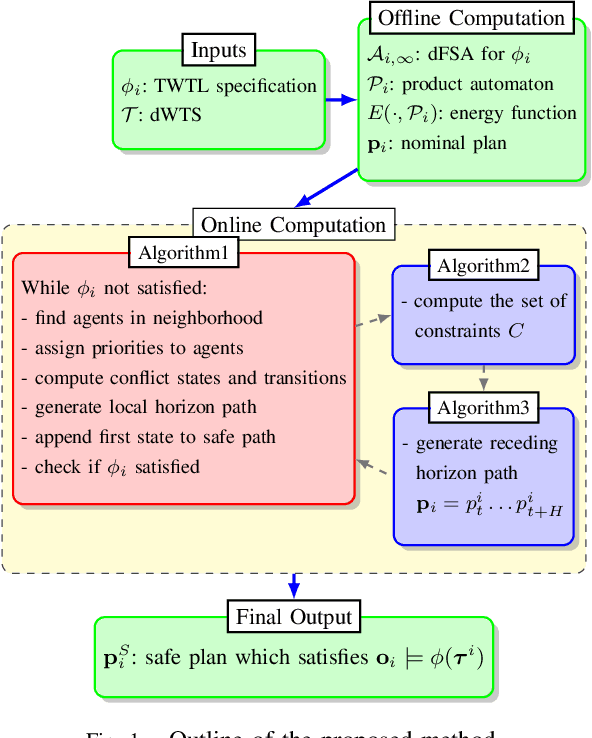



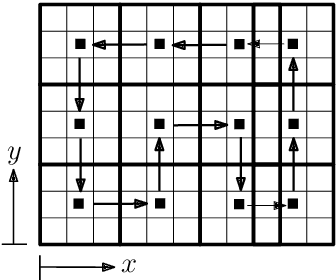
We investigate a multi-agent planning problem, where each agent aims to achieve an individual task while avoiding collisions with others. We assume that each agent's task is expressed as a Time-Window Temporal Logic (TWTL) specification defined over a 3D environment. We propose a decentralized receding horizon algorithm for online planning of trajectories. We show that when the environment is sufficiently connected, the resulting agent trajectories are always safe (collision-free) and lead to the satisfaction of the TWTL specifications or their finite temporal relaxations. Accordingly, deadlocks are always avoided and each agent is guaranteed to safely achieve its task with a finite time-delay in the worst case. Performance of the proposed algorithm is demonstrated via numerical simulations and experiments with quadrotors.
Persistent Surveillance With Energy-Constrained UAVs and Mobile Charging Stations
Aug 15, 2019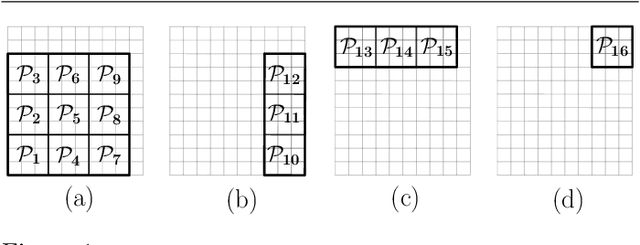
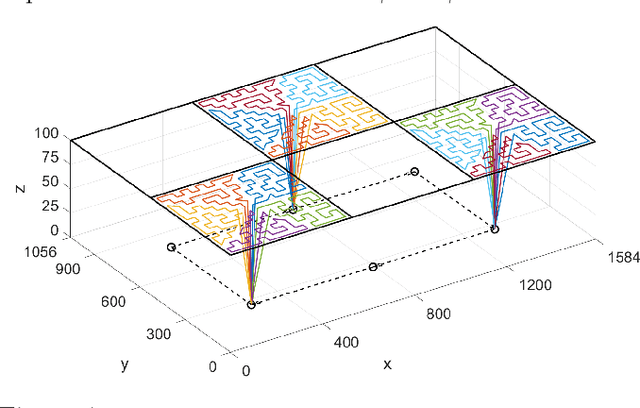
We address the problem of achieving persistent surveillance over an environment by using energy-constrained unmanned aerial vehicles (UAVs), which are supported by unmanned ground vehicles (UGVs) serving as mobile charging stations. Specifically, we plan the trajectories of all vehicles and the charging schedule of UAVs to minimize the long-term maximum age, where age is defined as the time between two consecutive visits to regions of interest in a partitioned environment. We introduce a scalable planning strategy based on 1) creating UAV- UGV teams, 2) decomposing the environment into optimal partitions that can be covered by any of the teams in a single fuel cycle, 3) uniformly distributing the teams over a cyclic path traversing those partitions, and 4) having the UAVs in each team cover their current partition and be transported to the next partition while being recharged by the UGV. We show some results related to the safety and performance of the proposed strategy.
Distributed Path Planning for Executing Cooperative Tasks with Time Windows
Aug 15, 2019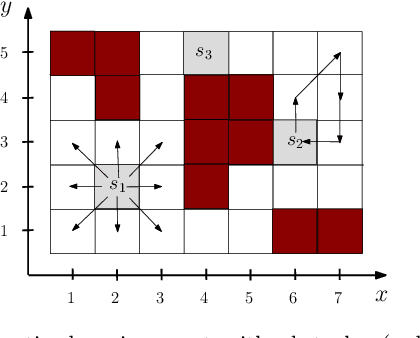
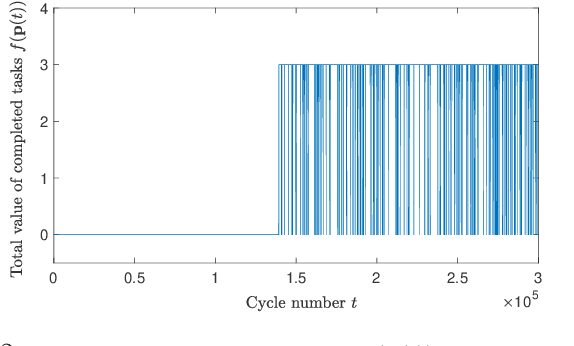
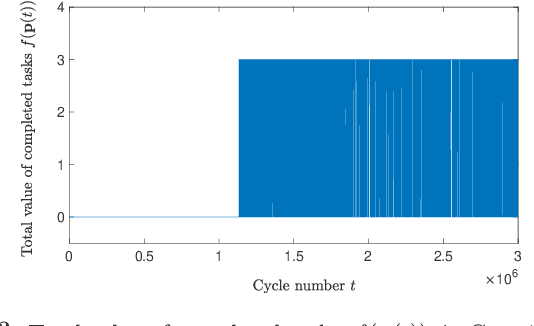
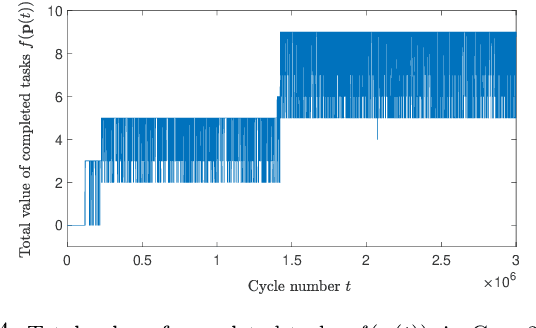
We investigate the distributed planning of robot trajectories for optimal execution of cooperative tasks with time windows. In this setting, each task has a value and is completed if sufficiently many robots are simultaneously present at the necessary location within the specified time window. Tasks keep arriving periodically over cycles. The task specifications (required number of robots, location, time window, and value) are unknown a priori and the robots try to maximize the value of completed tasks by planning their own trajectories for the upcoming cycle based on their past observations in a distributed manner. Considering the recharging and maintenance needs, robots are required to start and end each cycle at their assigned stations located in the environment. We map this problem to a game theoretic formulation and maximize the collective performance through distributed learning. Some simulation results are also provided to demonstrate the performance of the proposed approach.