 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistically Guaranteed Satisfaction of Temporal Logic Constraints During Reinforcement Learning
Feb 19, 2021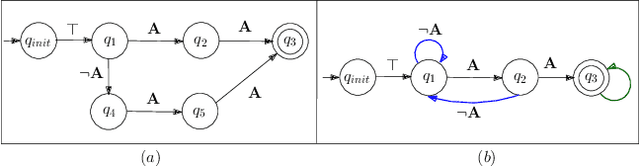
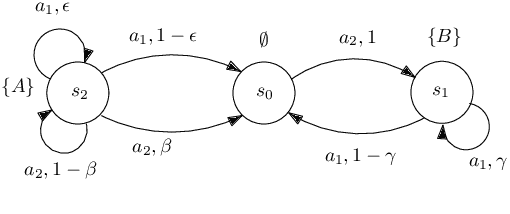
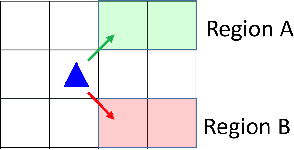
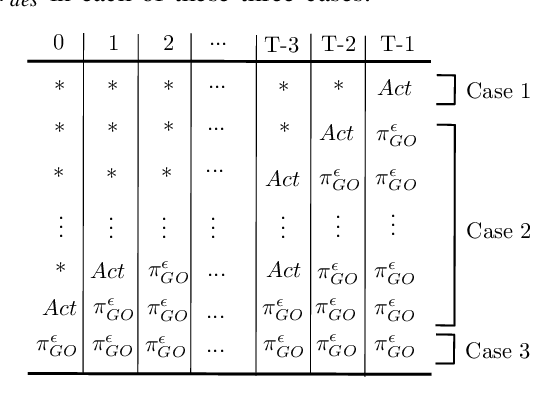
We present a novel reinforcement learning algorithm for finding optimal policies in Markov Decision Processes while satisfying temporal logic constraints with a desired probability throughout the learning process. An automata-theoretic approach is proposed to ensure probabilistic satisfaction of the constraint in each episode, which is different from penalizing violations to achieve constraint satisfaction after a sufficiently large number of episodes. The proposed approach is based on computing a lower bound on the probability of constraint satisfaction and adjusting the exploration behavior as needed. We present theoretical results on the probabilistic constraint satisfaction achieved by the proposed approach. We also numerically demonstrate the proposed idea in a drone scenario, where the constraint is to perform periodically arriving pick-up and delivery tasks and the objective is to fly over high-reward zones to simultaneously perform aerial monitoring.