 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Prior Learning via Neural Architecture Search for Blind Face Restoration
Jun 28, 2022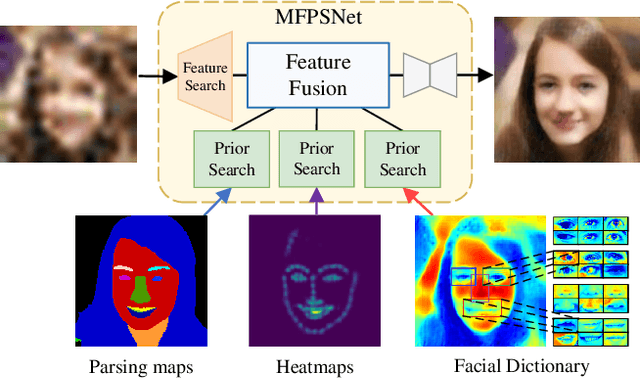
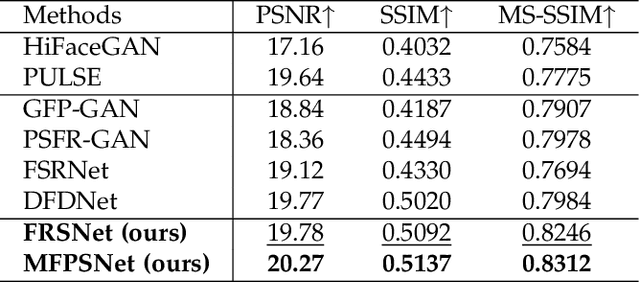
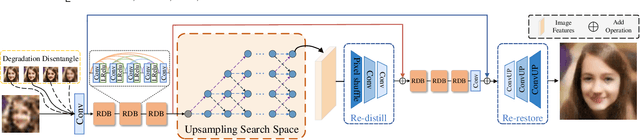
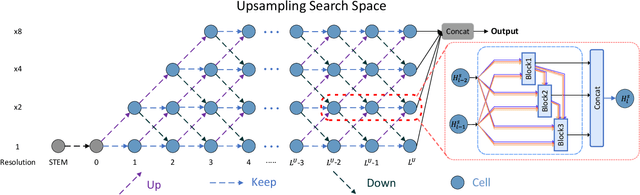
Blind Face Restoration (BFR) aims to recover high-quality face images from low-quality ones and usually resorts to facial priors for improving restoration performance. However, current methods still suffer from two major difficulties: 1) how to derive a powerful network architecture without extensive hand tuning; 2) how to capture complementary information from multiple facial priors in one network to improve restoration performance. To this end, we propose a Face Restoration Searching Network (FRSNet) to adaptively search the suitable feature extraction architecture within our specified search space, which can directly contribute to the restoration quality. On the basis of FRSNet, we further design our Multiple Facial Prior Searching Network (MFPSNet) with a multi-prior learning scheme. MFPSNet optimally extracts information from diverse facial priors and fuses the information into image features, ensuring that both external guidance and internal features are reserved. In this way, MFPSNet takes full advantage of semantic-level (parsing maps), geometric-level (facial heatmaps), reference-level (facial dictionaries) and pixel-level (degraded images) information and thus generates faithful and realistic images. Quantitative and qualitative experiments show that MFPSNet performs favorably on both synthetic and real-world datasets against the state-of-the-art BFR methods. The codes are publicly available at: https://github.com/YYJ1anG/MFPSNet.
Beyond Monocular Deraining: Parallel Stereo Deraining Network Via Semantic Prior
May 09, 2021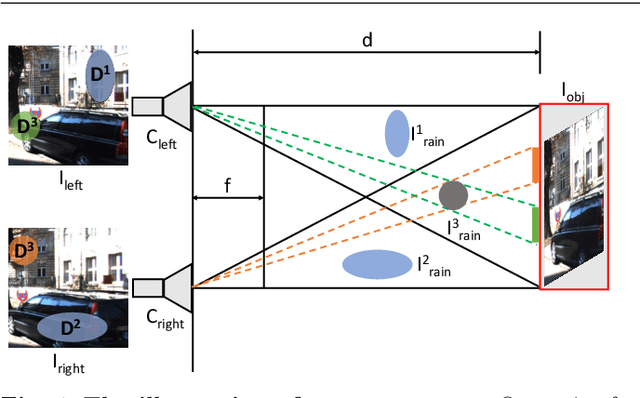
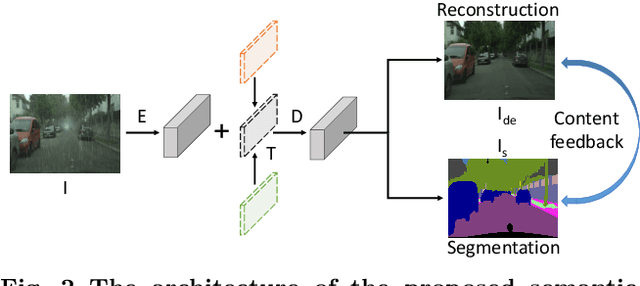

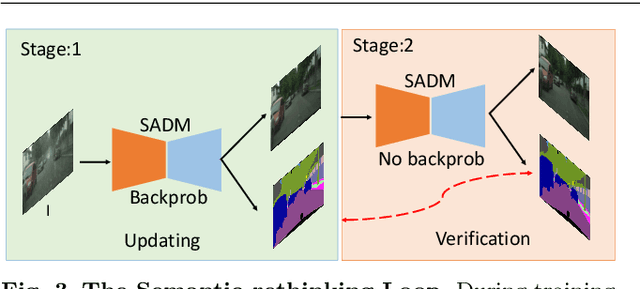
Rain is a common natural phenomenon. Taking images in the rain however often results in degraded quality of images, thus compromises the performance of many computer vision systems. Most existing de-rain algorithms use only one single input image and aim to recover a clean image. Few work has exploited stereo images. Moreover, even for single image based monocular deraining, many current methods fail to complete the task satisfactorily because they mostly rely on per pixel loss functions and ignore semantic information. In this paper, we present a Paired Rain Removal Network (PRRNet), which exploits both stereo images and semantic information. Specifically, we develop a Semantic-Aware Deraining Module (SADM) which solves both tasks of semantic segmentation and deraining of scenes, and a Semantic-Fusion Network (SFNet) and a View-Fusion Network (VFNet) which fuse semantic information and multi-view information respectively. In addition, we also introduce an Enhanced Paired Rain Removal Network (EPRRNet) which exploits semantic prior to remove rain streaks from stereo images. We first use a coarse deraining network to reduce the rain streaks on the input images, and then adopt a pre-trained semantic segmentation network to extract semantic features from the coarse derained image. Finally, a parallel stereo deraining network fuses semantic and multi-view information to restore finer results. We also propose new stereo based rainy datasets for benchmarking. Experiments on both monocular and the newly proposed stereo rainy datasets demonstrate that the proposed method achieves the state-of-the-art performance.
Deep Dense Multi-scale Network for Snow Removal Using Semantic and Geometric Priors
Mar 21, 2021
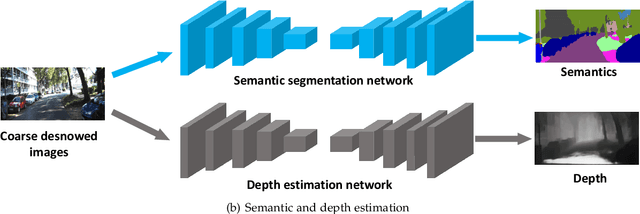
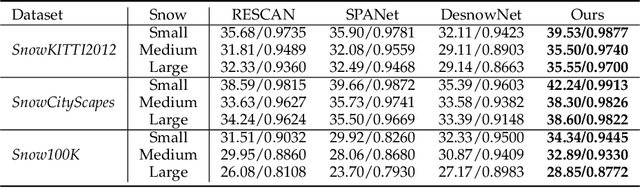
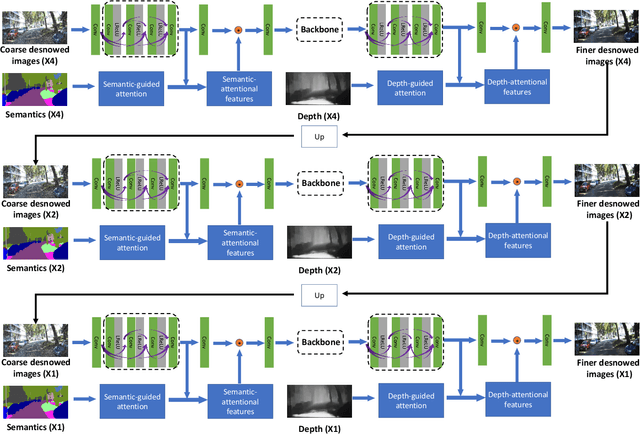
Images captured in snowy days suffer from noticeable degradation of scene visibility, which degenerates the performance of current vision-based intelligent systems. Removing snow from images thus is an important topic in computer vision. In this paper, we propose a Deep Dense Multi-Scale Network (\textbf{DDMSNet}) for snow removal by exploiting semantic and geometric priors. As images captured in outdoor often share similar scenes and their visibility varies with depth from camera, such semantic and geometric information provides a strong prior for snowy image restoration. We incorporate the semantic and geometric maps as input and learn the semantic-aware and geometry-aware representation to remove snow. In particular, we first create a coarse network to remove snow from the input images. Then, the coarsely desnowed images are fed into another network to obtain the semantic and geometric labels. Finally, we design a DDMSNet to learn semantic-aware and geometry-aware representation via a self-attention mechanism to produce the final clean images. Experiments evaluated on public synthetic and real-world snowy images verify the superiority of the proposed method, offering better results both quantitatively and qualitatively.