 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Prior Learning via Neural Architecture Search for Blind Face Restoration
Jun 28, 2022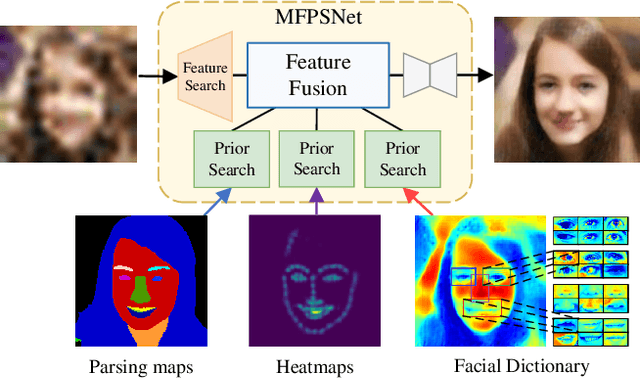
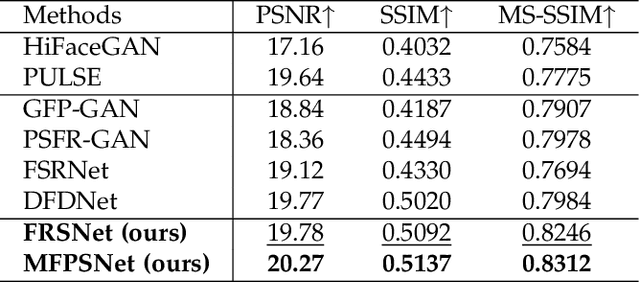
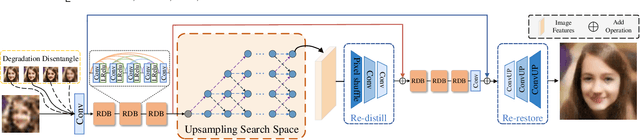
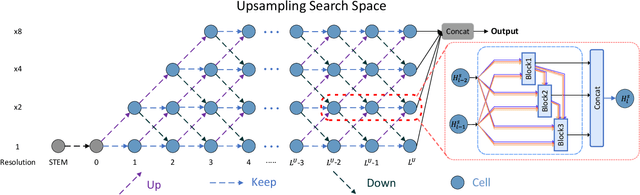
Blind Face Restoration (BFR) aims to recover high-quality face images from low-quality ones and usually resorts to facial priors for improving restoration performance. However, current methods still suffer from two major difficulties: 1) how to derive a powerful network architecture without extensive hand tuning; 2) how to capture complementary information from multiple facial priors in one network to improve restoration performance. To this end, we propose a Face Restoration Searching Network (FRSNet) to adaptively search the suitable feature extraction architecture within our specified search space, which can directly contribute to the restoration quality. On the basis of FRSNet, we further design our Multiple Facial Prior Searching Network (MFPSNet) with a multi-prior learning scheme. MFPSNet optimally extracts information from diverse facial priors and fuses the information into image features, ensuring that both external guidance and internal features are reserved. In this way, MFPSNet takes full advantage of semantic-level (parsing maps), geometric-level (facial heatmaps), reference-level (facial dictionaries) and pixel-level (degraded images) information and thus generates faithful and realistic images. Quantitative and qualitative experiments show that MFPSNet performs favorably on both synthetic and real-world datasets against the state-of-the-art BFR methods. The codes are publicly available at: https://github.com/YYJ1anG/MFPSNet.
Blind Face Restoration: Benchmark Datasets and a Baseline Model
Jun 08, 2022
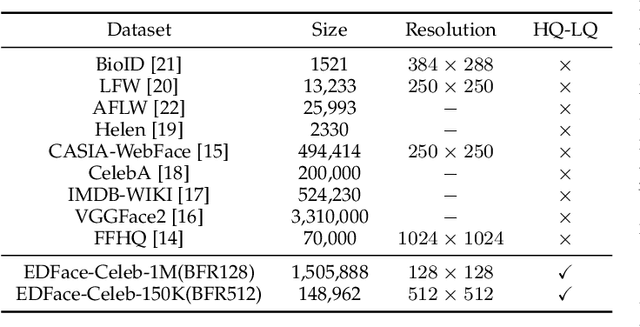


Blind Face Restoration (BFR) aims to construct a high-quality (HQ) face image from its corresponding low-quality (LQ) input. Recently, many BFR methods have been proposed and they have achieved remarkable success. However, these methods are trained or evaluated on privately synthesized datasets, which makes it infeasible for the subsequent approaches to fairly compare with them. To address this problem, we first synthesize two blind face restoration benchmark datasets called EDFace-Celeb-1M (BFR128) and EDFace-Celeb-150K (BFR512). State-of-the-art methods are benchmarked on them under five settings including blur, noise, low resolution, JPEG compression artifacts, and the combination of them (full degradation). To make the comparison more comprehensive, five widely-used quantitative metrics and two task-driven metrics including Average Face Landmark Distance (AFLD) and Average Face ID Cosine Similarity (AFICS) are applied. Furthermore, we develop an effective baseline model called Swin Transformer U-Net (STUNet). The STUNet with U-net architecture applies an attention mechanism and a shifted windowing scheme to capture long-range pixel interactions and focus more on significant features while still being trained efficiently. Experimental results show that the proposed baseline method performs favourably against the SOTA methods on various BFR tasks.