 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative AI in Transportation Planning: A Survey
Mar 10, 2025

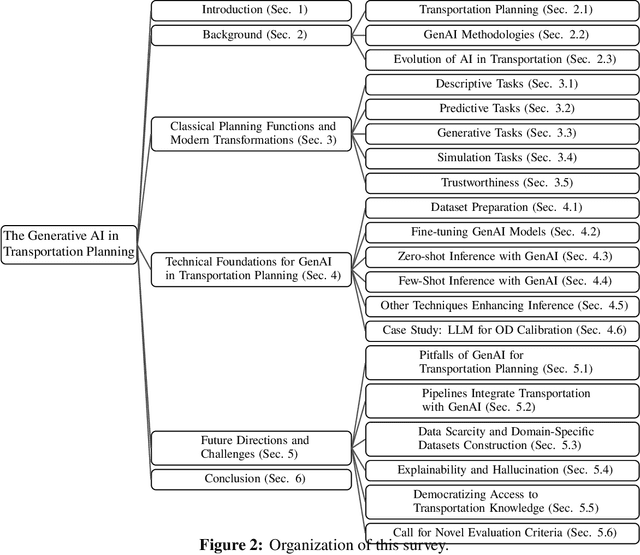
The integration of generative artificial intelligence (GenAI) into transportation planning has the potential to revolutionize tasks such as demand forecasting, infrastructure design, policy evaluation, and traffic simulation. However, there is a critical need for a systematic framework to guide the adoption of GenAI in this interdisciplinary domain. In this survey, we, a multidisciplinary team of researchers spanning computer science and transportation engineering, present the first comprehensive framework for leveraging GenAI in transportation planning. Specifically, we introduce a new taxonomy that categorizes existing applications and methodologies into two perspectives: transportation planning tasks and computational techniques. From the transportation planning perspective, we examine the role of GenAI in automating descriptive, predictive, generative, simulation, and explainable tasks to enhance mobility systems. From the computational perspective, we detail advancements in data preparation, domain-specific fine-tuning, and inference strategies, such as retrieval-augmented generation and zero-shot learning tailored to transportation applications. Additionally, we address critical challenges, including data scarcity, explainability, bias mitigation, and the development of domain-specific evaluation frameworks that align with transportation goals like sustainability, equity, and system efficiency. This survey aims to bridge the gap between traditional transportation planning methodologies and modern AI techniques, fostering collaboration and innovation. By addressing these challenges and opportunities, we seek to inspire future research that ensures ethical, equitable, and impactful use of generative AI in transportation planning.
SEVD: Synthetic Event-based Vision Dataset for Ego and Fixed Traffic Perception
Apr 12, 2024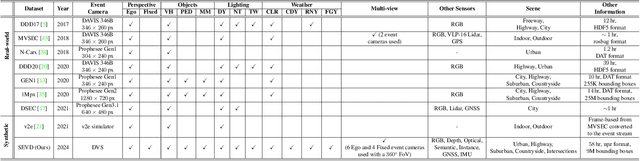
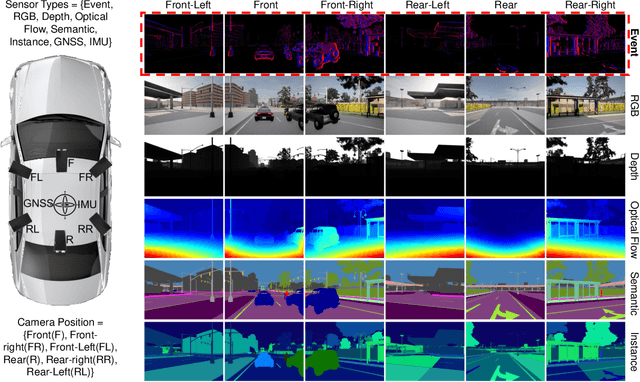
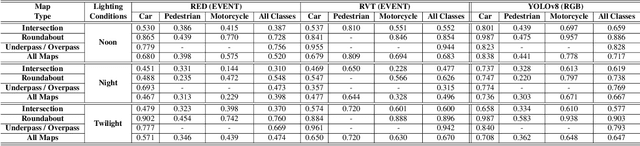

Recently, event-based vision sensors have gained attention for autonomous driving applications, as conventional RGB cameras face limitations in handling challenging dynamic conditions. However, the availability of real-world and synthetic event-based vision datasets remains limited. In response to this gap, we present SEVD, a first-of-its-kind multi-view ego, and fixed perception synthetic event-based dataset using multiple dynamic vision sensors within the CARLA simulator. Data sequences are recorded across diverse lighting (noon, nighttime, twilight) and weather conditions (clear, cloudy, wet, rainy, foggy) with domain shifts (discrete and continuous). SEVD spans urban, suburban, rural, and highway scenes featuring various classes of objects (car, truck, van, bicycle, motorcycle, and pedestrian). Alongside event data, SEVD includes RGB imagery, depth maps, optical flow, semantic, and instance segmentation, facilitating a comprehensive understanding of the scene. Furthermore, we evaluate the dataset using state-of-the-art event-based (RED, RVT) and frame-based (YOLOv8) methods for traffic participant detection tasks and provide baseline benchmarks for assessment. Additionally, we conduct experiments to assess the synthetic event-based dataset's generalization capabilities. The dataset is available at https://eventbasedvision.github.io/SEVD
Open-TI: Open Traffic Intelligence with Augmented Language Model
Dec 30, 2023Transportation has greatly benefited the cities' development in the modern civilization process. Intelligent transportation, leveraging advanced computer algorithms, could further increase people's daily commuting efficiency. However, intelligent transportation, as a cross-discipline, often requires practitioners to comprehend complicated algorithms and obscure neural networks, bringing a challenge for the advanced techniques to be trusted and deployed in practical industries. Recognizing the expressiveness of the pre-trained large language models, especially the potential of being augmented with abilities to understand and execute intricate commands, we introduce Open-TI. Serving as a bridge to mitigate the industry-academic gap, Open-TI is an innovative model targeting the goal of Turing Indistinguishable Traffic Intelligence, it is augmented with the capability to harness external traffic analysis packages based on existing conversations. Marking its distinction, Open-TI is the first method capable of conducting exhaustive traffic analysis from scratch - spanning from map data acquisition to the eventual execution in complex simulations. Besides, Open-TI is able to conduct task-specific embodiment like training and adapting the traffic signal control policies (TSC), explore demand optimizations, etc. Furthermore, we explored the viability of LLMs directly serving as control agents, by understanding the expected intentions from Open-TI, we designed an agent-to-agent communication mode to support Open-TI conveying messages to ChatZero (control agent), and then the control agent would choose from the action space to proceed the execution. We eventually provide the formal implementation structure, and the open-ended design invites further community-driven enhancements.