 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Hardness of Vision-Language Compositionality from A Token-level Causal Lens
Oct 30, 2025Contrastive Language-Image Pre-training (CLIP) delivers strong cross modal generalization by aligning images and texts in a shared embedding space, yet it persistently fails at compositional reasoning over objects, attributes, and relations often behaving like a bag-of-words matcher. Prior causal accounts typically model text as a single vector, obscuring token-level structure and leaving core phenomena-such as prompt sensitivity and failures on hard negatives unexplained. We address this gap with a token-aware causal representation learning (CRL) framework grounded in a sequential, language-token SCM. Our theory extends block identifiability to tokenized text, proving that CLIP's contrastive objective can recover the modal-invariant latent variable under both sentence-level and token-level SCMs. Crucially, token granularity yields the first principled explanation of CLIP's compositional brittleness: composition nonidentifiability. We show the existence of pseudo-optimal text encoders that achieve perfect modal-invariant alignment yet are provably insensitive to SWAP, REPLACE, and ADD operations over atomic concepts, thereby failing to distinguish correct captions from hard negatives despite optimizing the same training objective as true-optimal encoders. The analysis further links language-side nonidentifiability to visual-side failures via the modality gap and shows how iterated composition operators compound hardness, motivating improved negative mining strategies.
Structure-Preserving 3D Garment Modeling with Neural Sewing Machines
Nov 12, 2022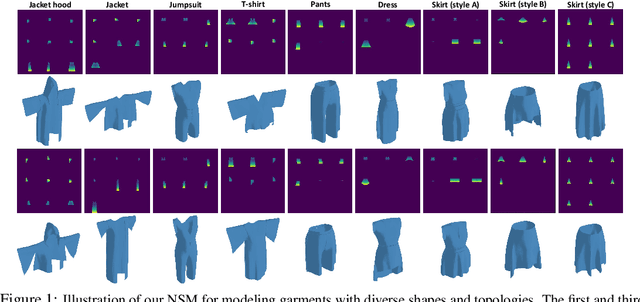

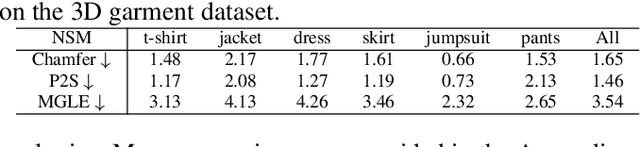
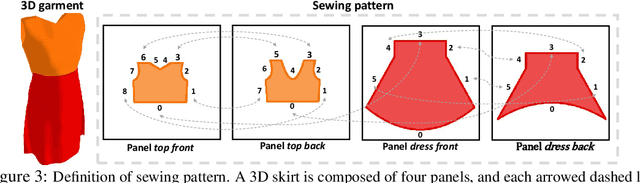
3D Garment modeling is a critical and challenging topic in the area of computer vision and graphics, with increasing attention focused on garment representation learning, garment reconstruction, and controllable garment manipulation, whereas existing methods were constrained to model garments under specific categories or with relatively simple topologies. In this paper, we propose a novel Neural Sewing Machine (NSM), a learning-based framework for structure-preserving 3D garment modeling, which is capable of learning representations for garments with diverse shapes and topologies and is successfully applied to 3D garment reconstruction and controllable manipulation. To model generic garments, we first obtain sewing pattern embedding via a unified sewing pattern encoding module, as the sewing pattern can accurately describe the intrinsic structure and the topology of the 3D garment. Then we use a 3D garment decoder to decode the sewing pattern embedding into a 3D garment using the UV-position maps with masks. To preserve the intrinsic structure of the predicted 3D garment, we introduce an inner-panel structure-preserving loss, an inter-panel structure-preserving loss, and a surface-normal loss in the learning process of our framework. We evaluate NSM on the public 3D garment dataset with sewing patterns with diverse garment shapes and categories. Extensive experiments demonstrate that the proposed NSM is capable of representing 3D garments under diverse garment shapes and topologies, realistically reconstructing 3D garments from 2D images with the preserved structure, and accurately manipulating the 3D garment categories, shapes, and topologies, outperforming the state-of-the-art methods by a clear margin.
Weakly-Supervised Discovery of Geometry-Aware Representation for 3D Human Pose Estimation
Mar 27, 2019



Recent studies have shown remarkable advances in 3D human pose estimation from monocular images, with the help of large-scale in-door 3D datasets and sophisticated network architectures. However, the generalizability to different environments remains an elusive goal. In this work, we propose a geometry-aware 3D representation for the human pose to address this limitation by using multiple views in a simple auto-encoder model at the training stage and only 2D keypoint information as supervision. A view synthesis framework is proposed to learn the shared 3D representation between viewpoints with synthesizing the human pose from one viewpoint to the other one. Instead of performing a direct transfer in the raw image-level, we propose a skeleton-based encoder-decoder mechanism to distil only pose-related representation in the latent space. A learning-based representation consistency constraint is further introduced to facilitate the robustness of latent 3D representation. Since the learnt representation encodes 3D geometry information, mapping it to 3D pose will be much easier than conventional frameworks that use an image or 2D coordinates as the input of 3D pose estimator. We demonstrate our approach on the task of 3D human pose estimation. Comprehensive experiments on three popular benchmarks show that our model can significantly improve the performance of state-of-the-art methods with simply injecting the representation as a robust 3D prior.
DRPose3D: Depth Ranking in 3D Human Pose Estimation
May 24, 2018

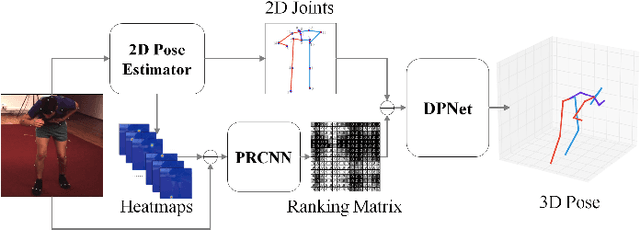

In this paper, we propose a two-stage depth ranking based method (DRPose3D) to tackle the problem of 3D human pose estimation. Instead of accurate 3D positions, the depth ranking can be identified by human intuitively and learned using the deep neural network more easily by solving classification problems. Moreover, depth ranking contains rich 3D information. It prevents the 2D-to-3D pose regression in two-stage methods from being ill-posed. In our method, firstly, we design a Pairwise Ranking Convolutional Neural Network (PRCNN) to extract depth rankings of human joints from images. Secondly, a coarse-to-fine 3D Pose Network(DPNet) is proposed to estimate 3D poses from both depth rankings and 2D human joint locations. Additionally, to improve the generality of our model, we introduce a statistical method to augment depth rankings. Our approach outperforms the state-of-the-art methods in the Human3.6M benchmark for all three testing protocols, indicating that depth ranking is an essential geometric feature which can be learned to improve the 3D pose estimation.