 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVTONQA: A Multi-Dimensional Quality Assessment Dataset for Virtual Try-on
Jan 06, 2026With the rapid development of e-commerce and digital fashion, image-based virtual try-on (VTON) has attracted increasing attention. However, existing VTON models often suffer from artifacts such as garment distortion and body inconsistency, highlighting the need for reliable quality evaluation of VTON-generated images. To this end, we construct VTONQA, the first multi-dimensional quality assessment dataset specifically designed for VTON, which contains 8,132 images generated by 11 representative VTON models, along with 24,396 mean opinion scores (MOSs) across three evaluation dimensions (i.e., clothing fit, body compatibility, and overall quality). Based on VTONQA, we benchmark both VTON models and a diverse set of image quality assessment (IQA) metrics, revealing the limitations of existing methods and highlighting the value of the proposed dataset. We believe that the VTONQA dataset and corresponding benchmarks will provide a solid foundation for perceptually aligned evaluation, benefiting both the development of quality assessment methods and the advancement of VTON models.
IllusionBench: A Large-scale and Comprehensive Benchmark for Visual Illusion Understanding in Vision-Language Models
Jan 01, 2025



Current Visual Language Models (VLMs) show impressive image understanding but struggle with visual illusions, especially in real-world scenarios. Existing benchmarks focus on classical cognitive illusions, which have been learned by state-of-the-art (SOTA) VLMs, revealing issues such as hallucinations and limited perceptual abilities. To address this gap, we introduce IllusionBench, a comprehensive visual illusion dataset that encompasses not only classic cognitive illusions but also real-world scene illusions. This dataset features 1,051 images, 5,548 question-answer pairs, and 1,051 golden text descriptions that address the presence, causes, and content of the illusions. We evaluate ten SOTA VLMs on this dataset using true-or-false, multiple-choice, and open-ended tasks. In addition to real-world illusions, we design trap illusions that resemble classical patterns but differ in reality, highlighting hallucination issues in SOTA models. The top-performing model, GPT-4o, achieves 80.59% accuracy on true-or-false tasks and 76.75% on multiple-choice questions, but still lags behind human performance. In the semantic description task, GPT-4o's hallucinations on classical illusions result in low scores for trap illusions, even falling behind some open-source models. IllusionBench is, to the best of our knowledge, the largest and most comprehensive benchmark for visual illusions in VLMs to date.
Deep Unfolding with Normalizing Flow Priors for Inverse Problems
Jul 06, 2021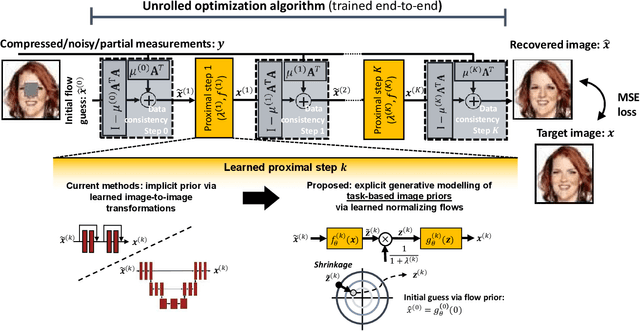


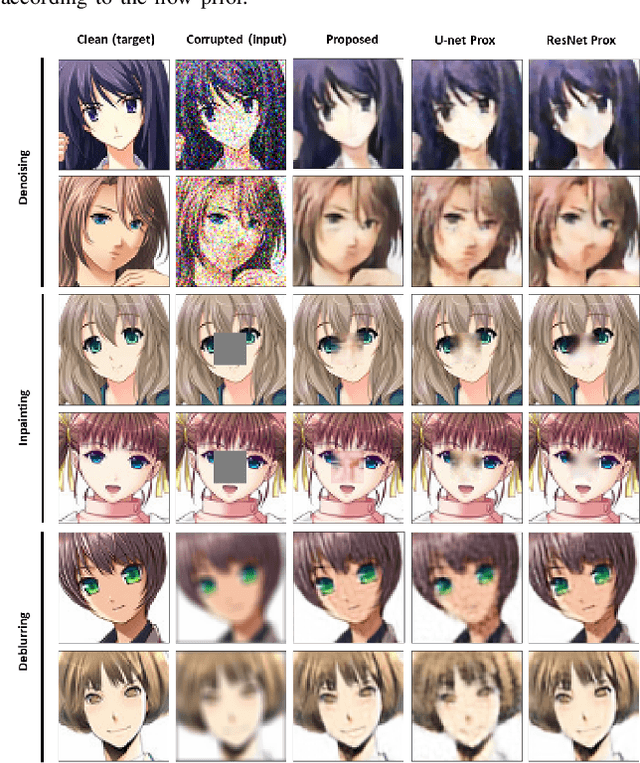
Many application domains, spanning from computational photography to medical imaging, require recovery of high-fidelity images from noisy, incomplete or partial/compressed measurements. State of the art methods for solving these inverse problems combine deep learning with iterative model-based solvers, a concept known as deep algorithm unfolding. By combining a-priori knowledge of the forward measurement model with learned (proximal) mappings based on deep networks, these methods yield solutions that are both physically feasible (data-consistent) and perceptually plausible. However, current proximal mappings only implicitly learn such image priors. In this paper, we propose to make these image priors fully explicit by embedding deep generative models in the form of normalizing flows within the unfolded proximal gradient algorithm. We demonstrate that the proposed method outperforms competitive baselines on various image recovery tasks, spanning from image denoising to inpainting and deblurring.