 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Phase Competition for Traffic Signal Control
May 12, 2019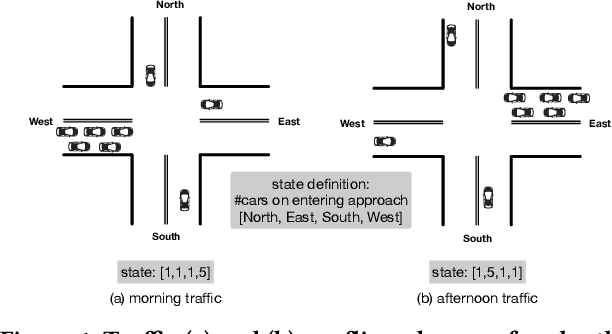
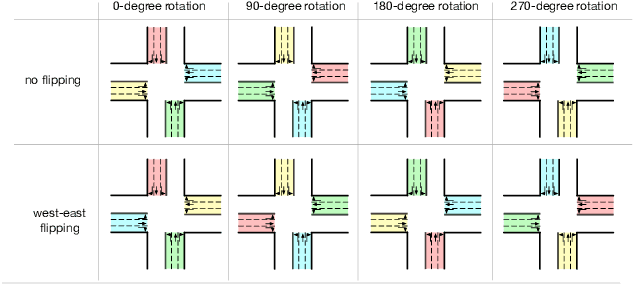
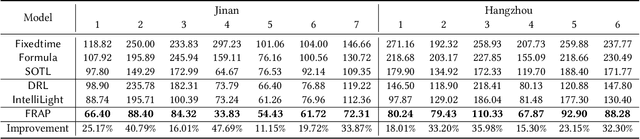
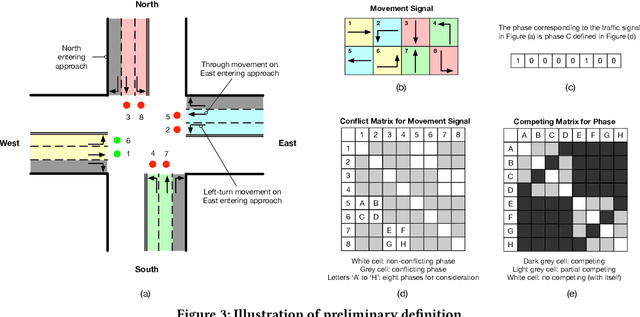
Increasingly available city data and advanced learning techniques have empowered people to improve the efficiency of our city functions. Among them, improving the urban transportation efficiency is one of the most prominent topics. Recent studies have proposed to use reinforcement learning (RL) for traffic signal control. Different from traditional transportation approaches which rely heavily on prior knowledge, RL can learn directly from the feedback. On the other side, without a careful model design, existing RL methods typically take a long time to converge and the learned models may not be able to adapt to new scenarios. For example, a model that is trained well for morning traffic may not work for the afternoon traffic because the traffic flow could be reversed, resulting in a very different state representation. In this paper, we propose a novel design called FRAP, which is based on the intuitive principle of phase competition in traffic signal control: when two traffic signals conflict, priority should be given to one with larger traffic movement (i.e., higher demand). Through the phase competition modeling, our model achieves invariance to symmetrical cases such as flipping and rotation in traffic flow. By conducting comprehensive experiments, we demonstrate that our model finds better solutions than existing RL methods in the complicated all-phase selection problem, converges much faster during training, and achieves superior generalizability for different road structures and traffic conditions.
Diagnosing Reinforcement Learning for Traffic Signal Control
May 12, 2019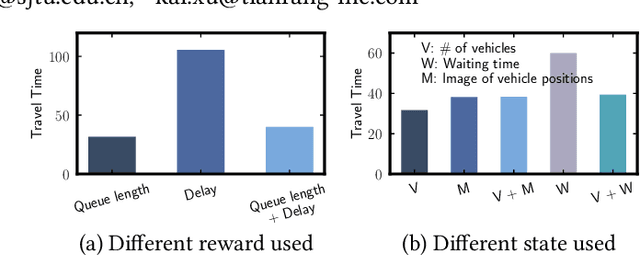

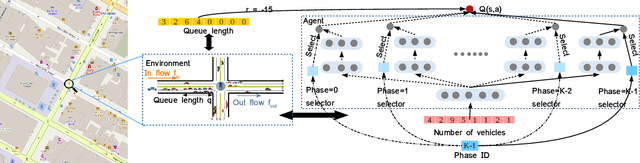
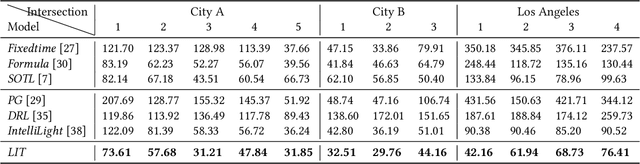
With the increasing availability of traffic data and advance of deep reinforcement learning techniques, there is an emerging trend of employing reinforcement learning (RL) for traffic signal control. A key question for applying RL to traffic signal control is how to define the reward and state. The ultimate objective in traffic signal control is to minimize the travel time, which is difficult to reach directly. Hence, existing studies often define reward as an ad-hoc weighted linear combination of several traffic measures. However, there is no guarantee that the travel time will be optimized with the reward. In addition, recent RL approaches use more complicated state (e.g., image) in order to describe the full traffic situation. However, none of the existing studies has discussed whether such a complex state representation is necessary. This extra complexity may lead to significantly slower learning process but may not necessarily bring significant performance gain. In this paper, we propose to re-examine the RL approaches through the lens of classic transportation theory. We ask the following questions: (1) How should we design the reward so that one can guarantee to minimize the travel time? (2) How to design a state representation which is concise yet sufficient to obtain the optimal solution? Our proposed method LIT is theoretically supported by the classic traffic signal control methods in transportation field. LIT has a very simple state and reward design, thus can serve as a building block for future RL approaches to traffic signal control. Extensive experiments on both synthetic and real datasets show that our method significantly outperforms the state-of-the-art traffic signal control methods.
CoLight: Learning Network-level Cooperation for Traffic Signal Control
May 11, 2019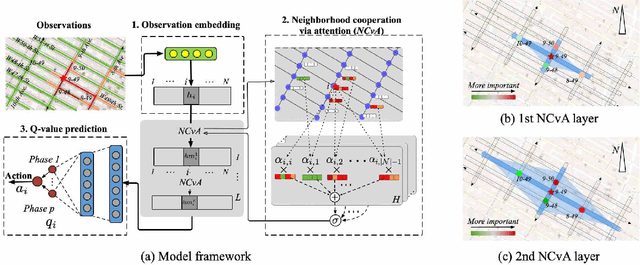
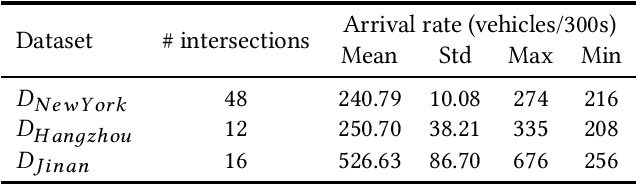
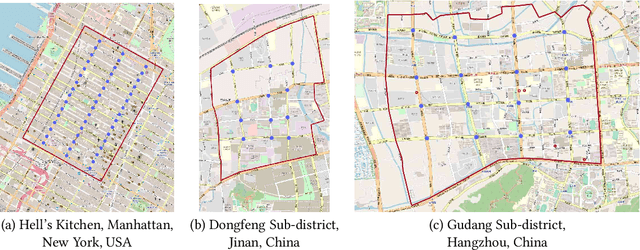
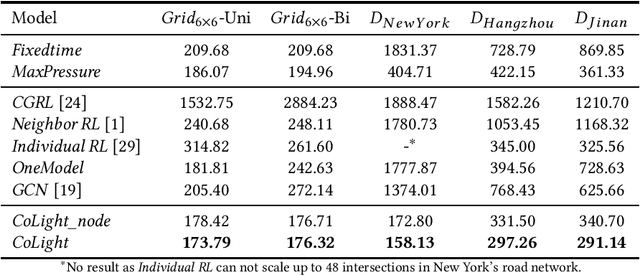
Cooperation is critical in multi-agent reinforcement learning (MARL). In the context of traffic signal control, good cooperation among the traffic signal agents enables the vehicles to move through intersections more smoothly. Conventional transportation approaches implement cooperation by pre-calculating the offsets between two intersections. Such pre-calculated offsets are not suitable for dynamic traffic environments. To incorporate cooperation in reinforcement learning (RL), two typical approaches are proposed to take the influence of other agents into consideration: (1) learning the communications (i.e., the representation of influences between agents) and (2) learning joint actions for agents. While joint modeling of actions has shown a preferred trend in recent studies, an in-depth study of improving the learning of communications between agents has not been systematically studied in the context of traffic signal control. To learn the communications between agents, in this paper, we propose to use graph attentional network to facilitate cooperation. Specifically, for a target intersection in a network, our proposed model, CoLight, cannot only incorporate the influences of neighboring intersections but learn to differentiate their impacts to the target intersection. To the best of our knowledge, we are the first to use graph attentional network in the setting of reinforcement learning for traffic signal control. In experiments, we demonstrate that by learning the communication, the proposed model can achieve surprisingly good performance, whereas the existing approaches based on joint action modeling fail to learn well.