 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADU-Depth: Attention-based Distillation with Uncertainty Modeling for Depth Estimation
Sep 26, 2023Monocular depth estimation is challenging due to its inherent ambiguity and ill-posed nature, yet it is quite important to many applications. While recent works achieve limited accuracy by designing increasingly complicated networks to extract features with limited spatial geometric cues from a single RGB image, we intend to introduce spatial cues by training a teacher network that leverages left-right image pairs as inputs and transferring the learned 3D geometry-aware knowledge to the monocular student network. Specifically, we present a novel knowledge distillation framework, named ADU-Depth, with the goal of leveraging the well-trained teacher network to guide the learning of the student network, thus boosting the precise depth estimation with the help of extra spatial scene information. To enable domain adaptation and ensure effective and smooth knowledge transfer from teacher to student, we apply both attention-adapted feature distillation and focal-depth-adapted response distillation in the training stage. In addition, we explicitly model the uncertainty of depth estimation to guide distillation in both feature space and result space to better produce 3D-aware knowledge from monocular observations and thus enhance the learning for hard-to-predict image regions. Our extensive experiments on the real depth estimation datasets KITTI and DrivingStereo demonstrate the effectiveness of the proposed method, which ranked 1st on the challenging KITTI online benchmark.
OCR-RTPS: An OCR-based real-time positioning system for the valet parking
Dec 08, 2022Obtaining the position of ego-vehicle is a crucial prerequisite for automatic control and path planning in the field of autonomous driving. Most existing positioning systems rely on GPS, RTK, or wireless signals, which are arduous to provide effective localization under weak signal conditions. This paper proposes a real-time positioning system based on the detection of the parking numbers as they are unique positioning marks in the parking lot scene. It does not only can help with the positioning with open area, but also run independently under isolation environment. The result tested on both public datasets and self-collected dataset show that the system outperforms others in both performances and applies in practice. In addition, the code and dataset will release later.
* 25 pages, 9 figures
Surround-view Fisheye BEV-Perception for Valet Parking: Dataset, Baseline and Distortion-insensitive Multi-task Framework
Dec 08, 2022



Surround-view fisheye perception under valet parking scenes is fundamental and crucial in autonomous driving. Environmental conditions in parking lots perform differently from the common public datasets, such as imperfect light and opacity, which substantially impacts on perception performance. Most existing networks based on public datasets may generalize suboptimal results on these valet parking scenes, also affected by the fisheye distortion. In this article, we introduce a new large-scale fisheye dataset called Fisheye Parking Dataset(FPD) to promote the research in dealing with diverse real-world surround-view parking cases. Notably, our compiled FPD exhibits excellent characteristics for different surround-view perception tasks. In addition, we also propose our real-time distortion-insensitive multi-task framework Fisheye Perception Network (FPNet), which improves the surround-view fisheye BEV perception by enhancing the fisheye distortion operation and multi-task lightweight designs. Extensive experiments validate the effectiveness of our approach and the dataset's exceptional generalizability.
* 12 pages, 11 figures
Complete Solution for Vehicle Re-ID in Surround-view Camera System
Dec 08, 2022Vehicle re-identification (Re-ID) is a critical component of the autonomous driving perception system, and research in this area has accelerated in recent years. However, there is yet no perfect solution to the vehicle re-identification issue associated with the car's surround-view camera system. Our analysis identifies two significant issues in the aforementioned scenario: i) It is difficult to identify the same vehicle in many picture frames due to the unique construction of the fisheye camera. ii) The appearance of the same vehicle when seen via the surround vision system's several cameras is rather different. To overcome these issues, we suggest an integrative vehicle Re-ID solution method. On the one hand, we provide a technique for determining the consistency of the tracking box drift with respect to the target. On the other hand, we combine a Re-ID network based on the attention mechanism with spatial limitations to increase performance in situations involving multiple cameras. Finally, our approach combines state-of-the-art accuracy with real-time performance. We will soon make the source code and annotated fisheye dataset available.
* 11 pages, 10 figures. arXiv admin note: substantial text overlap with arXiv:2006.16503
Attention-based Depth Distillation with 3D-Aware Positional Encoding for Monocular 3D Object Detection
Nov 30, 2022Monocular 3D object detection is a low-cost but challenging task, as it requires generating accurate 3D localization solely from a single image input. Recent developed depth-assisted methods show promising results by using explicit depth maps as intermediate features, which are either precomputed by monocular depth estimation networks or jointly evaluated with 3D object detection. However, inevitable errors from estimated depth priors may lead to misaligned semantic information and 3D localization, hence resulting in feature smearing and suboptimal predictions. To mitigate this issue, we propose ADD, an Attention-based Depth knowledge Distillation framework with 3D-aware positional encoding. Unlike previous knowledge distillation frameworks that adopt stereo- or LiDAR-based teachers, we build up our teacher with identical architecture as the student but with extra ground-truth depth as input. Credit to our teacher design, our framework is seamless, domain-gap free, easily implementable, and is compatible with object-wise ground-truth depth. Specifically, we leverage intermediate features and responses for knowledge distillation. Considering long-range 3D dependencies, we propose \emph{3D-aware self-attention} and \emph{target-aware cross-attention} modules for student adaptation. Extensive experiments are performed to verify the effectiveness of our framework on the challenging KITTI 3D object detection benchmark. We implement our framework on three representative monocular detectors, and we achieve state-of-the-art performance with no additional inference computational cost relative to baseline models. Our code is available at https://github.com/rockywind/ADD.
PSDet: Efficient and Universal Parking Slot Detection
May 12, 2020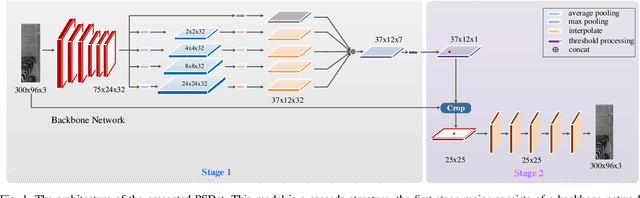
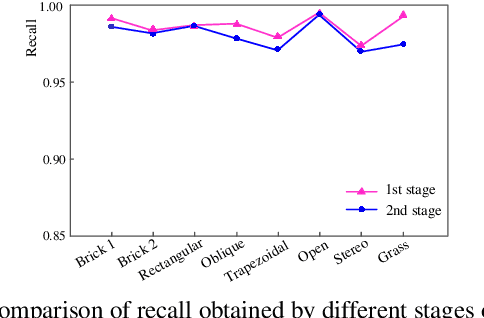
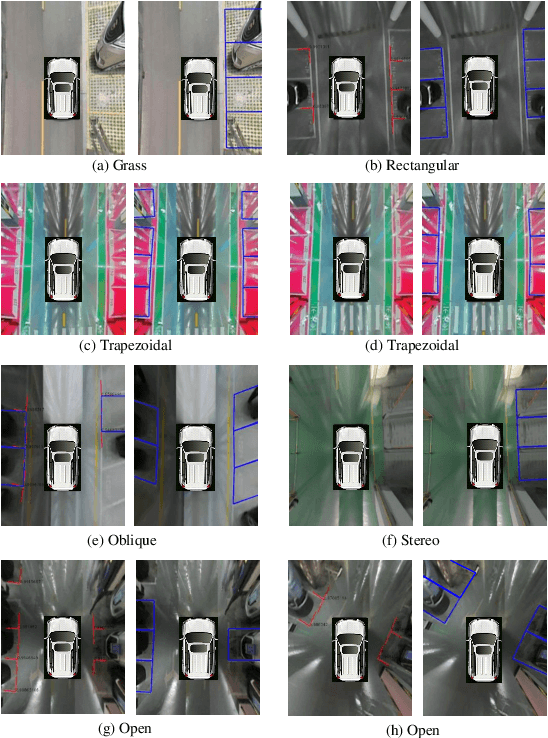

While real-time parking slot detection plays a critical role in valet parking systems, existing methods have limited success in real-world applications. We argue two reasons accounting for the unsatisfactory performance: \romannumeral1, The available datasets have limited diversity, which causes the low generalization ability. \romannumeral2, Expert knowledge for parking slot detection is under-estimated. Thus, we annotate a large-scale benchmark for training the network and release it for the benefit of community. Driven by the observation of various parking lots in our benchmark, we propose the circular descriptor to regress the coordinates of parking slot vertexes and accordingly localize slots accurately. To further boost the performance, we develop a two-stage deep architecture to localize vertexes in the coarse-to-fine manner. In our benchmark and other datasets, it achieves the state-of-the-art accuracy while being real-time in practice. Benchmark is available at: https://github.com/wuzzh/Parking-slot-dataset