 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADU-Depth: Attention-based Distillation with Uncertainty Modeling for Depth Estimation
Sep 26, 2023Monocular depth estimation is challenging due to its inherent ambiguity and ill-posed nature, yet it is quite important to many applications. While recent works achieve limited accuracy by designing increasingly complicated networks to extract features with limited spatial geometric cues from a single RGB image, we intend to introduce spatial cues by training a teacher network that leverages left-right image pairs as inputs and transferring the learned 3D geometry-aware knowledge to the monocular student network. Specifically, we present a novel knowledge distillation framework, named ADU-Depth, with the goal of leveraging the well-trained teacher network to guide the learning of the student network, thus boosting the precise depth estimation with the help of extra spatial scene information. To enable domain adaptation and ensure effective and smooth knowledge transfer from teacher to student, we apply both attention-adapted feature distillation and focal-depth-adapted response distillation in the training stage. In addition, we explicitly model the uncertainty of depth estimation to guide distillation in both feature space and result space to better produce 3D-aware knowledge from monocular observations and thus enhance the learning for hard-to-predict image regions. Our extensive experiments on the real depth estimation datasets KITTI and DrivingStereo demonstrate the effectiveness of the proposed method, which ranked 1st on the challenging KITTI online benchmark.
Learning Monocular Depth in Dynamic Environment via Context-aware Temporal Attention
May 12, 2023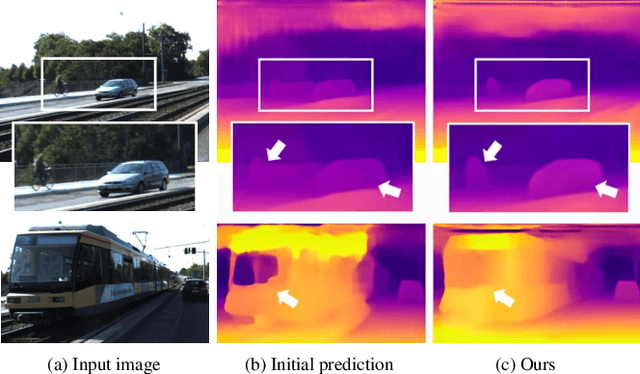

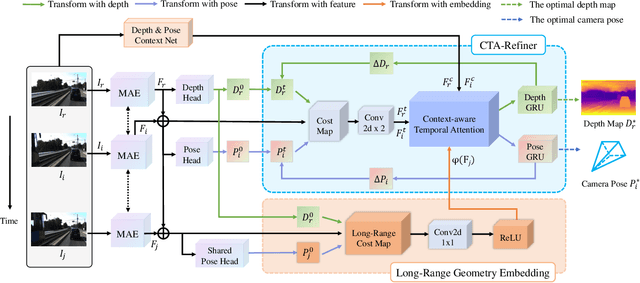
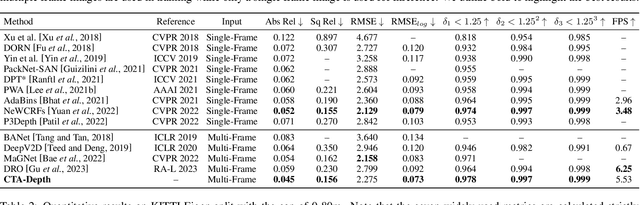
The monocular depth estimation task has recently revealed encouraging prospects, especially for the autonomous driving task. To tackle the ill-posed problem of 3D geometric reasoning from 2D monocular images, multi-frame monocular methods are developed to leverage the perspective correlation information from sequential temporal frames. However, moving objects such as cars and trains usually violate the static scene assumption, leading to feature inconsistency deviation and misaligned cost values, which would mislead the optimization algorithm. In this work, we present CTA-Depth, a Context-aware Temporal Attention guided network for multi-frame monocular Depth estimation. Specifically, we first apply a multi-level attention enhancement module to integrate multi-level image features to obtain an initial depth and pose estimation. Then the proposed CTA-Refiner is adopted to alternatively optimize the depth and pose. During the refinement process, context-aware temporal attention (CTA) is developed to capture the global temporal-context correlations to maintain the feature consistency and estimation integrity of moving objects. In particular, we propose a long-range geometry embedding (LGE) module to produce a long-range temporal geometry prior. Our approach achieves significant improvements over state-of-the-art approaches on three benchmark datasets.