 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperFusion: Multilevel LiDAR-Camera Fusion for Long-Range HD Map Generation and Prediction
Nov 28, 2022

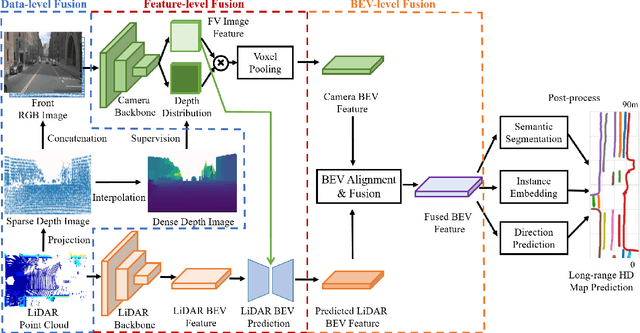

High-definition (HD) semantic map generation of the environment is an essential component of autonomous driving. Existing methods have achieved good performance in this task by fusing different sensor modalities, such as LiDAR and camera. However, current works are based on raw data or network feature-level fusion and only consider short-range HD map generation, limiting their deployment to realistic autonomous driving applications. In this paper, we focus on the task of building the HD maps in both short ranges, i.e., within 30 m, and also predicting long-range HD maps up to 90 m, which is required by downstream path planning and control tasks to improve the smoothness and safety of autonomous driving. To this end, we propose a novel network named SuperFusion, exploiting the fusion of LiDAR and camera data at multiple levels. We benchmark our SuperFusion on the nuScenes dataset and a self-recorded dataset and show that it outperforms the state-of-the-art baseline methods with large margins. Furthermore, we propose a new metric to evaluate the long-range HD map prediction and apply the generated HD map to a downstream path planning task. The results show that by using the long-range HD maps predicted by our method, we can make better path planning for autonomous vehicles. The code will be available at https://github.com/haomo-ai/SuperFusion.
Efficient Spatial-Temporal Information Fusion for LiDAR-Based 3D Moving Object Segmentation
Jul 05, 2022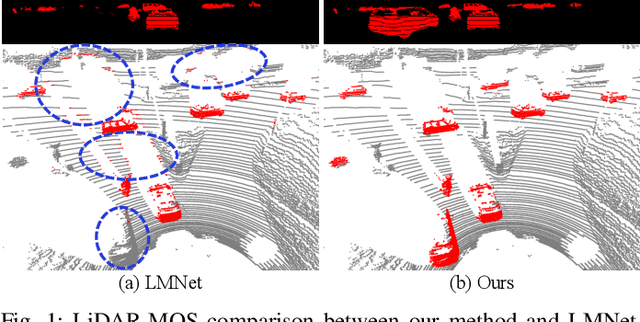

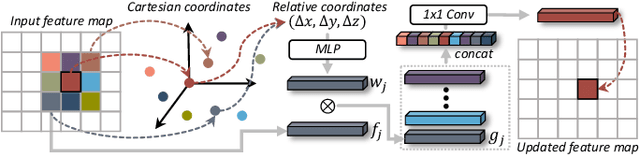

Accurate moving object segmentation is an essential task for autonomous driving. It can provide effective information for many downstream tasks, such as collision avoidance, path planning, and static map construction. How to effectively exploit the spatial-temporal information is a critical question for 3D LiDAR moving object segmentation (LiDAR-MOS). In this work, we propose a novel deep neural network exploiting both spatial-temporal information and different representation modalities of LiDAR scans to improve LiDAR-MOS performance. Specifically, we first use a range image-based dual-branch structure to separately deal with spatial and temporal information that can be obtained from sequential LiDAR scans, and later combine them using motion-guided attention modules. We also use a point refinement module via 3D sparse convolution to fuse the information from both LiDAR range image and point cloud representations and reduce the artifacts on the borders of the objects. We verify the effectiveness of our proposed approach on the LiDAR-MOS benchmark of SemanticKITTI. Our method outperforms the state-of-the-art methods significantly in terms of LiDAR-MOS IoU. Benefiting from the devised coarse-to-fine architecture, our method operates online at sensor frame rate. The implementation of our method is available as open source at: https://github.com/haomo-ai/MotionSeg3D.