 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation and Resolution Enhancement using GANs and Diffusion Models for Tree Segmentation
May 21, 2025Urban forests play a key role in enhancing environmental quality and supporting biodiversity in cities. Mapping and monitoring these green spaces are crucial for urban planning and conservation, yet accurately detecting trees is challenging due to complex landscapes and the variability in image resolution caused by different satellite sensors or UAV flight altitudes. While deep learning architectures have shown promise in addressing these challenges, their effectiveness remains strongly dependent on the availability of large and manually labeled datasets, which are often expensive and difficult to obtain in sufficient quantity. In this work, we propose a novel pipeline that integrates domain adaptation with GANs and Diffusion models to enhance the quality of low-resolution aerial images. Our proposed pipeline enhances low-resolution imagery while preserving semantic content, enabling effective tree segmentation without requiring large volumes of manually annotated data. Leveraging models such as pix2pix, Real-ESRGAN, Latent Diffusion, and Stable Diffusion, we generate realistic and structurally consistent synthetic samples that expand the training dataset and unify scale across domains. This approach not only improves the robustness of segmentation models across different acquisition conditions but also provides a scalable and replicable solution for remote sensing scenarios with scarce annotation resources. Experimental results demonstrated an improvement of over 50% in IoU for low-resolution images, highlighting the effectiveness of our method compared to traditional pipelines.
The Segment Anything Model for Remote Sensing Applications: From Zero to One Shot
Jun 29, 2023Segmentation is an essential step for remote sensing image processing. This study aims to advance the application of the Segment Anything Model (SAM), an innovative image segmentation model by Meta AI, in the field of remote sensing image analysis. SAM is known for its exceptional generalization capabilities and zero-shot learning, making it a promising approach to processing aerial and orbital images from diverse geographical contexts. Our exploration involved testing SAM across multi-scale datasets using various input prompts, such as bounding boxes, individual points, and text descriptors. To enhance the model's performance, we implemented a novel automated technique that combines a text-prompt-derived general example with one-shot training. This adjustment resulted in an improvement in accuracy, underscoring SAM's potential for deployment in remote sensing imagery and reducing the need for manual annotation. Despite the limitations encountered with lower spatial resolution images, SAM exhibits promising adaptability to remote sensing data analysis. We recommend future research to enhance the model's proficiency through integration with supplementary fine-tuning techniques and other networks. Furthermore, we provide the open-source code of our modifications on online repositories, encouraging further and broader adaptations of SAM to the remote sensing domain.
The Potential of Visual ChatGPT For Remote Sensing
Apr 25, 2023



Recent advancements in Natural Language Processing (NLP), particularly in Large Language Models (LLMs), associated with deep learning-based computer vision techniques, have shown substantial potential for automating a variety of tasks. One notable model is Visual ChatGPT, which combines ChatGPT's LLM capabilities with visual computation to enable effective image analysis. The model's ability to process images based on textual inputs can revolutionize diverse fields. However, its application in the remote sensing domain remains unexplored. This is the first paper to examine the potential of Visual ChatGPT, a cutting-edge LLM founded on the GPT architecture, to tackle the aspects of image processing related to the remote sensing domain. Among its current capabilities, Visual ChatGPT can generate textual descriptions of images, perform canny edge and straight line detection, and conduct image segmentation. These offer valuable insights into image content and facilitate the interpretation and extraction of information. By exploring the applicability of these techniques within publicly available datasets of satellite images, we demonstrate the current model's limitations in dealing with remote sensing images, highlighting its challenges and future prospects. Although still in early development, we believe that the combination of LLMs and visual models holds a significant potential to transform remote sensing image processing, creating accessible and practical application opportunities in the field.
Semantic Segmentation with Labeling Uncertainty and Class Imbalance
Feb 08, 2021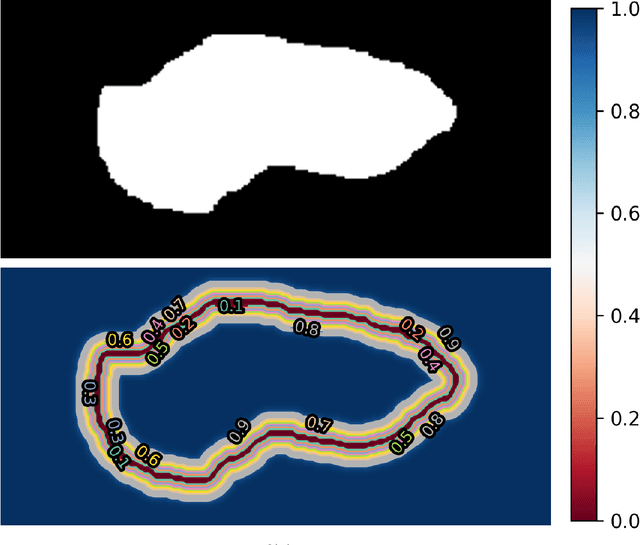
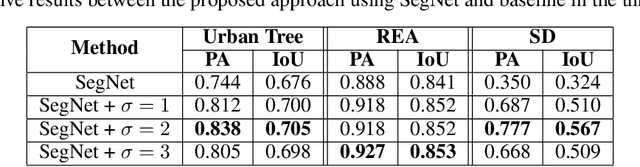

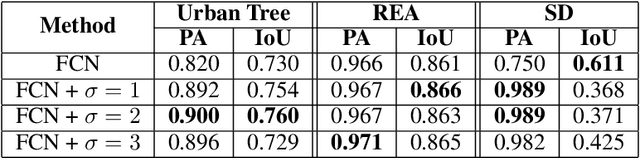
Recently, methods based on Convolutional Neural Networks (CNN) achieved impressive success in semantic segmentation tasks. However, challenges such as the class imbalance and the uncertainty in the pixel-labeling process are not completely addressed. As such, we present a new approach that calculates a weight for each pixel considering its class and uncertainty during the labeling process. The pixel-wise weights are used during training to increase or decrease the importance of the pixels. Experimental results show that the proposed approach leads to significant improvements in three challenging segmentation tasks in comparison to baseline methods. It was also proved to be more invariant to noise. The approach presented here may be used within a wide range of semantic segmentation methods to improve their robustness.
Counting and Locating High-Density Objects Using Convolutional Neural Network
Feb 08, 2021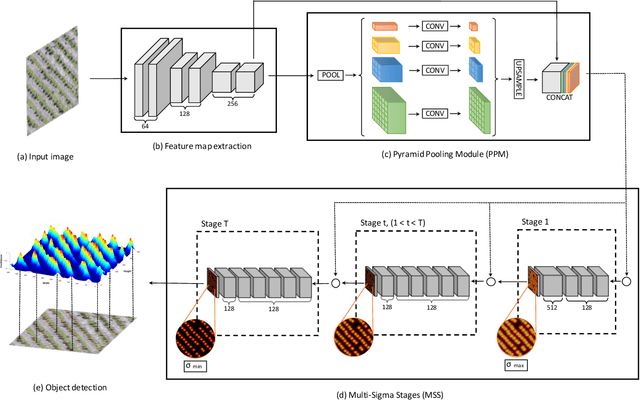
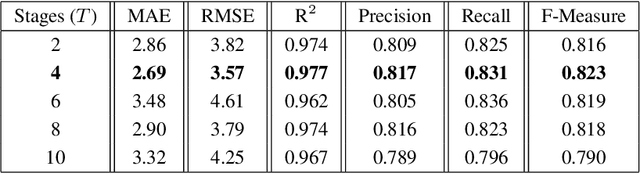

This paper presents a Convolutional Neural Network (CNN) approach for counting and locating objects in high-density imagery. To the best of our knowledge, this is the first object counting and locating method based on a feature map enhancement and a Multi-Stage Refinement of the confidence map. The proposed method was evaluated in two counting datasets: tree and car. For the tree dataset, our method returned a mean absolute error (MAE) of 2.05, a root-mean-squared error (RMSE) of 2.87 and a coefficient of determination (R$^2$) of 0.986. For the car dataset (CARPK and PUCPR+), our method was superior to state-of-the-art methods. In the these datasets, our approach achieved an MAE of 4.45 and 3.16, an RMSE of 6.18 and 4.39, and an R$^2$ of 0.975 and 0.999, respectively. The proposed method is suitable for dealing with high object-density, returning a state-of-the-art performance for counting and locating objects.
A Deep Learning Approach Based on Graphs to Detect Plantation Lines
Feb 05, 2021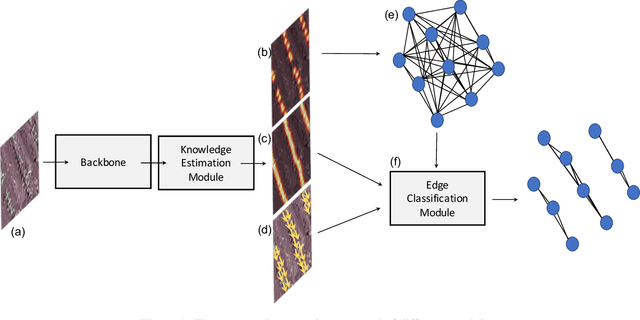
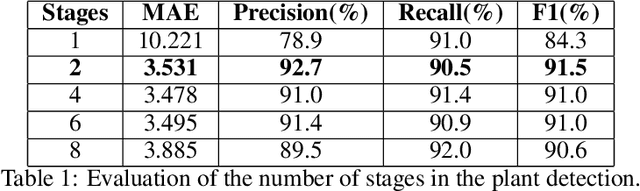
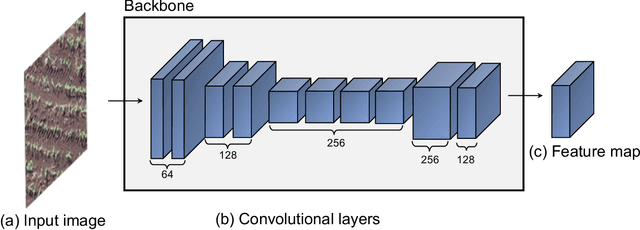
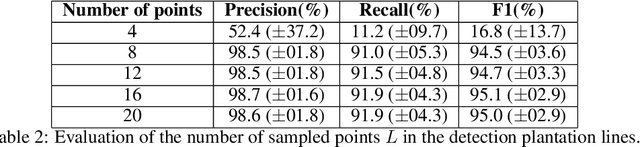
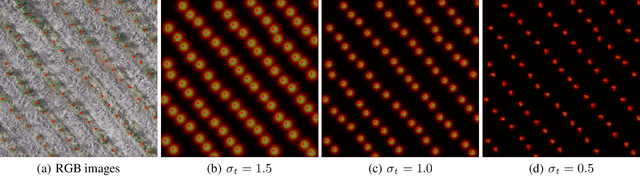
Deep learning-based networks are among the most prominent methods to learn linear patterns and extract this type of information from diverse imagery conditions. Here, we propose a deep learning approach based on graphs to detect plantation lines in UAV-based RGB imagery presenting a challenging scenario containing spaced plants. The first module of our method extracts a feature map throughout the backbone, which consists of the initial layers of the VGG16. This feature map is used as an input to the Knowledge Estimation Module (KEM), organized in three concatenated branches for detecting 1) the plant positions, 2) the plantation lines, and 3) for the displacement vectors between the plants. A graph modeling is applied considering each plant position on the image as vertices, and edges are formed between two vertices (i.e. plants). Finally, the edge is classified as pertaining to a certain plantation line based on three probabilities (higher than 0.5): i) in visual features obtained from the backbone; ii) a chance that the edge pixels belong to a line, from the KEM step; and iii) an alignment of the displacement vectors with the edge, also from KEM. Experiments were conducted in corn plantations with different growth stages and patterns with aerial RGB imagery. A total of 564 patches with 256 x 256 pixels were used and randomly divided into training, validation, and testing sets in a proportion of 60\%, 20\%, and 20\%, respectively. The proposed method was compared against state-of-the-art deep learning methods, and achieved superior performance with a significant margin, returning precision, recall, and F1-score of 98.7\%, 91.9\%, and 95.1\%, respectively. This approach is useful in extracting lines with spaced plantation patterns and could be implemented in scenarios where plantation gaps occur, generating lines with few-to-none interruptions.
A Review on Deep Learning in UAV Remote Sensing
Jan 29, 2021

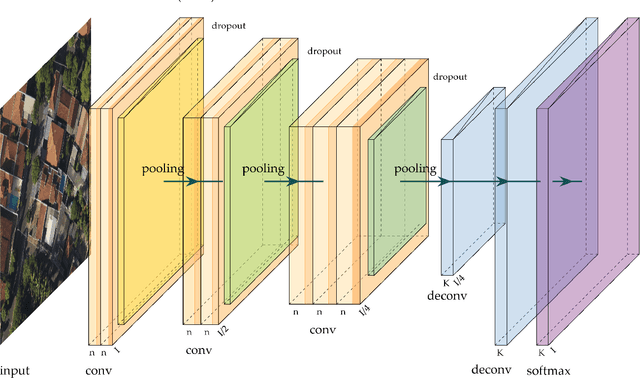
Deep Neural Networks (DNNs) learn representation from data with an impressive capability, and brought important breakthroughs for processing images, time-series, natural language, audio, video, and many others. In the remote sensing field, surveys and literature revisions specifically involving DNNs algorithms' applications have been conducted in an attempt to summarize the amount of information produced in its subfields. Recently, Unmanned Aerial Vehicles (UAV) based applications have dominated aerial sensing research. However, a literature revision that combines both "deep learning" and "UAV remote sensing" thematics has not yet been conducted. The motivation for our work was to present a comprehensive review of the fundamentals of Deep Learning (DL) applied in UAV-based imagery. We focused mainly on describing classification and regression techniques used in recent applications with UAV-acquired data. For that, a total of 232 papers published in international scientific journal databases was examined. We gathered the published material and evaluated their characteristics regarding application, sensor, and technique used. We relate how DL presents promising results and has the potential for processing tasks associated with UAV-based image data. Lastly, we project future perspectives, commentating on prominent DL paths to be explored in the UAV remote sensing field. Our revision consists of a friendly-approach to introduce, commentate, and summarize the state-of-the-art in UAV-based image applications with DNNs algorithms in diverse subfields of remote sensing, grouping it in the environmental, urban, and agricultural contexts.
A CNN Approach to Simultaneously Count Plants and Detect Plantation-Rows from UAV Imagery
Jan 02, 2021
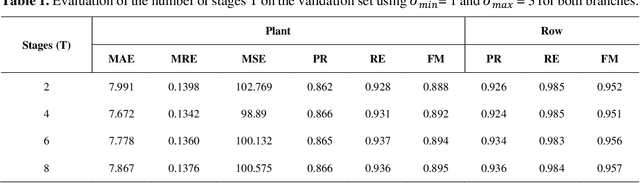
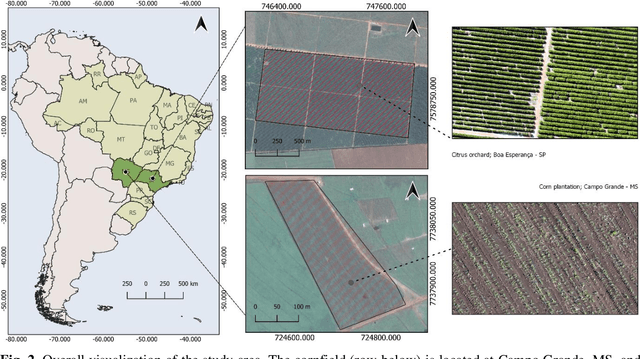
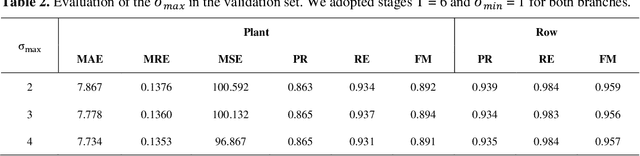
In this paper, we propose a novel deep learning method based on a Convolutional Neural Network (CNN) that simultaneously detects and geolocates plantation-rows while counting its plants considering highly-dense plantation configurations. The experimental setup was evaluated in a cornfield with different growth stages and in a Citrus orchard. Both datasets characterize different plant density scenarios, locations, types of crops, sensors, and dates. A two-branch architecture was implemented in our CNN method, where the information obtained within the plantation-row is updated into the plant detection branch and retro-feed to the row branch; which are then refined by a Multi-Stage Refinement method. In the corn plantation datasets (with both growth phases, young and mature), our approach returned a mean absolute error (MAE) of 6.224 plants per image patch, a mean relative error (MRE) of 0.1038, precision and recall values of 0.856, and 0.905, respectively, and an F-measure equal to 0.876. These results were superior to the results from other deep networks (HRNet, Faster R-CNN, and RetinaNet) evaluated with the same task and dataset. For the plantation-row detection, our approach returned precision, recall, and F-measure scores of 0.913, 0.941, and 0.925, respectively. To test the robustness of our model with a different type of agriculture, we performed the same task in the citrus orchard dataset. It returned an MAE equal to 1.409 citrus-trees per patch, MRE of 0.0615, precision of 0.922, recall of 0.911, and F-measure of 0.965. For citrus plantation-row detection, our approach resulted in precision, recall, and F-measure scores equal to 0.965, 0.970, and 0.964, respectively. The proposed method achieved state-of-the-art performance for counting and geolocating plants and plant-rows in UAV images from different types of crops.
Texture analysis using deterministic partially self-avoiding walk with thresholds
Nov 25, 2016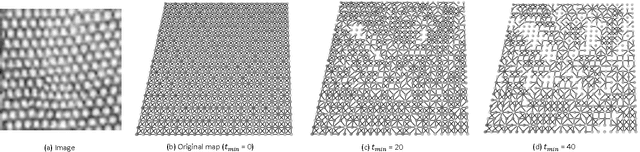
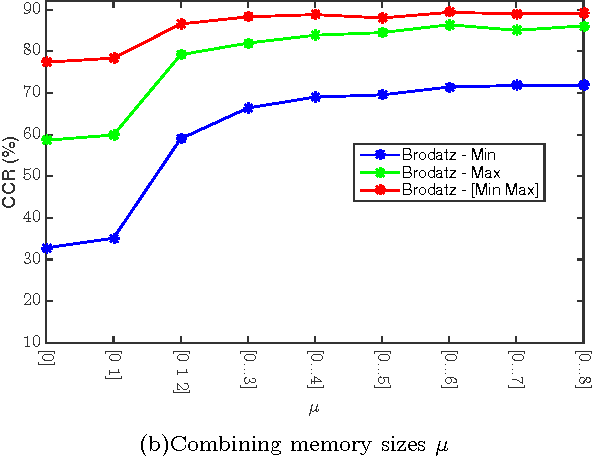
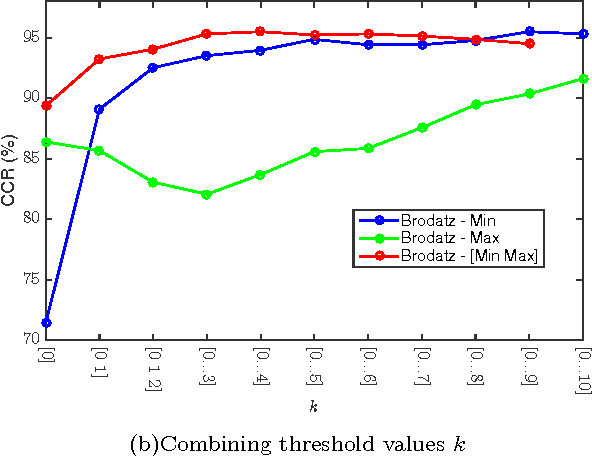
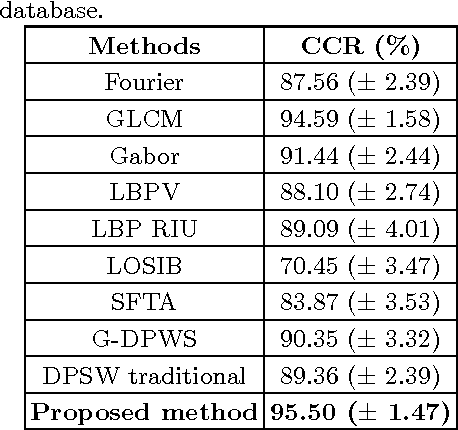
In this paper, we propose a new texture analysis method using the deterministic partially self-avoiding walk performed on maps modified with thresholds. In this method, two pixels of the map are neighbors if the Euclidean distance between them is less than $\sqrt{2}$ and the weight (difference between its intensities) is less than a given threshold. The maps obtained by using different thresholds highlight several properties of the image that are extracted by the deterministic walk. To compose the feature vector, deterministic walks are performed with different thresholds and its statistics are concatenated. Thus, this approach can be considered as a multi-scale analysis. We validate our method on the Brodatz database, which is very well known public image database and widely used by texture analysis methods. Experimental results indicate that the proposed method presents a good texture discrimination, overcoming traditional texture methods.
* 8 pages, 3 figures
Texture descriptor combining fractal dimension and artificial crawlers
Nov 21, 2013
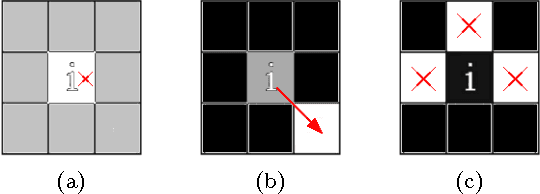


Texture is an important visual attribute used to describe images. There are many methods available for texture analysis. However, they do not capture the details richness of the image surface. In this paper, we propose a new method to describe textures using the artificial crawler model. This model assumes that each agent can interact with the environment and each other. Since this swarm system alone does not achieve a good discrimination, we developed a new method to increase the discriminatory power of artificial crawlers, together with the fractal dimension theory. Here, we estimated the fractal dimension by the Bouligand-Minkowski method due to its precision in quantifying structural properties of images. We validate our method on two texture datasets and the experimental results reveal that our method leads to highly discriminative textural features. The results indicate that our method can be used in different texture applications.