 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexicon-injected Semantic Parsing for Task-Oriented Dialog
Nov 26, 2022
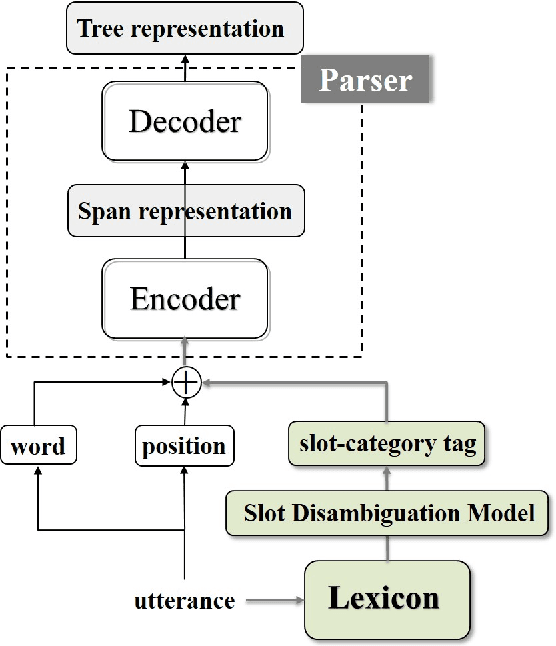


Recently, semantic parsing using hierarchical representations for dialog systems has captured substantial attention. Task-Oriented Parse (TOP), a tree representation with intents and slots as labels of nested tree nodes, has been proposed for parsing user utterances. Previous TOP parsing methods are limited on tackling unseen dynamic slot values (e.g., new songs and locations added), which is an urgent matter for real dialog systems. To mitigate this issue, we first propose a novel span-splitting representation for span-based parser that outperforms existing methods. Then we present a novel lexicon-injected semantic parser, which collects slot labels of tree representation as a lexicon, and injects lexical features to the span representation of parser. An additional slot disambiguation technique is involved to remove inappropriate span match occurrences from the lexicon. Our best parser produces a new state-of-the-art result (87.62%) on the TOP dataset, and demonstrates its adaptability to frequently updated slot lexicon entries in real task-oriented dialog, with no need of retraining.
An End-to-end Chinese Text Normalization Model based on Rule-guided Flat-Lattice Transformer
Mar 31, 2022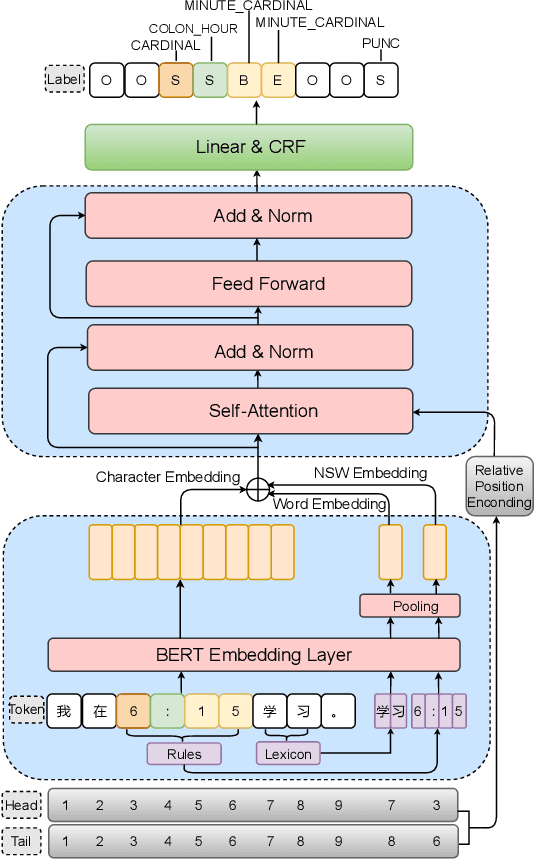
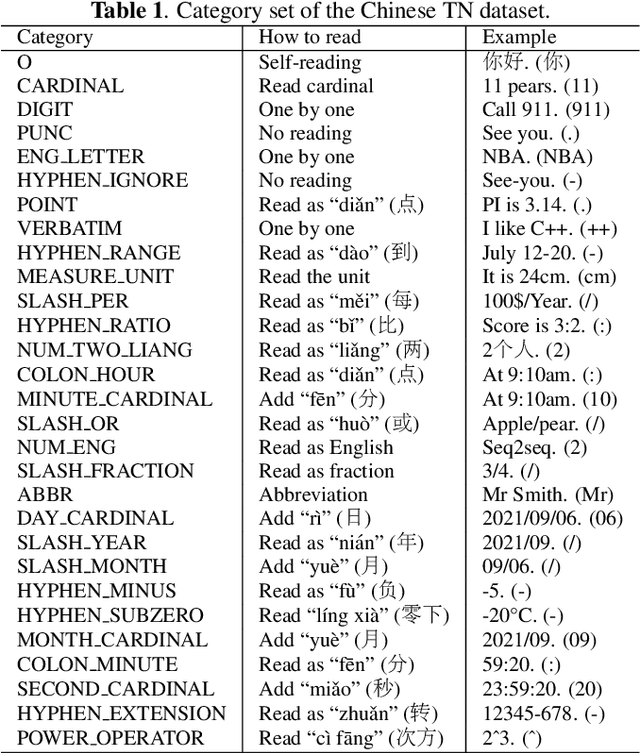
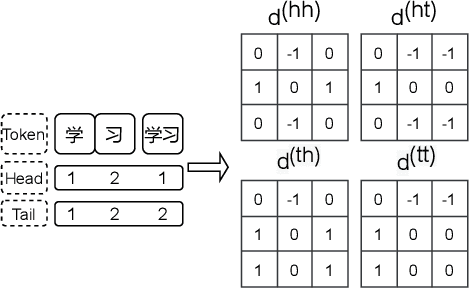
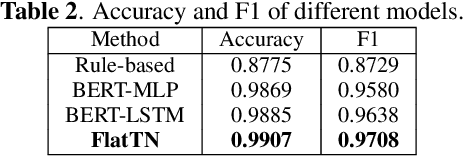
Text normalization, defined as a procedure transforming non standard words to spoken-form words, is crucial to the intelligibility of synthesized speech in text-to-speech system. Rule-based methods without considering context can not eliminate ambiguation, whereas sequence-to-sequence neural network based methods suffer from the unexpected and uninterpretable errors problem. Recently proposed hybrid system treats rule-based model and neural model as two cascaded sub-modules, where limited interaction capability makes neural network model cannot fully utilize expert knowledge contained in the rules. Inspired by Flat-LAttice Transformer (FLAT), we propose an end-to-end Chinese text normalization model, which accepts Chinese characters as direct input and integrates expert knowledge contained in rules into the neural network, both contribute to the superior performance of proposed model for the text normalization task. We also release a first publicly accessible largescale dataset for Chinese text normalization. Our proposed model has achieved excellent results on this dataset.
An Outlyingness Matrix for Multivariate Functional Data Classification
Apr 22, 2018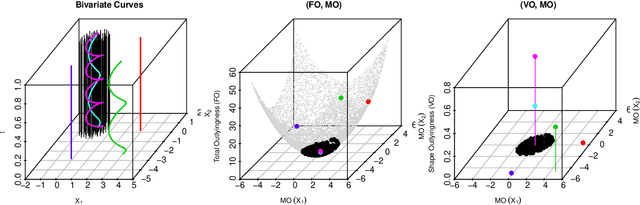
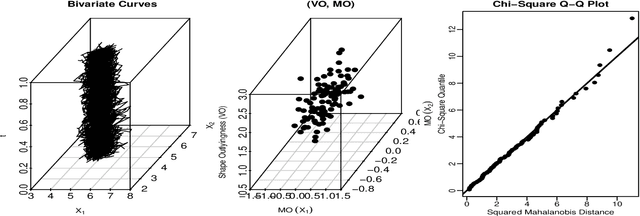
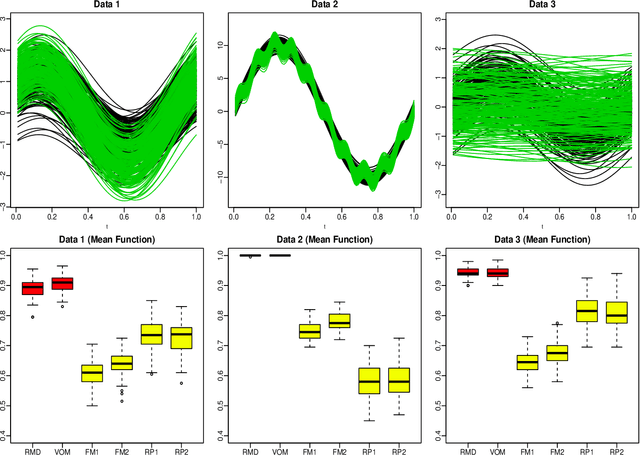
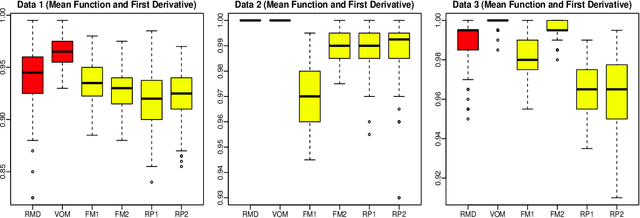
The classification of multivariate functional data is an important task in scientific research. Unlike point-wise data, functional data are usually classified by their shapes rather than by their scales. We define an outlyingness matrix by extending directional outlyingness, an effective measure of the shape variation of curves that combines the direction of outlyingness with conventional depth. We propose two classifiers based on directional outlyingness and the outlyingness matrix, respectively. Our classifiers provide better performance compared with existing depth-based classifiers when applied on both univariate and multivariate functional data from simulation studies. We also test our methods on two data problems: speech recognition and gesture classification, and obtain results that are consistent with the findings from the simulated data.