 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn End-to-end Chinese Text Normalization Model based on Rule-guided Flat-Lattice Transformer
Paper and Code
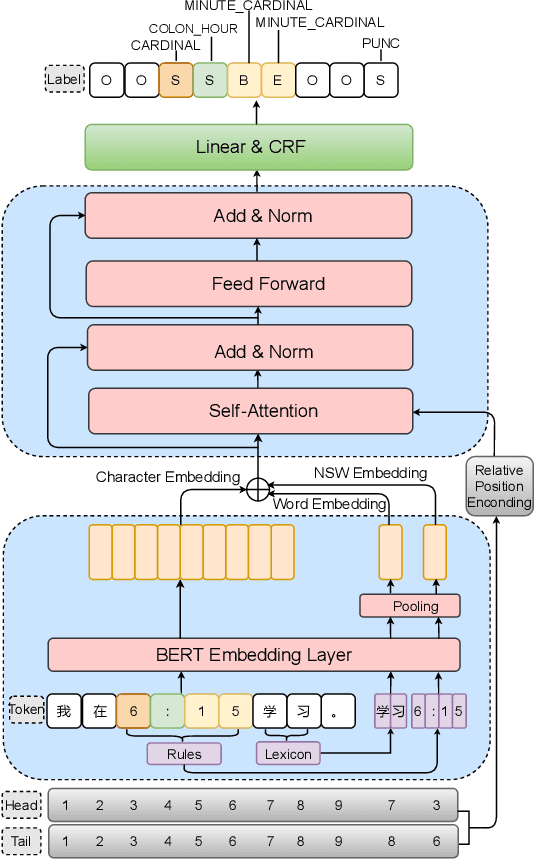
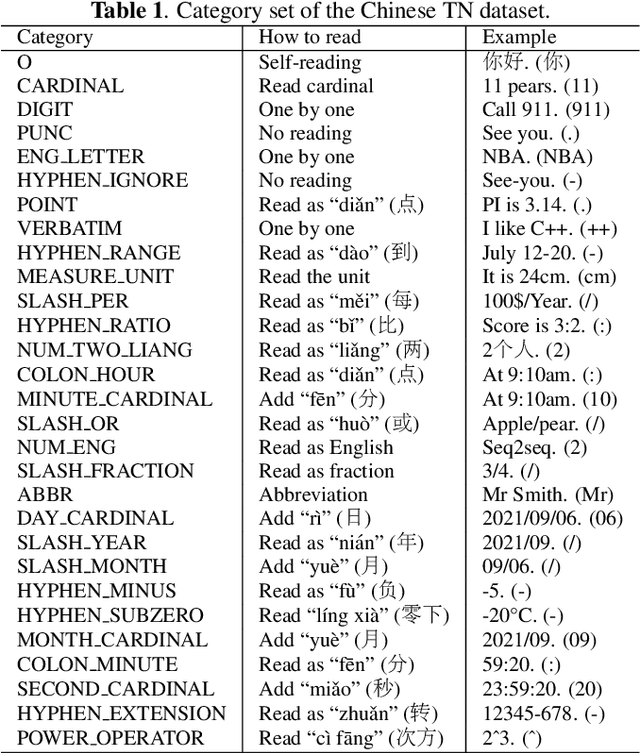
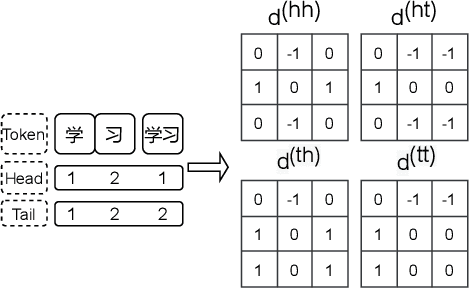
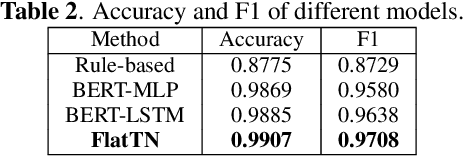
Text normalization, defined as a procedure transforming non standard words to spoken-form words, is crucial to the intelligibility of synthesized speech in text-to-speech system. Rule-based methods without considering context can not eliminate ambiguation, whereas sequence-to-sequence neural network based methods suffer from the unexpected and uninterpretable errors problem. Recently proposed hybrid system treats rule-based model and neural model as two cascaded sub-modules, where limited interaction capability makes neural network model cannot fully utilize expert knowledge contained in the rules. Inspired by Flat-LAttice Transformer (FLAT), we propose an end-to-end Chinese text normalization model, which accepts Chinese characters as direct input and integrates expert knowledge contained in rules into the neural network, both contribute to the superior performance of proposed model for the text normalization task. We also release a first publicly accessible largescale dataset for Chinese text normalization. Our proposed model has achieved excellent results on this dataset.