 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGD with Dependent Data: Optimal Estimation, Regret, and Inference
Jan 04, 2026This work investigates the performance of the final iterate produced by stochastic gradient descent (SGD) under temporally dependent data. We consider two complementary sources of dependence: $(i)$ martingale-type dependence in both the covariate and noise processes, which accommodates non-stationary and non-mixing time series data, and $(ii)$ dependence induced by sequential decision making. Our formulation runs in parallel with classical notions of (local) stationarity and strong mixing, while neither framework fully subsumes the other. Remarkably, SGD is shown to automatically accommodate both independent and dependent information under a broad class of stepsize schedules and exploration rate schemes. Non-asymptotically, we show that SGD simultaneously achieves statistically optimal estimation error and regret, extending and improving existing results. In particular, our tail bounds remain sharp even for potentially infinite horizon $T=+\infty$. Asymptotically, the SGD iterates converge to a Gaussian distribution with only an $O_{\PP}(1/\sqrt{t})$ remainder, demonstrating that the supposed estimation-regret trade-off claimed in prior work can in fact be avoided. We further propose a new ``conic'' approximation of the decision region that allows the covariates to have unbounded support. For online sparse regression, we develop a new SGD-based algorithm that uses only $d$ units of storage and requires $O(d)$ flops per iteration, achieving the long term statistical optimality. Intuitively, each incoming observation contributes to estimation accuracy, while aggregated summary statistics guide support recovery.
Retire: Robust Expectile Regression in High Dimensions
Dec 11, 2022High-dimensional data can often display heterogeneity due to heteroscedastic variance or inhomogeneous covariate effects. Penalized quantile and expectile regression methods offer useful tools to detect heteroscedasticity in high-dimensional data. The former is computationally challenging due to the non-smooth nature of the check loss, and the latter is sensitive to heavy-tailed error distributions. In this paper, we propose and study (penalized) robust expectile regression (retire), with a focus on iteratively reweighted $\ell_1$-penalization which reduces the estimation bias from $\ell_1$-penalization and leads to oracle properties. Theoretically, we establish the statistical properties of the retire estimator under two regimes: (i) low-dimensional regime in which $d \ll n$; (ii) high-dimensional regime in which $s\ll n\ll d$ with $s$ denoting the number of significant predictors. In the high-dimensional setting, we carefully characterize the solution path of the iteratively reweighted $\ell_1$-penalized retire estimation, adapted from the local linear approximation algorithm for folded-concave regularization. Under a mild minimum signal strength condition, we show that after as many as $\log(\log d)$ iterations the final iterate enjoys the oracle convergence rate. At each iteration, the weighted $\ell_1$-penalized convex program can be efficiently solved by a semismooth Newton coordinate descent algorithm. Numerical studies demonstrate the competitive performance of the proposed procedure compared with either non-robust or quantile regression based alternatives.
How do noise tails impact on deep ReLU networks?
Mar 20, 2022



This paper investigates the stability of deep ReLU neural networks for nonparametric regression under the assumption that the noise has only a finite p-th moment. We unveil how the optimal rate of convergence depends on p, the degree of smoothness and the intrinsic dimension in a class of nonparametric regression functions with hierarchical composition structure when both the adaptive Huber loss and deep ReLU neural networks are used. This optimal rate of convergence cannot be obtained by the ordinary least squares but can be achieved by the Huber loss with a properly chosen parameter that adapts to the sample size, smoothness, and moment parameters. A concentration inequality for the adaptive Huber ReLU neural network estimators with allowable optimization errors is also derived. To establish a matching lower bound within the class of neural network estimators using the Huber loss, we employ a different strategy from the traditional route: constructing a deep ReLU network estimator that has a better empirical loss than the true function and the difference between these two functions furnishes a low bound. This step is related to the Huberization bias, yet more critically to the approximability of deep ReLU networks. As a result, we also contribute some new results on the approximation theory of deep ReLU neural networks.
Communication-Efficient Distributed Quantile Regression with Optimal Statistical Guarantees
Oct 25, 2021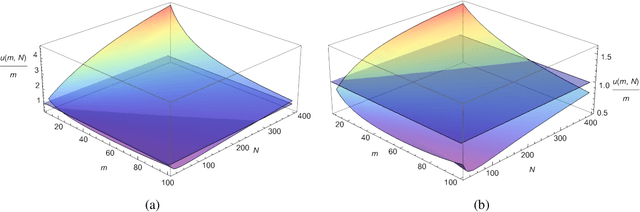


We address the problem of how to achieve optimal inference in distributed quantile regression without stringent scaling conditions. This is challenging due to the non-smooth nature of the quantile regression loss function, which invalidates the use of existing methodology. The difficulties are resolved through a double-smoothing approach that is applied to the local (at each data source) and global objective functions. Despite the reliance on a delicate combination of local and global smoothing parameters, the quantile regression model is fully parametric, thereby facilitating interpretation. In the low-dimensional regime, we discuss and compare several alternative confidence set constructions, based on inversion of Wald and score-type tests and resam-pling techniques, detailing an improvement that is effective for more extreme quantile coefficients. In high dimensions, a sparse framework is adopted, where the proposed doubly-smoothed objective function is complemented with an $\ell_1$-penalty. A thorough simulation study further elucidates our findings. Finally, we provide estimation theory and numerical studies for sparse quantile regression in the high-dimensional setting.
Nonconvex Regularized Robust Regression with Oracle Properties in Polynomial Time
Jul 09, 2019
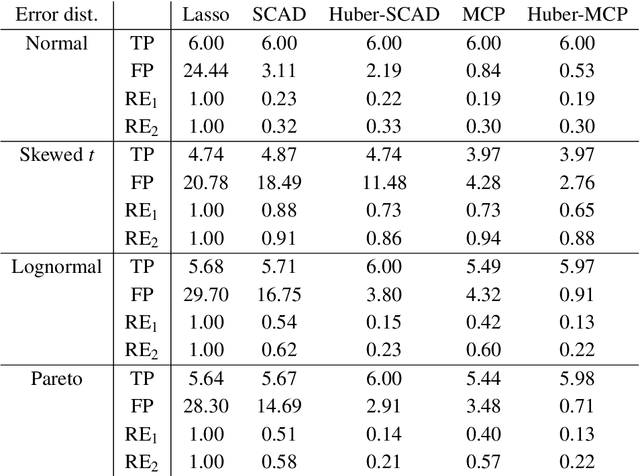
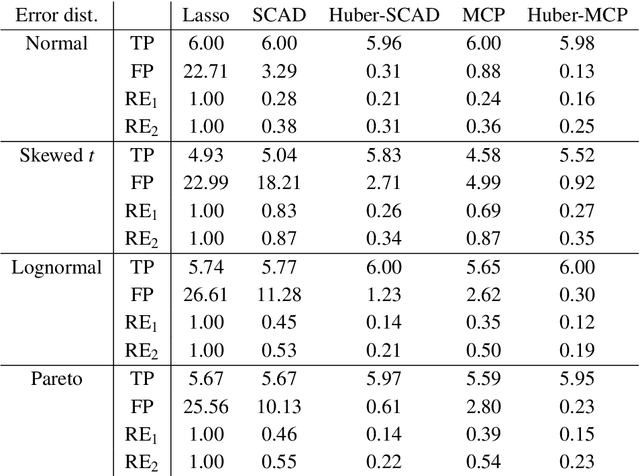
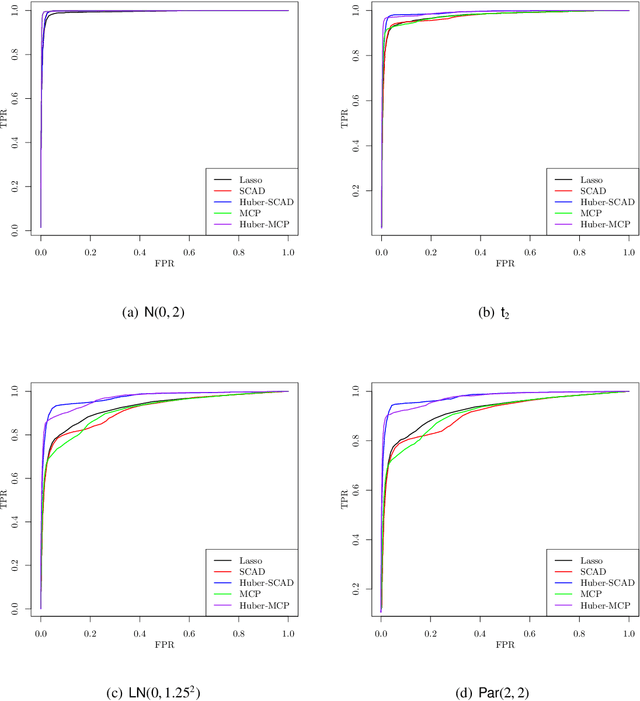
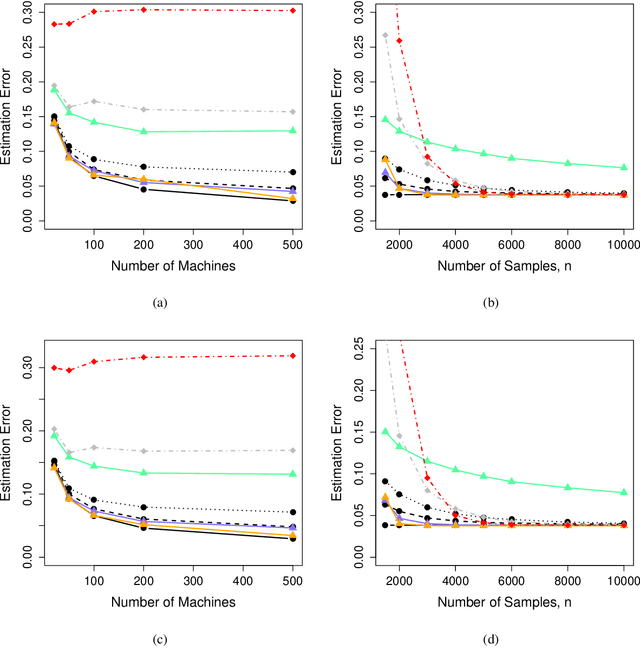
This paper investigates tradeoffs among optimization errors, statistical rates of convergence and the effect of heavy-tailed random errors for high-dimensional adaptive Huber regression with nonconvex regularization. When the additive errors in linear models have only bounded second moment, our results suggest that adaptive Huber regression with nonconvex regularization yields statistically optimal estimators that satisfy oracle properties as if the true underlying support set were known beforehand. Computationally, we need as many as O(log s + log log d) convex relaxations to reach such oracle estimators, where s and d denote the sparsity and ambient dimension, respectively. Numerical studies lend strong support to our methodology and theory.
Matrix Completion via Max-Norm Constrained Optimization
Apr 28, 2017Matrix completion has been well studied under the uniform sampling model and the trace-norm regularized methods perform well both theoretically and numerically in such a setting. However, the uniform sampling model is unrealistic for a range of applications and the standard trace-norm relaxation can behave very poorly when the underlying sampling scheme is non-uniform. In this paper we propose and analyze a max-norm constrained empirical risk minimization method for noisy matrix completion under a general sampling model. The optimal rate of convergence is established under the Frobenius norm loss in the context of approximately low-rank matrix reconstruction. It is shown that the max-norm constrained method is minimax rate-optimal and yields a unified and robust approximate recovery guarantee, with respect to the sampling distributions. The computational effectiveness of this method is also discussed, based on first-order algorithms for solving convex optimizations involving max-norm regularization.
Max-Norm Optimization for Robust Matrix Recovery
Sep 24, 2016



This paper studies the matrix completion problem under arbitrary sampling schemes. We propose a new estimator incorporating both max-norm and nuclear-norm regularization, based on which we can conduct efficient low-rank matrix recovery using a random subset of entries observed with additive noise under general non-uniform and unknown sampling distributions. This method significantly relaxes the uniform sampling assumption imposed for the widely used nuclear-norm penalized approach, and makes low-rank matrix recovery feasible in more practical settings. Theoretically, we prove that the proposed estimator achieves fast rates of convergence under different settings. Computationally, we propose an alternating direction method of multipliers algorithm to efficiently compute the estimator, which bridges a gap between theory and practice of machine learning methods with max-norm regularization. Further, we provide thorough numerical studies to evaluate the proposed method using both simulated and real datasets.
A Max-Norm Constrained Minimization Approach to 1-Bit Matrix Completion
Sep 24, 2013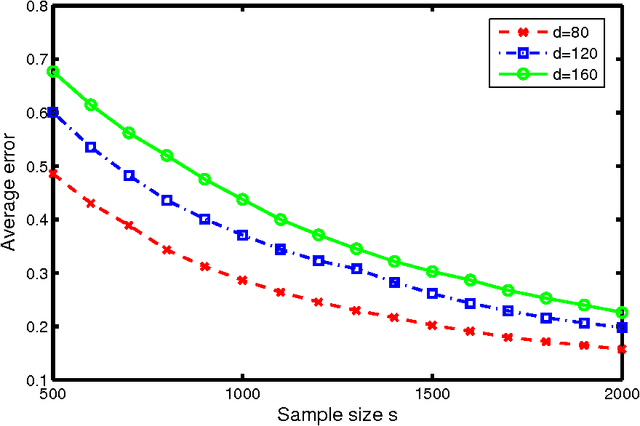
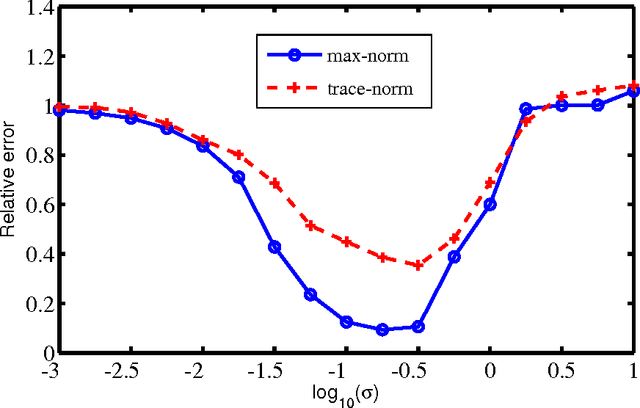

We consider in this paper the problem of noisy 1-bit matrix completion under a general non-uniform sampling distribution using the max-norm as a convex relaxation for the rank. A max-norm constrained maximum likelihood estimate is introduced and studied. The rate of convergence for the estimate is obtained. Information-theoretical methods are used to establish a minimax lower bound under the general sampling model. The minimax upper and lower bounds together yield the optimal rate of convergence for the Frobenius norm loss. Computational algorithms and numerical performance are also discussed.