 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReactIE: Enhancing Chemical Reaction Extraction with Weak Supervision
Jul 04, 2023Structured chemical reaction information plays a vital role for chemists engaged in laboratory work and advanced endeavors such as computer-aided drug design. Despite the importance of extracting structured reactions from scientific literature, data annotation for this purpose is cost-prohibitive due to the significant labor required from domain experts. Consequently, the scarcity of sufficient training data poses an obstacle to the progress of related models in this domain. In this paper, we propose ReactIE, which combines two weakly supervised approaches for pre-training. Our method utilizes frequent patterns within the text as linguistic cues to identify specific characteristics of chemical reactions. Additionally, we adopt synthetic data from patent records as distant supervision to incorporate domain knowledge into the model. Experiments demonstrate that ReactIE achieves substantial improvements and outperforms all existing baselines.
Ensemble prosody prediction for expressive speech synthesis
Apr 03, 2023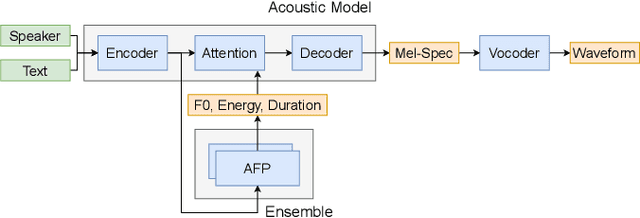

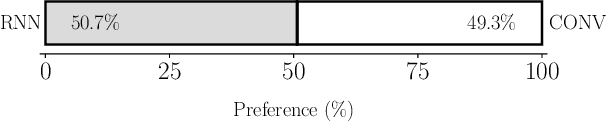
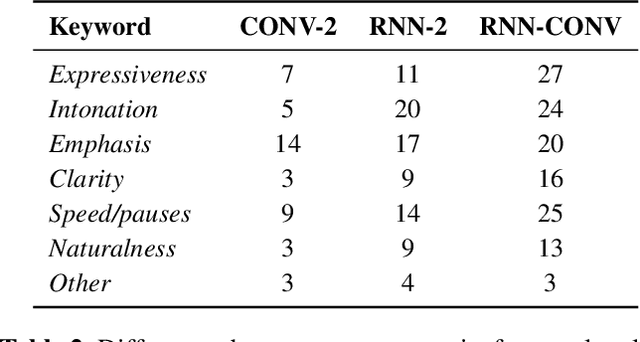
Generating expressive speech with rich and varied prosody continues to be a challenge for Text-to-Speech. Most efforts have focused on sophisticated neural architectures intended to better model the data distribution. Yet, in evaluations it is generally found that no single model is preferred for all input texts. This suggests an approach that has rarely been used before for Text-to-Speech: an ensemble of models. We apply ensemble learning to prosody prediction. We construct simple ensembles of prosody predictors by varying either model architecture or model parameter values. To automatically select amongst the models in the ensemble when performing Text-to-Speech, we propose a novel, and computationally trivial, variance-based criterion. We demonstrate that even a small ensemble of prosody predictors yields useful diversity, which, combined with the proposed selection criterion, outperforms any individual model from the ensemble.
Ctrl-P: Temporal Control of Prosodic Variation for Speech Synthesis
Jun 15, 2021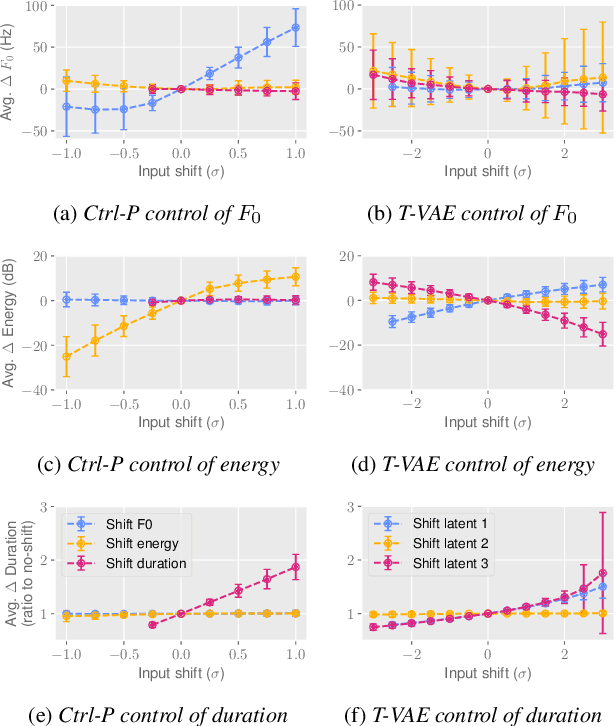
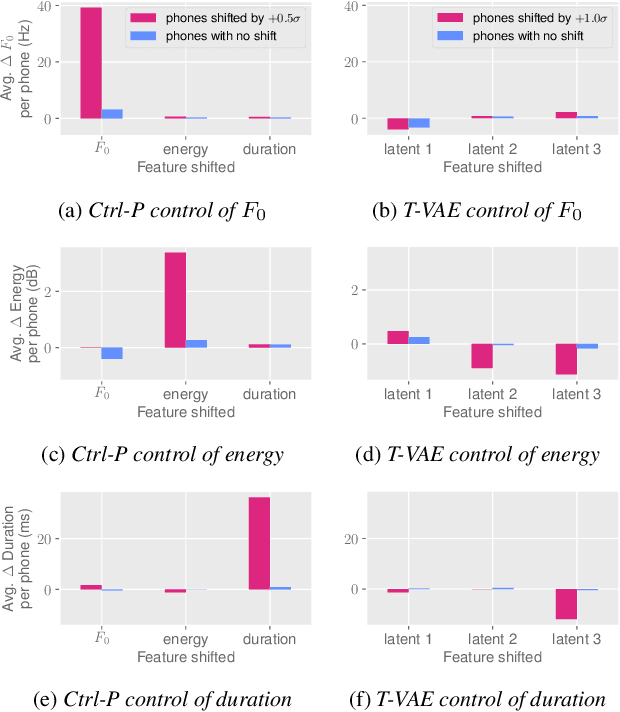
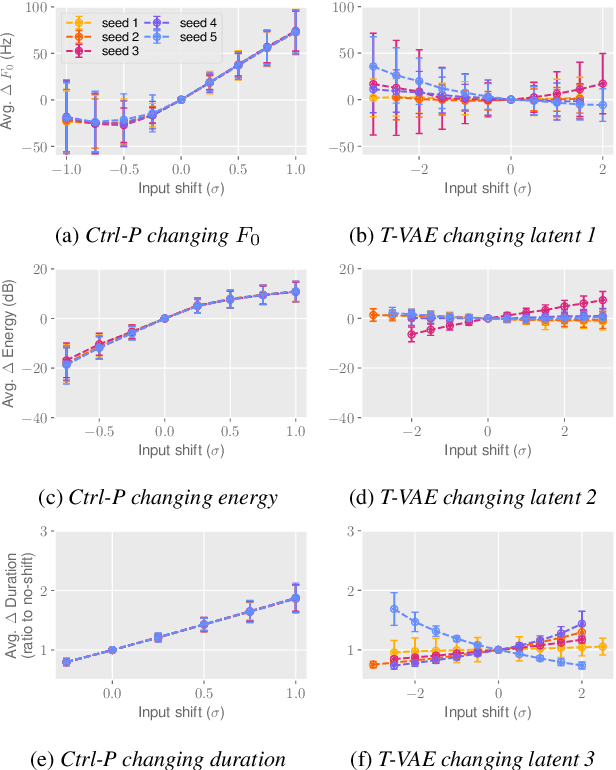
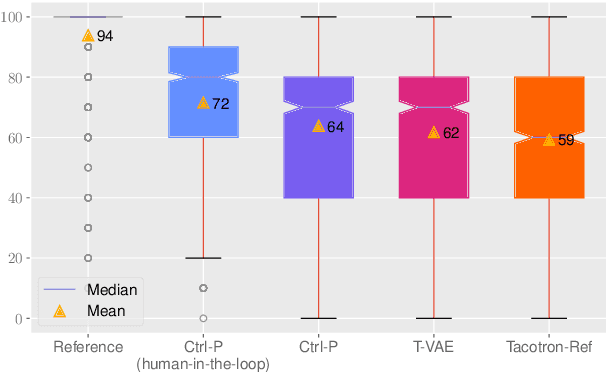
Text does not fully specify the spoken form, so text-to-speech models must be able to learn from speech data that vary in ways not explained by the corresponding text. One way to reduce the amount of unexplained variation in training data is to provide acoustic information as an additional learning signal. When generating speech, modifying this acoustic information enables multiple distinct renditions of a text to be produced. Since much of the unexplained variation is in the prosody, we propose a model that generates speech explicitly conditioned on the three primary acoustic correlates of prosody: $F_{0}$, energy and duration. The model is flexible about how the values of these features are specified: they can be externally provided, or predicted from text, or predicted then subsequently modified. Compared to a model that employs a variational auto-encoder to learn unsupervised latent features, our model provides more interpretable, temporally-precise, and disentangled control. When automatically predicting the acoustic features from text, it generates speech that is more natural than that from a Tacotron 2 model with reference encoder. Subsequent human-in-the-loop modification of the predicted acoustic features can significantly further increase naturalness.
ADEPT: A Dataset for Evaluating Prosody Transfer
Jun 15, 2021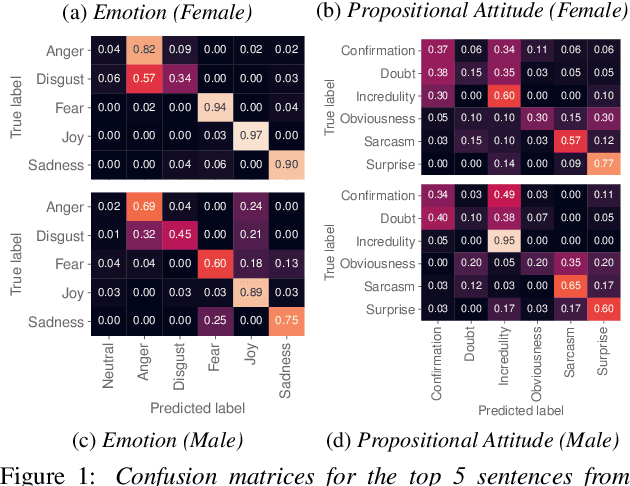
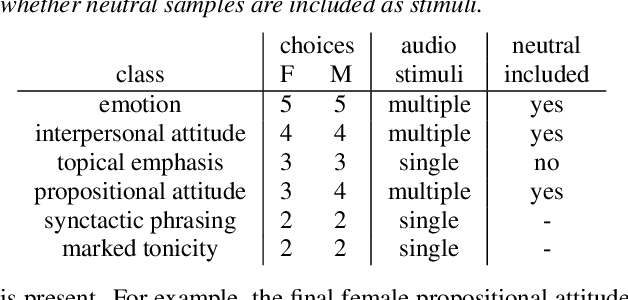
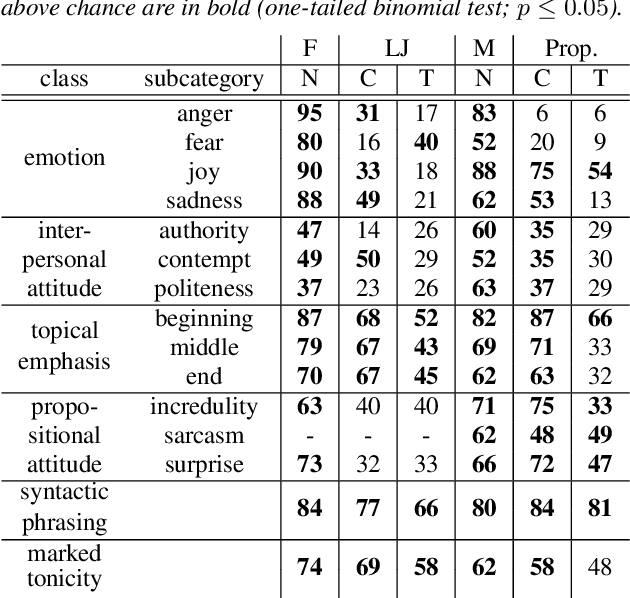
Text-to-speech is now able to achieve near-human naturalness and research focus has shifted to increasing expressivity. One popular method is to transfer the prosody from a reference speech sample. There have been considerable advances in using prosody transfer to generate more expressive speech, but the field lacks a clear definition of what successful prosody transfer means and a method for measuring it. We introduce a dataset of prosodically-varied reference natural speech samples for evaluating prosody transfer. The samples include global variations reflecting emotion and interpersonal attitude, and local variations reflecting topical emphasis, propositional attitude, syntactic phrasing and marked tonicity. The corpus only includes prosodic variations that listeners are able to distinguish with reasonable accuracy, and we report these figures as a benchmark against which text-to-speech prosody transfer can be compared. We conclude the paper with a demonstration of our proposed evaluation methodology, using the corpus to evaluate two text-to-speech models that perform prosody transfer.