 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCtrl-P: Temporal Control of Prosodic Variation for Speech Synthesis
Paper and Code
Jun 15, 2021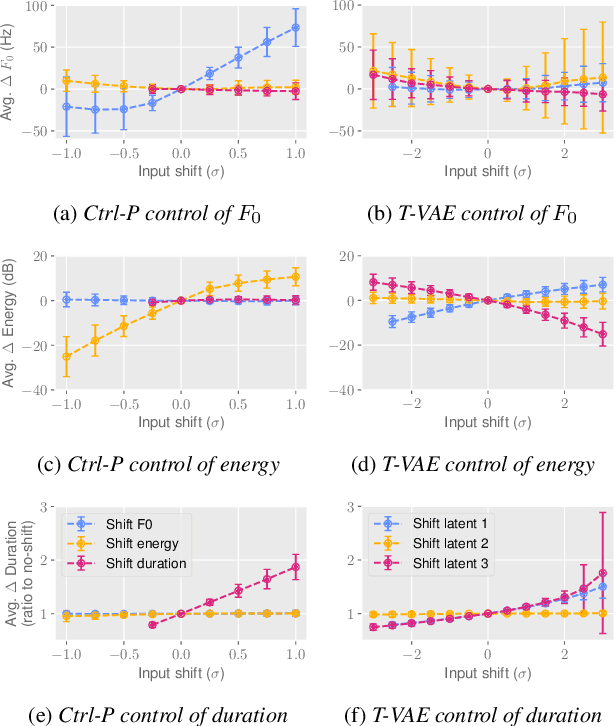
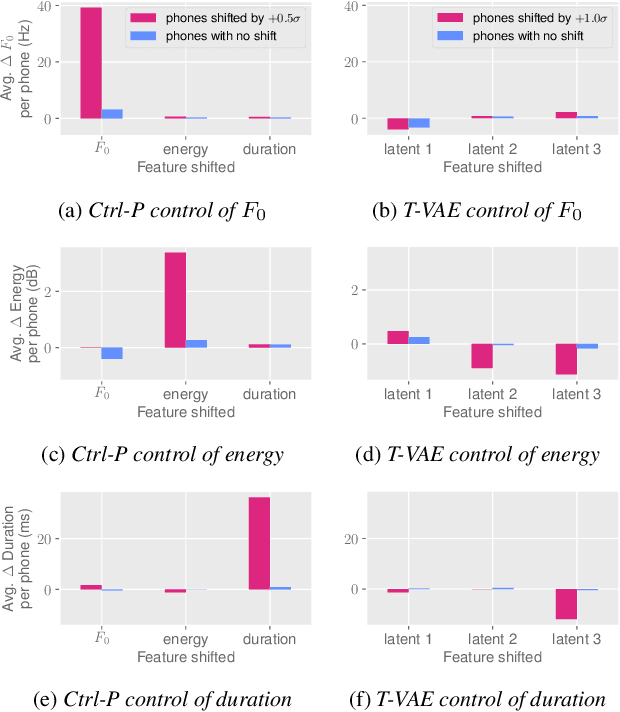
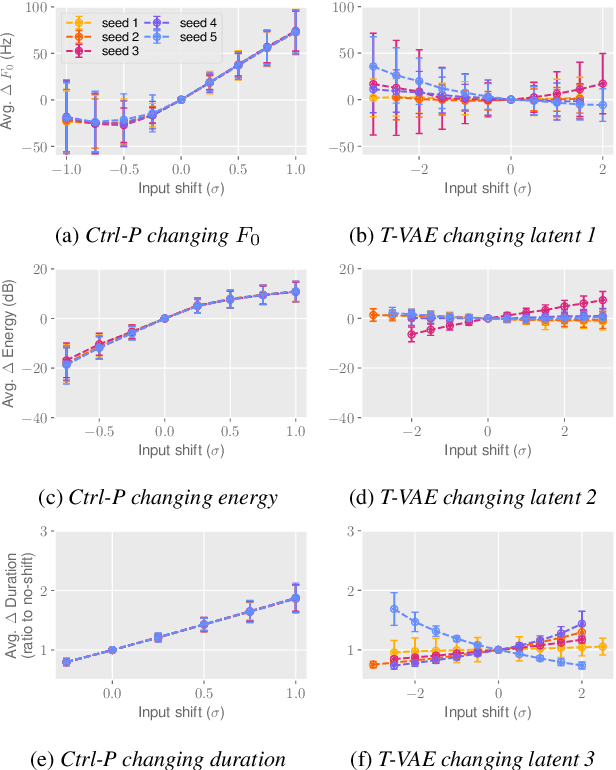
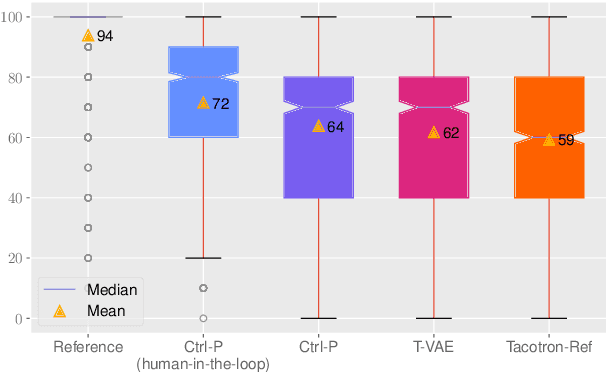
Text does not fully specify the spoken form, so text-to-speech models must be able to learn from speech data that vary in ways not explained by the corresponding text. One way to reduce the amount of unexplained variation in training data is to provide acoustic information as an additional learning signal. When generating speech, modifying this acoustic information enables multiple distinct renditions of a text to be produced. Since much of the unexplained variation is in the prosody, we propose a model that generates speech explicitly conditioned on the three primary acoustic correlates of prosody: $F_{0}$, energy and duration. The model is flexible about how the values of these features are specified: they can be externally provided, or predicted from text, or predicted then subsequently modified. Compared to a model that employs a variational auto-encoder to learn unsupervised latent features, our model provides more interpretable, temporally-precise, and disentangled control. When automatically predicting the acoustic features from text, it generates speech that is more natural than that from a Tacotron 2 model with reference encoder. Subsequent human-in-the-loop modification of the predicted acoustic features can significantly further increase naturalness.