 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble prosody prediction for expressive speech synthesis
Apr 03, 2023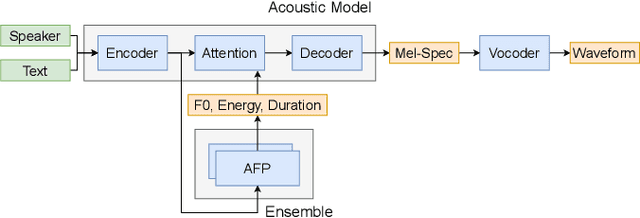

Generating expressive speech with rich and varied prosody continues to be a challenge for Text-to-Speech. Most efforts have focused on sophisticated neural architectures intended to better model the data distribution. Yet, in evaluations it is generally found that no single model is preferred for all input texts. This suggests an approach that has rarely been used before for Text-to-Speech: an ensemble of models. We apply ensemble learning to prosody prediction. We construct simple ensembles of prosody predictors by varying either model architecture or model parameter values. To automatically select amongst the models in the ensemble when performing Text-to-Speech, we propose a novel, and computationally trivial, variance-based criterion. We demonstrate that even a small ensemble of prosody predictors yields useful diversity, which, combined with the proposed selection criterion, outperforms any individual model from the ensemble.
Ctrl-P: Temporal Control of Prosodic Variation for Speech Synthesis
Jun 15, 2021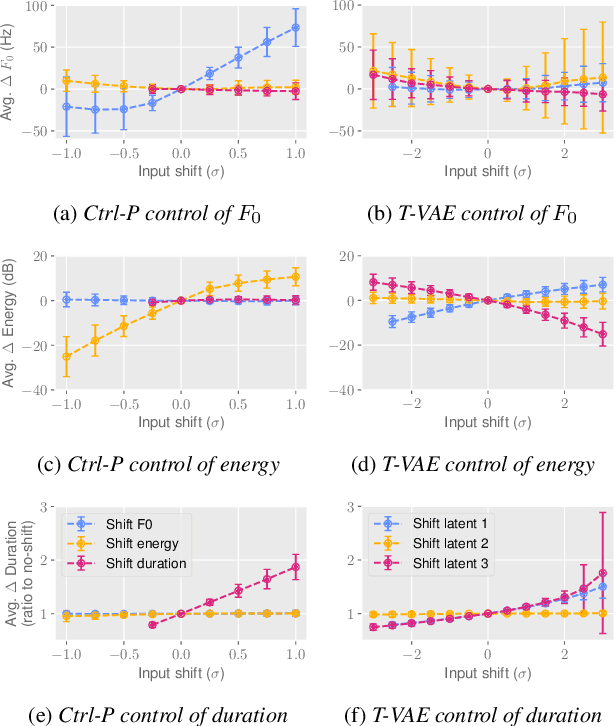
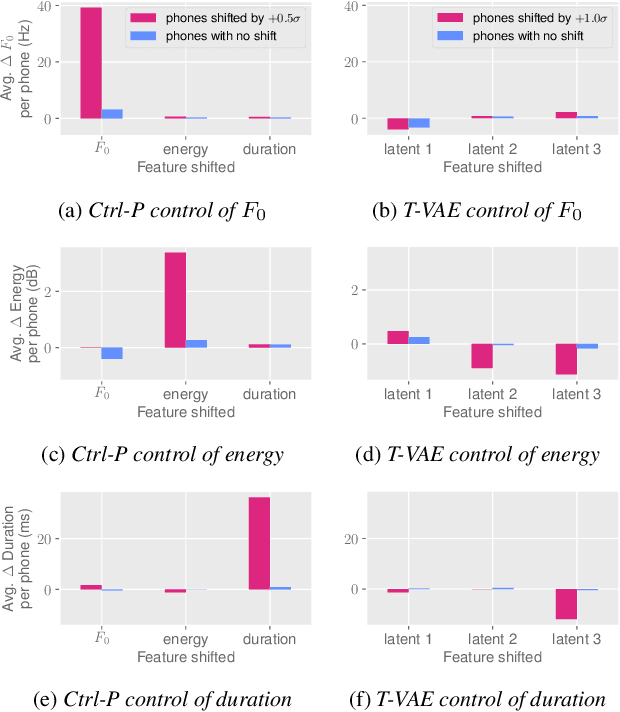
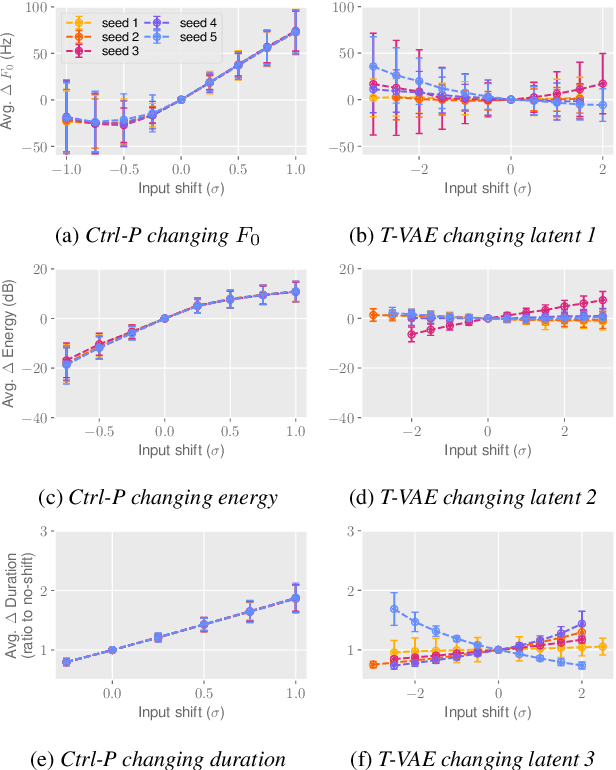
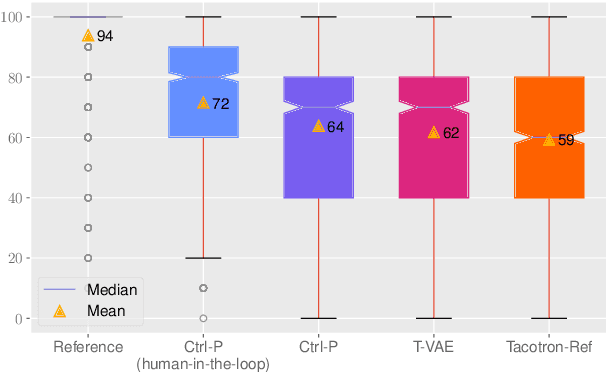
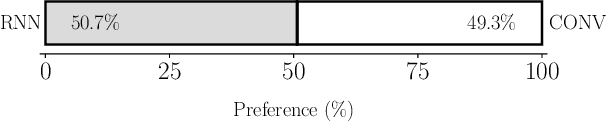
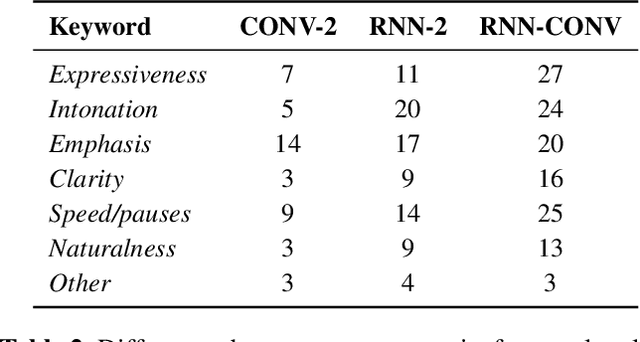
Text does not fully specify the spoken form, so text-to-speech models must be able to learn from speech data that vary in ways not explained by the corresponding text. One way to reduce the amount of unexplained variation in training data is to provide acoustic information as an additional learning signal. When generating speech, modifying this acoustic information enables multiple distinct renditions of a text to be produced. Since much of the unexplained variation is in the prosody, we propose a model that generates speech explicitly conditioned on the three primary acoustic correlates of prosody: $F_{0}$, energy and duration. The model is flexible about how the values of these features are specified: they can be externally provided, or predicted from text, or predicted then subsequently modified. Compared to a model that employs a variational auto-encoder to learn unsupervised latent features, our model provides more interpretable, temporally-precise, and disentangled control. When automatically predicting the acoustic features from text, it generates speech that is more natural than that from a Tacotron 2 model with reference encoder. Subsequent human-in-the-loop modification of the predicted acoustic features can significantly further increase naturalness.
ADEPT: A Dataset for Evaluating Prosody Transfer
Jun 15, 2021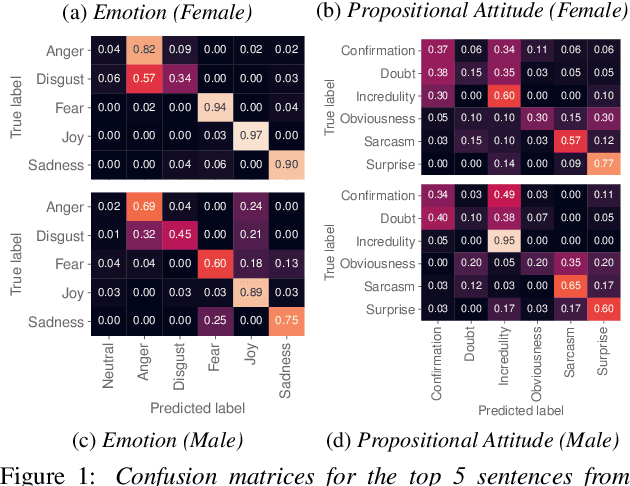
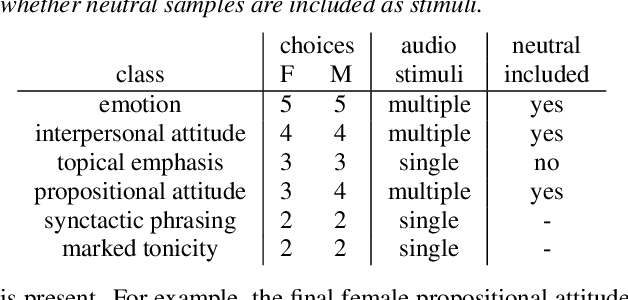
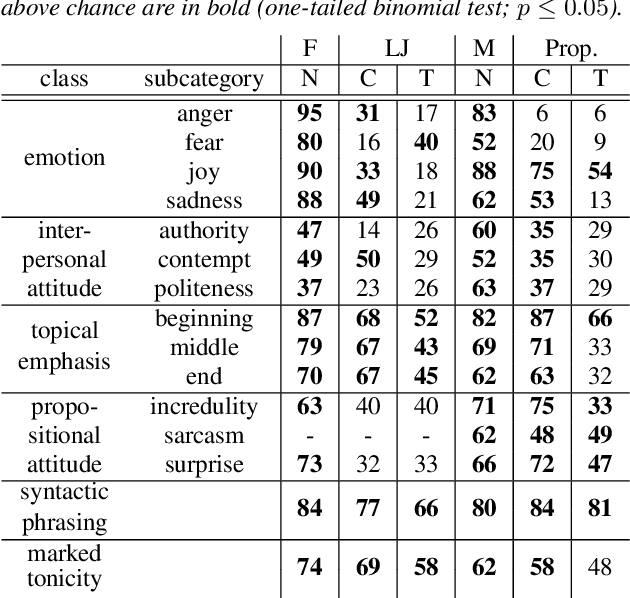
Text-to-speech is now able to achieve near-human naturalness and research focus has shifted to increasing expressivity. One popular method is to transfer the prosody from a reference speech sample. There have been considerable advances in using prosody transfer to generate more expressive speech, but the field lacks a clear definition of what successful prosody transfer means and a method for measuring it. We introduce a dataset of prosodically-varied reference natural speech samples for evaluating prosody transfer. The samples include global variations reflecting emotion and interpersonal attitude, and local variations reflecting topical emphasis, propositional attitude, syntactic phrasing and marked tonicity. The corpus only includes prosodic variations that listeners are able to distinguish with reasonable accuracy, and we report these figures as a benchmark against which text-to-speech prosody transfer can be compared. We conclude the paper with a demonstration of our proposed evaluation methodology, using the corpus to evaluate two text-to-speech models that perform prosody transfer.
Scattering Networks on the Sphere for Scalable and Rotationally Equivariant Spherical CNNs
Feb 18, 2021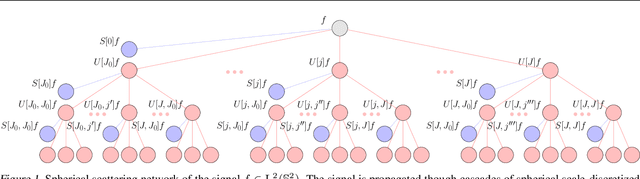
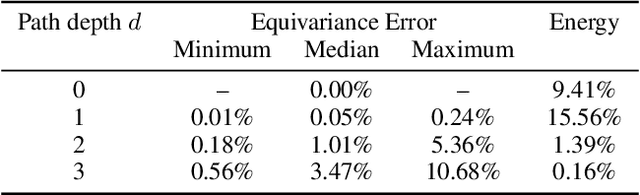
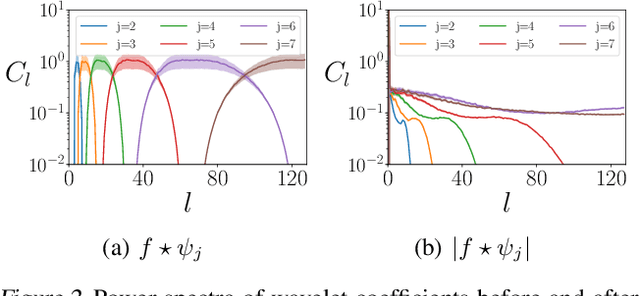
Convolutional neural networks (CNNs) constructed natively on the sphere have been developed recently and shown to be highly effective for the analysis of spherical data. While an efficient framework has been formulated, spherical CNNs are nevertheless highly computationally demanding; typically they cannot scale beyond spherical signals of thousands of pixels. We develop scattering networks constructed natively on the sphere that provide a powerful representational space for spherical data. Spherical scattering networks are computationally scalable and exhibit rotational equivariance, while their representational space is invariant to isometries and provides efficient and stable signal representations. By integrating scattering networks as an additional type of layer in the generalized spherical CNN framework, we show how they can be leveraged to scale spherical CNNs to the high-resolution data typical of many practical applications, with spherical signals of many tens of megapixels and beyond.
Efficient Generalized Spherical CNNs
Oct 23, 2020
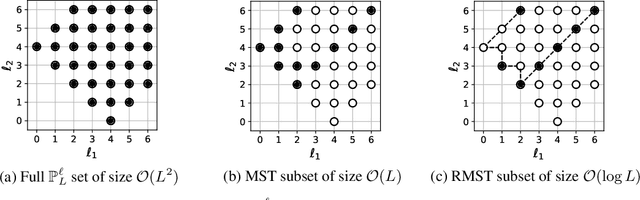
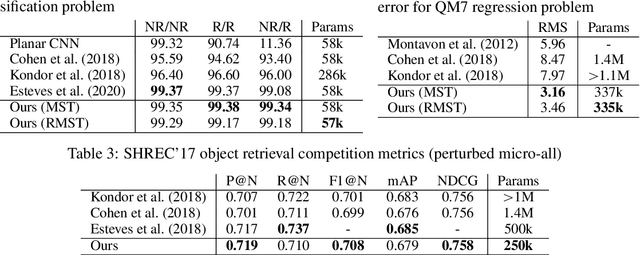
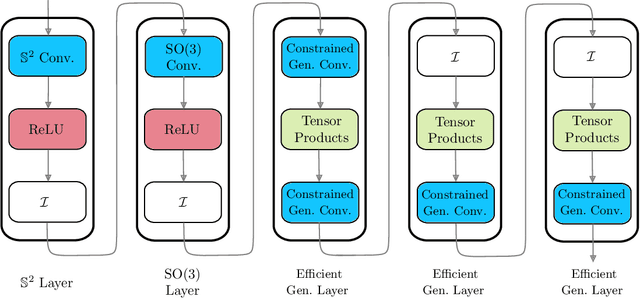
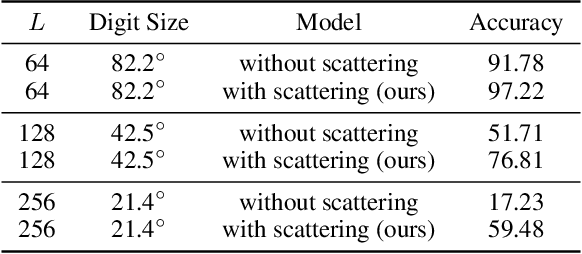
Many problems across computer vision and the natural sciences require the analysis of spherical data, for which representations may be learned efficiently by encoding equivariance to rotational symmetries. We present a generalized spherical CNN framework that encompasses various existing approaches and allows them to be leveraged alongside each other. The only existing non-linear spherical CNN layer that is strictly equivariant has complexity $\mathcal{O}(C^2L^5)$, where $C$ is a measure of representational capacity and $L$ the spherical harmonic bandlimit. Such a high computational cost often prohibits the use of strictly equivariant spherical CNNs. We develop two new strictly equivariant layers with reduced complexity $\mathcal{O}(CL^4)$ and $\mathcal{O}(CL^3 \log L)$, making larger, more expressive models computationally feasible. Moreover, we adopt efficient sampling theory to achieve further computational savings. We show that these developments allow the construction of more expressive hybrid models that achieve state-of-the-art accuracy and parameter efficiency on spherical benchmark problems.
Wavelet-Based Segmentation on the Sphere
Sep 21, 2016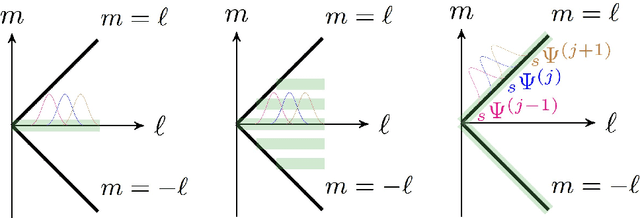
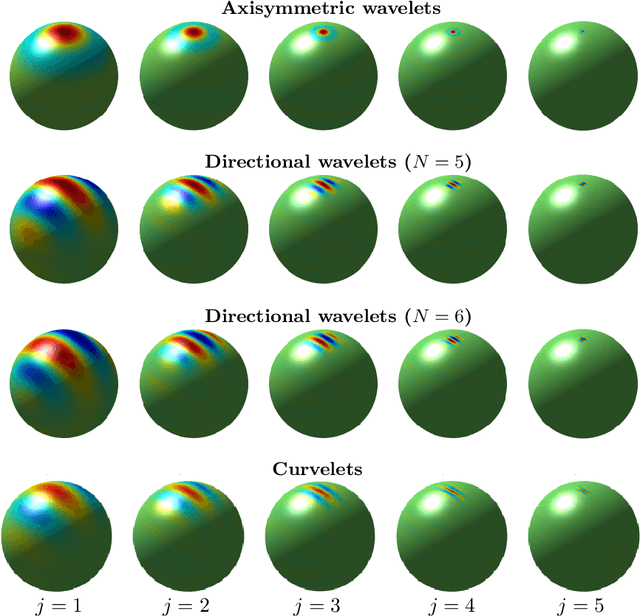
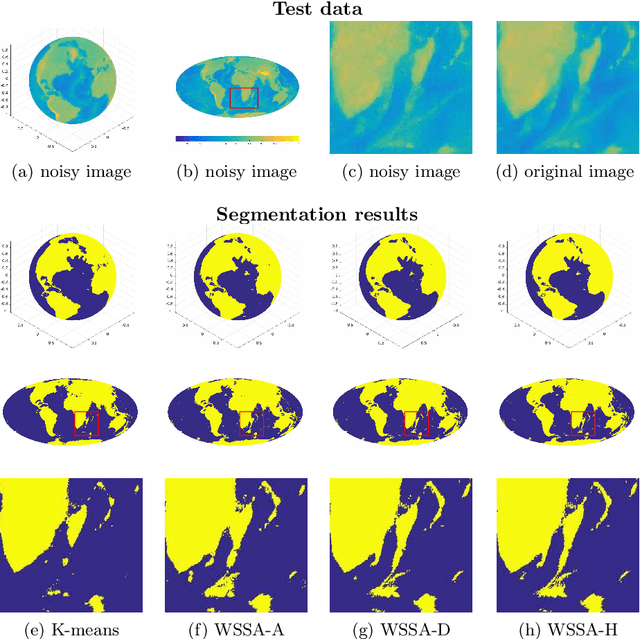
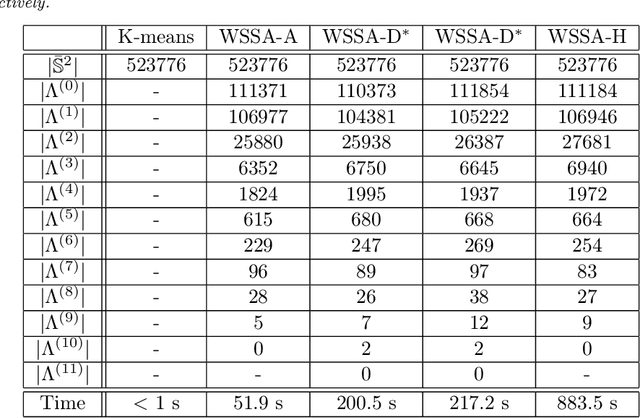
Segmentation is the process of identifying object outlines within images. There are a number of efficient algorithms for segmentation in Euclidean space that depend on the variational approach and partial differential equation modelling. Wavelets have been used successfully in various problems in image processing, including segmentation, inpainting, noise removal, super-resolution image restoration, and many others. Wavelets on the sphere have been developed to solve such problems for data defined on the sphere, which arise in numerous fields such as cosmology and geophysics. In this work, we propose a wavelet-based method to segment images on the sphere, accounting for the underlying geometry of spherical data. Our method is a direct extension of the tight-frame based segmentation method used to automatically identify tube-like structures such as blood vessels in medical imaging. It is compatible with any arbitrary type of wavelet frame defined on the sphere, such as axisymmetric wavelets, directional wavelets, curvelets, and hybrid wavelet constructions. Such an approach allows the desirable properties of wavelets to be naturally inherited in the segmentation process. In particular, directional wavelets and curvelets, which were designed to efficiently capture directional signal content, provide additional advantages in segmenting images containing prominent directional and curvilinear features. We present several numerical experiments, applying our wavelet-based segmentation method, as well as the common K-means method, on real-world spherical images. These experiments demonstrate the superiority of our method and show that it is capable of segmenting different kinds of spherical images, including those with prominent directional features. Moreover, our algorithm is efficient with convergence usually within a few iterations.