 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Distribution-Aware Testing of Deep Learning
May 17, 2022
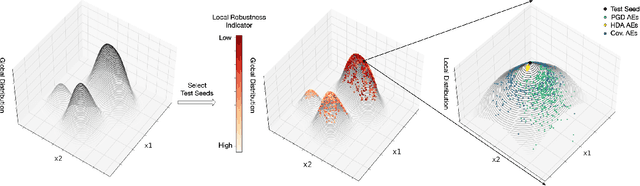

With its growing use in safety/security-critical applications, Deep Learning (DL) has raised increasing concerns regarding its dependability. In particular, DL has a notorious problem of lacking robustness. Despite recent efforts made in detecting Adversarial Examples (AEs) via state-of-the-art attacking and testing methods, they are normally input distribution agnostic and/or disregard the perception quality of AEs. Consequently, the detected AEs are irrelevant inputs in the application context or unnatural/unrealistic that can be easily noticed by humans. This may lead to a limited effect on improving the DL model's dependability, as the testing budget is likely to be wasted on detecting AEs that are encountered very rarely in its real-life operations. In this paper, we propose a new robustness testing approach for detecting AEs that considers both the input distribution and the perceptual quality of inputs. The two considerations are encoded by a novel hierarchical mechanism. First, at the feature level, the input data distribution is extracted and approximated by data compression techniques and probability density estimators. Such quantified feature level distribution, together with indicators that are highly correlated with local robustness, are considered in selecting test seeds. Given a test seed, we then develop a two-step genetic algorithm for local test case generation at the pixel level, in which two fitness functions work alternatively to control the quality of detected AEs. Finally, extensive experiments confirm that our holistic approach considering hierarchical distributions at feature and pixel levels is superior to state-of-the-arts that either disregard any input distribution or only consider a single (non-hierarchical) distribution, in terms of not only the quality of detected AEs but also improving the overall robustness of the DL model under testing.
Reliability Assessment and Safety Arguments for Machine Learning Components in Assuring Learning-Enabled Autonomous Systems
Nov 30, 2021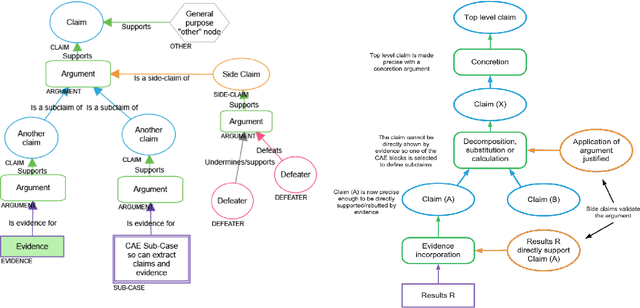

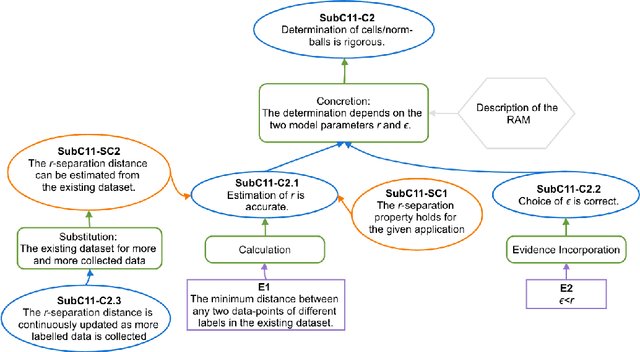
The increasing use of Machine Learning (ML) components embedded in autonomous systems -- so-called Learning-Enabled Systems (LES) -- has resulted in the pressing need to assure their functional safety. As for traditional functional safety, the emerging consensus within both, industry and academia, is to use assurance cases for this purpose. Typically assurance cases support claims of reliability in support of safety, and can be viewed as a structured way of organising arguments and evidence generated from safety analysis and reliability modelling activities. While such assurance activities are traditionally guided by consensus-based standards developed from vast engineering experience, LES pose new challenges in safety-critical application due to the characteristics and design of ML models. In this article, we first present an overall assurance framework for LES with an emphasis on quantitative aspects, e.g., breaking down system-level safety targets to component-level requirements and supporting claims stated in reliability metrics. We then introduce a novel model-agnostic Reliability Assessment Model (RAM) for ML classifiers that utilises the operational profile and robustness verification evidence. We discuss the model assumptions and the inherent challenges of assessing ML reliability uncovered by our RAM and propose practical solutions. Probabilistic safety arguments at the lower ML component-level are also developed based on the RAM. Finally, to evaluate and demonstrate our methods, we not only conduct experiments on synthetic/benchmark datasets but also demonstrate the scope of our methods with a comprehensive case study on Autonomous Underwater Vehicles in simulation.
Assessing the Reliability of Deep Learning Classifiers Through Robustness Evaluation and Operational Profiles
Jun 02, 2021

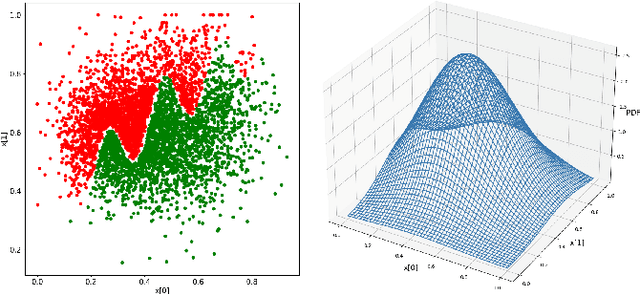
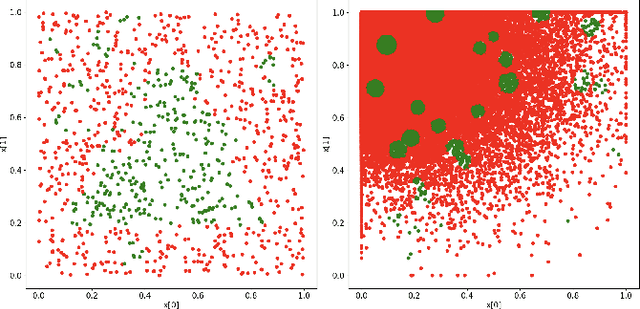
The utilisation of Deep Learning (DL) is advancing into increasingly more sophisticated applications. While it shows great potential to provide transformational capabilities, DL also raises new challenges regarding its reliability in critical functions. In this paper, we present a model-agnostic reliability assessment method for DL classifiers, based on evidence from robustness evaluation and the operational profile (OP) of a given application. We partition the input space into small cells and then "assemble" their robustness (to the ground truth) according to the OP, where estimators on the cells' robustness and OPs are provided. Reliability estimates in terms of the probability of misclassification per input (pmi) can be derived together with confidence levels. A prototype tool is demonstrated with simplified case studies. Model assumptions and extension to real-world applications are also discussed. While our model easily uncovers the inherent difficulties of assessing the DL dependability (e.g. lack of data with ground truth and scalability issues), we provide preliminary/compromised solutions to advance in this research direction.