 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge language model for Bible sentiment analysis: Sermon on the Mount
Jan 01, 2024
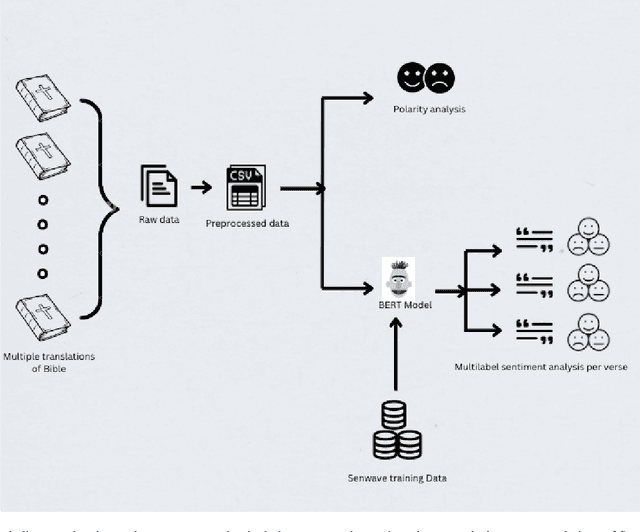
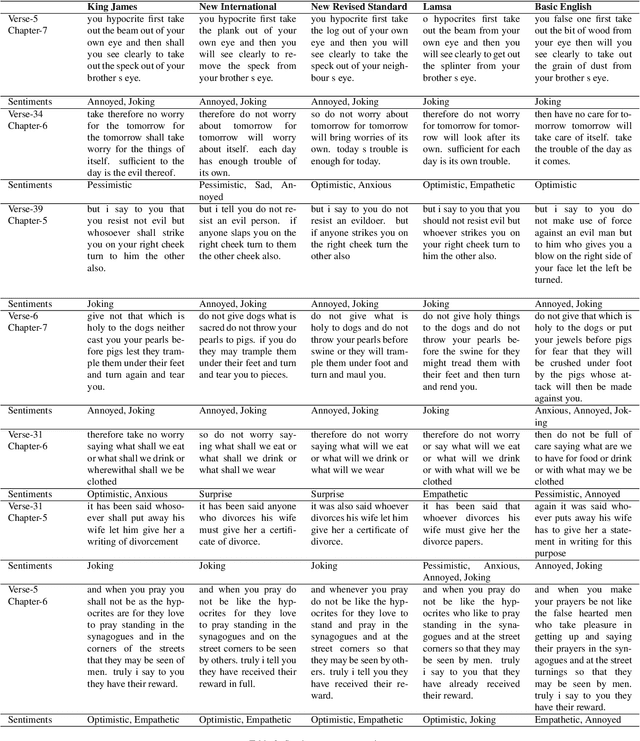
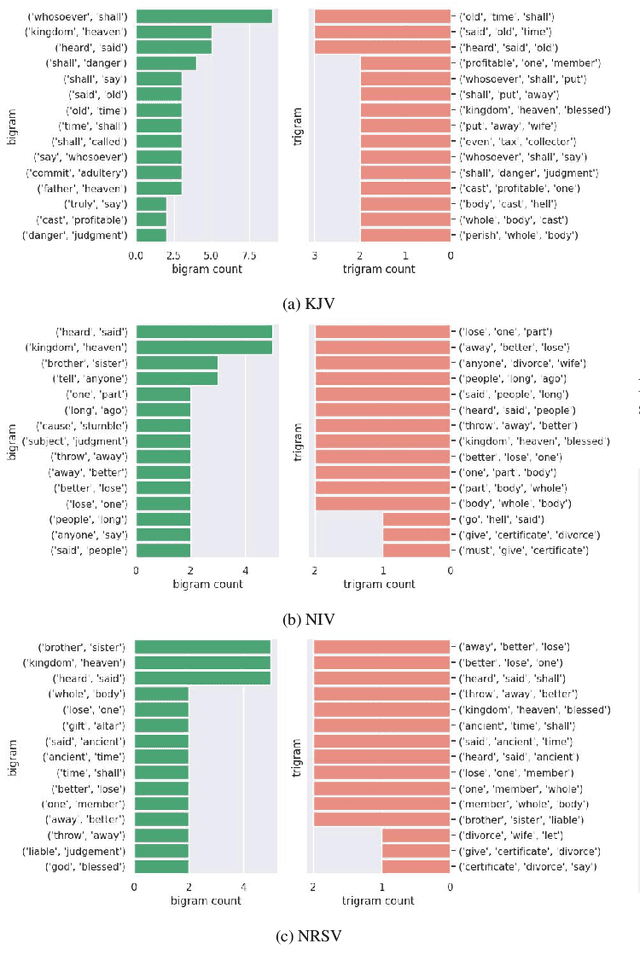
The revolution of natural language processing via large language models has motivated its use in multidisciplinary areas that include social sciences and humanities and more specifically, comparative religion. Sentiment analysis provides a mechanism to study the emotions expressed in text. Recently, sentiment analysis has been used to study and compare translations of the Bhagavad Gita, which is a fundamental and sacred Hindu text. In this study, we use sentiment analysis for studying selected chapters of the Bible. These chapters are known as the Sermon on the Mount. We utilize a pre-trained language model for sentiment analysis by reviewing five translations of the Sermon on the Mount, which include the King James version, the New International Version, the New Revised Standard Version, the Lamsa Version, and the Basic English Version. We provide a chapter-by-chapter and verse-by-verse comparison using sentiment and semantic analysis and review the major sentiments expressed. Our results highlight the varying sentiments across the chapters and verses. We found that the vocabulary of the respective translations is significantly different. We detected different levels of humour, optimism, and empathy in the respective chapters that were used by Jesus to deliver his message.
Cross-Entropy Estimators for Sequential Experiment Design with Reinforcement Learning
May 29, 2023
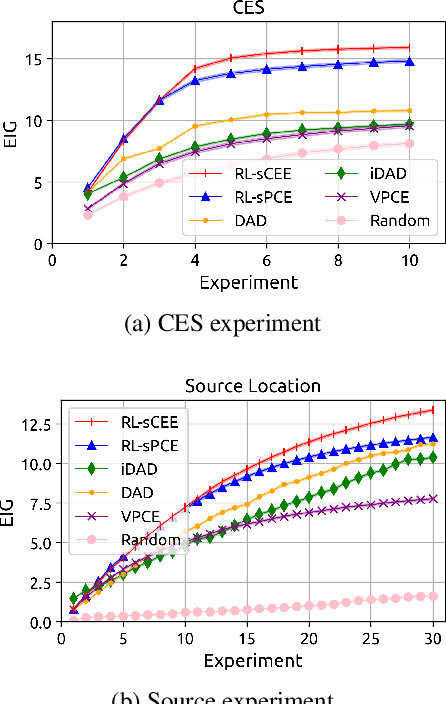
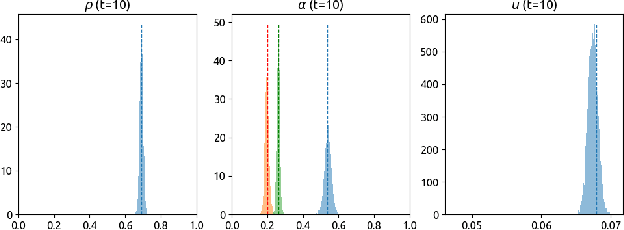
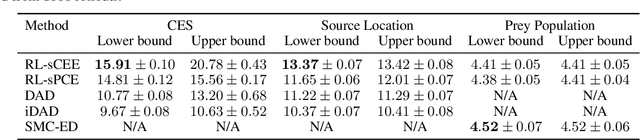
Reinforcement learning can effectively learn amortised design policies for designing sequences of experiments. However, current methods rely on contrastive estimators of expected information gain, which require an exponential number of contrastive samples to achieve an unbiased estimation. We propose an alternative lower bound estimator, based on the cross-entropy of the joint model distribution and a flexible proposal distribution. This proposal distribution approximates the true posterior of the model parameters given the experimental history and the design policy. Our estimator requires no contrastive samples, can achieve more accurate estimates of high information gains, allows learning of superior design policies, and is compatible with implicit probabilistic models. We assess our algorithm's performance in various tasks, including continuous and discrete designs and explicit and implicit likelihoods.
Optimizing Sequential Experimental Design with Deep Reinforcement Learning
Feb 02, 2022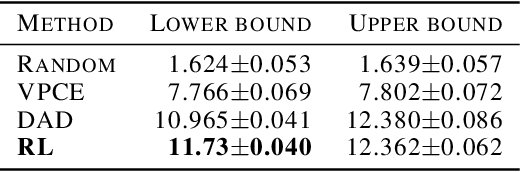
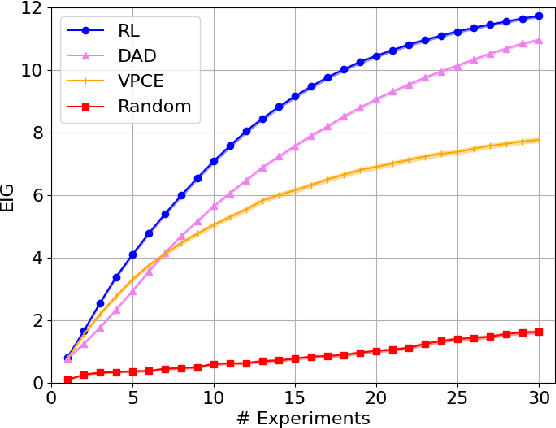
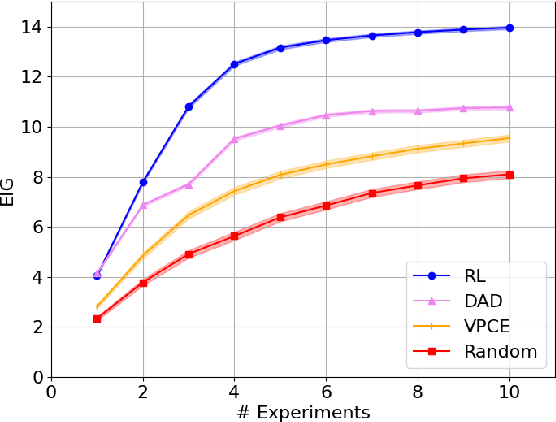
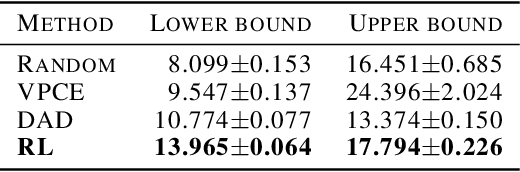
Bayesian approaches developed to solve the optimal design of sequential experiments are mathematically elegant but computationally challenging. Recently, techniques using amortization have been proposed to make these Bayesian approaches practical, by training a parameterized policy that proposes designs efficiently at deployment time. However, these methods may not sufficiently explore the design space, require access to a differentiable probabilistic model and can only optimize over continuous design spaces. Here, we address these limitations by showing that the problem of optimizing policies can be reduced to solving a Markov decision process (MDP). We solve the equivalent MDP with modern deep reinforcement learning techniques. Our experiments show that our approach is also computationally efficient at deployment time and exhibits state-of-the-art performance on both continuous and discrete design spaces, even when the probabilistic model is a black box.
Learning from Demonstration without Demonstrations
Jun 17, 2021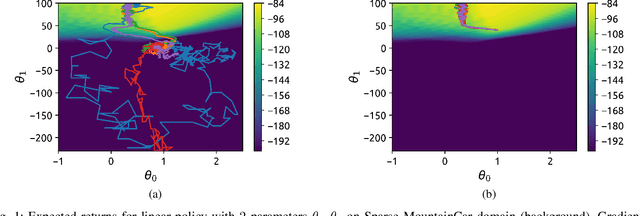
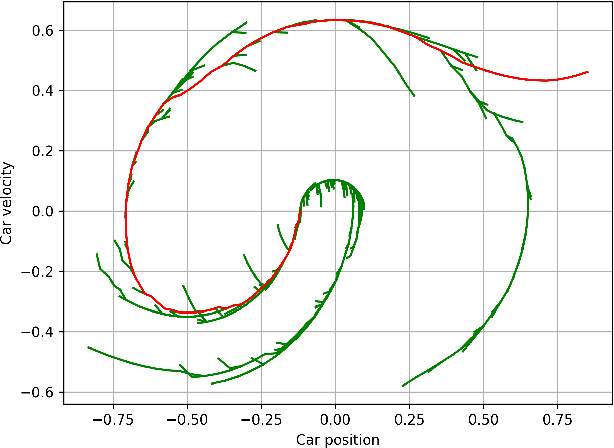
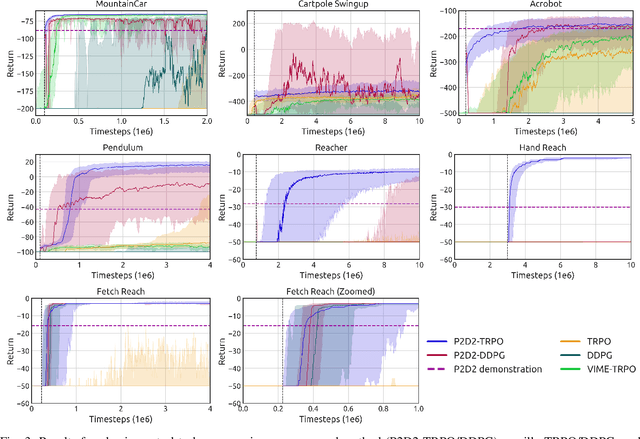
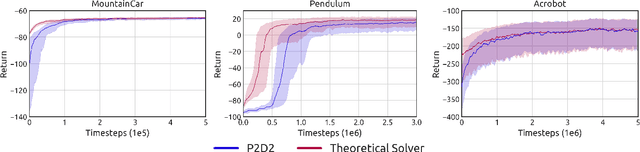
State-of-the-art reinforcement learning (RL) algorithms suffer from high sample complexity, particularly in the sparse reward case. A popular strategy for mitigating this problem is to learn control policies by imitating a set of expert demonstrations. The drawback of such approaches is that an expert needs to produce demonstrations, which may be costly in practice. To address this shortcoming, we propose Probabilistic Planning for Demonstration Discovery (P2D2), a technique for automatically discovering demonstrations without access to an expert. We formulate discovering demonstrations as a search problem and leverage widely-used planning algorithms such as Rapidly-exploring Random Tree to find demonstration trajectories. These demonstrations are used to initialize a policy, then refined by a generic RL algorithm. We provide theoretical guarantees of P2D2 finding successful trajectories, as well as bounds for its sampling complexity. We experimentally demonstrate the method outperforms classic and intrinsic exploration RL techniques in a range of classic control and robotics tasks, requiring only a fraction of exploration samples and achieving better asymptotic performance.
Reinforcement Learning with Probabilistically Complete Exploration
Jan 20, 2020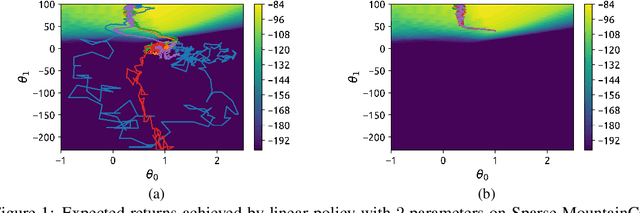

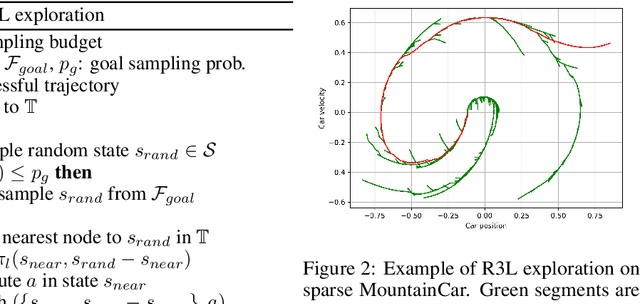
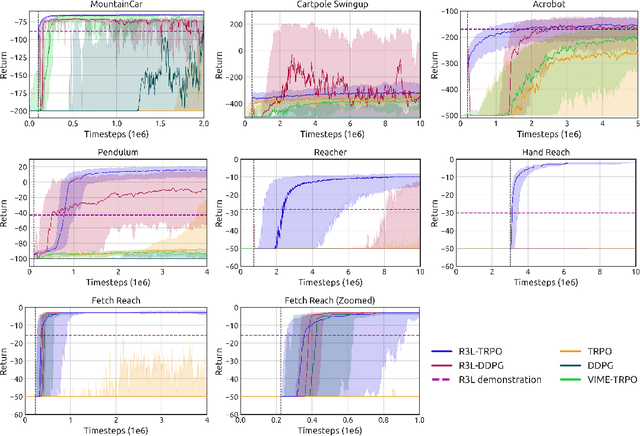
Balancing exploration and exploitation remains a key challenge in reinforcement learning (RL). State-of-the-art RL algorithms suffer from high sample complexity, particularly in the sparse reward case, where they can do no better than to explore in all directions until the first positive rewards are found. To mitigate this, we propose Rapidly Randomly-exploring Reinforcement Learning (R3L). We formulate exploration as a search problem and leverage widely-used planning algorithms such as Rapidly-exploring Random Tree (RRT) to find initial solutions. These solutions are used as demonstrations to initialize a policy, then refined by a generic RL algorithm, leading to faster and more stable convergence. We provide theoretical guarantees of R3L exploration finding successful solutions, as well as bounds for its sampling complexity. We experimentally demonstrate the method outperforms classic and intrinsic exploration techniques, requiring only a fraction of exploration samples and achieving better asymptotic performance.
Bayesian Curiosity for Efficient Exploration in Reinforcement Learning
Nov 20, 2019
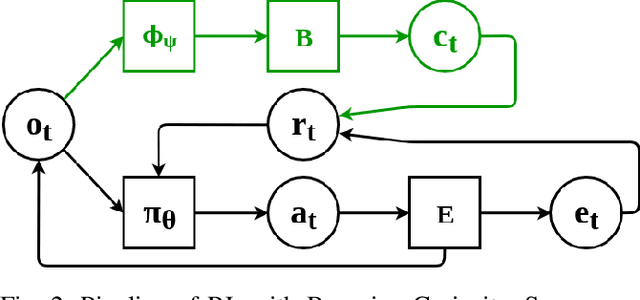
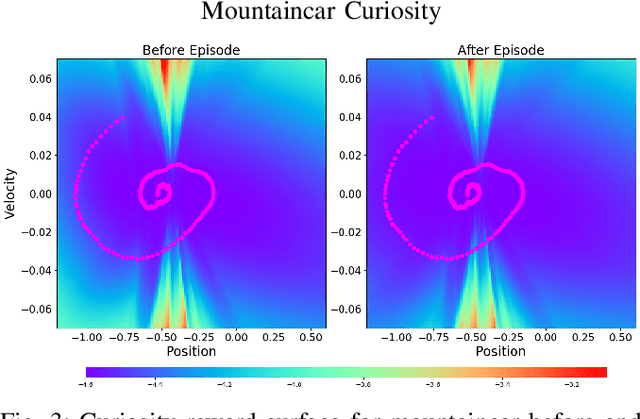
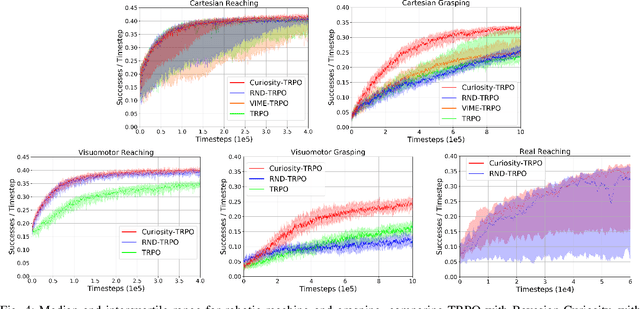
Balancing exploration and exploitation is a fundamental part of reinforcement learning, yet most state-of-the-art algorithms use a naive exploration protocol like $\epsilon$-greedy. This contributes to the problem of high sample complexity, as the algorithm wastes effort by repeatedly visiting parts of the state space that have already been explored. We introduce a novel method based on Bayesian linear regression and latent space embedding to generate an intrinsic reward signal that encourages the learning agent to seek out unexplored parts of the state space. This method is computationally efficient, simple to implement, and can extend any state-of-the-art reinforcement learning algorithm. We evaluate the method on a range of algorithms and challenging control tasks, on both simulated and physical robots, demonstrating how the proposed method can significantly improve sample complexity.