 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCovariate Dependent Mixture of Bayesian Networks
Jan 10, 2025



Learning the structure of Bayesian networks from data provides insights into underlying processes and the causal relationships that generate the data, but its usefulness depends on the homogeneity of the data population, a condition often violated in real-world applications. In such cases, using a single network structure for inference can be misleading, as it may not capture sub-population differences. To address this, we propose a novel approach of modelling a mixture of Bayesian networks where component probabilities depend on individual characteristics. Our method identifies both network structures and demographic predictors of sub-population membership, aiding personalised interventions. We evaluate our method through simulations and a youth mental health case study, demonstrating its potential to improve tailored interventions in health, education, and social policy.
Optimal Particle-based Approximation of Discrete Distributions (OPAD)
Nov 30, 2024



Particle-based methods include a variety of techniques, such as Markov Chain Monte Carlo (MCMC) and Sequential Monte Carlo (SMC), for approximating a probabilistic target distribution with a set of weighted particles. In this paper, we prove that for any set of particles, there is a unique weighting mechanism that minimizes the Kullback-Leibler (KL) divergence of the (particle-based) approximation from the target distribution, when that distribution is discrete -- any other weighting mechanism (e.g. MCMC weighting that is based on particles' repetitions in the Markov chain) is sub-optimal with respect to this divergence measure. Our proof does not require any restrictions either on the target distribution, or the process by which the particles are generated, other than the discreteness of the target. We show that the optimal weights can be determined based on values that any existing particle-based method already computes; As such, with minimal modifications and no extra computational costs, the performance of any particle-based method can be improved. Our empirical evaluations are carried out on important applications of discrete distributions including Bayesian Variable Selection and Bayesian Structure Learning. The results illustrate that our proposed reweighting of the particles improves any particle-based approximation to the target distribution consistently and often substantially.
Learning from Demonstration without Demonstrations
Jun 17, 2021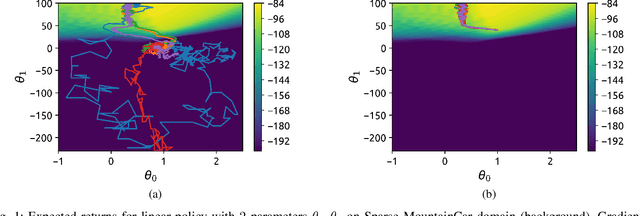
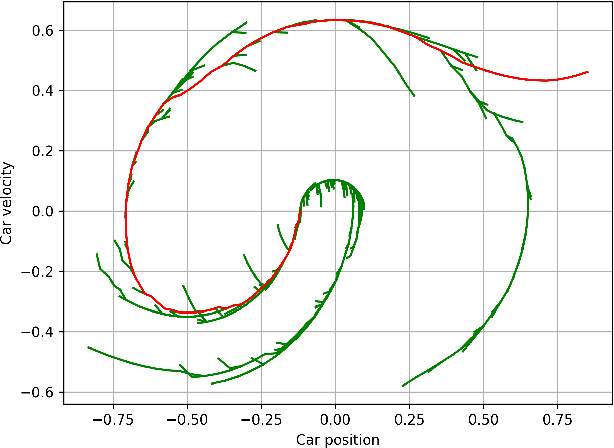
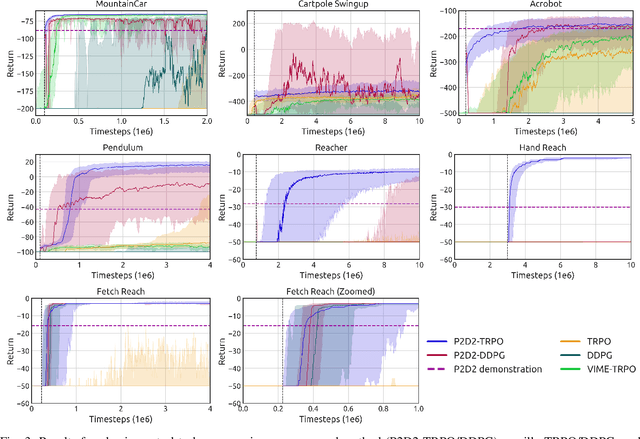
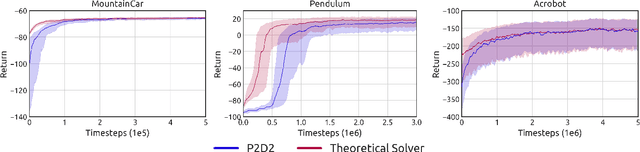
State-of-the-art reinforcement learning (RL) algorithms suffer from high sample complexity, particularly in the sparse reward case. A popular strategy for mitigating this problem is to learn control policies by imitating a set of expert demonstrations. The drawback of such approaches is that an expert needs to produce demonstrations, which may be costly in practice. To address this shortcoming, we propose Probabilistic Planning for Demonstration Discovery (P2D2), a technique for automatically discovering demonstrations without access to an expert. We formulate discovering demonstrations as a search problem and leverage widely-used planning algorithms such as Rapidly-exploring Random Tree to find demonstration trajectories. These demonstrations are used to initialize a policy, then refined by a generic RL algorithm. We provide theoretical guarantees of P2D2 finding successful trajectories, as well as bounds for its sampling complexity. We experimentally demonstrate the method outperforms classic and intrinsic exploration RL techniques in a range of classic control and robotics tasks, requiring only a fraction of exploration samples and achieving better asymptotic performance.
Clustering volatility regimes for dynamic trading strategies
Apr 21, 2020
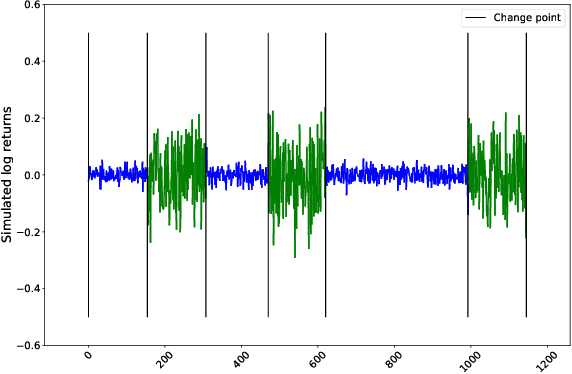
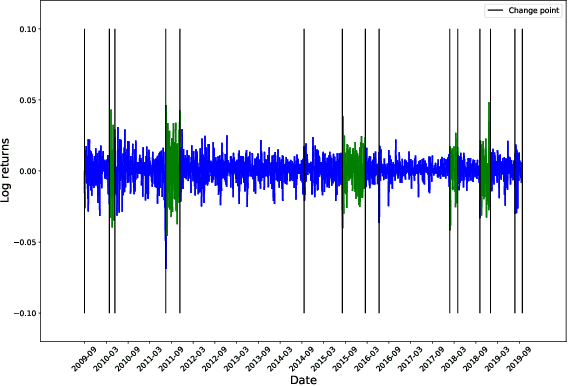
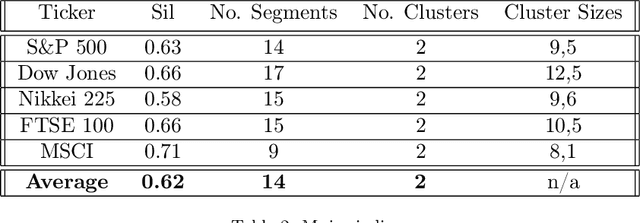
We develop a new method to find the number of volatility regimes in a non-stationary financial time series. We use change point detection to partition a time series into locally stationary segments, then estimate the distributions of each piece. The distributions are clustered into a learned number of discrete volatility regimes via an optimisation routine. Using this method, we investigate and determine a clustering structure for indices, large cap equities and exchange-traded funds. Finally, we create and validate a dynamic portfolio allocation strategy that learns the optimal match between the current distribution of a time series with its past regimes, thereby making online risk-avoidance decisions in the present.
Reinforcement Learning with Probabilistically Complete Exploration
Jan 20, 2020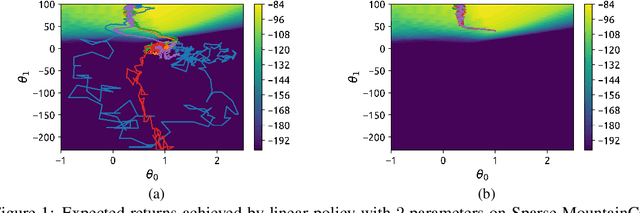

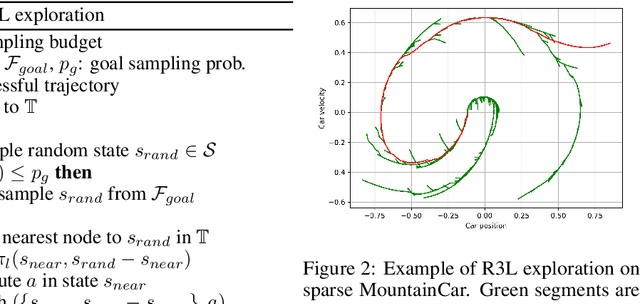
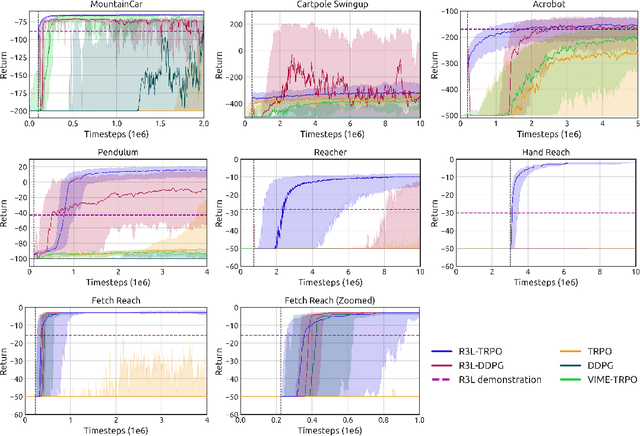
Balancing exploration and exploitation remains a key challenge in reinforcement learning (RL). State-of-the-art RL algorithms suffer from high sample complexity, particularly in the sparse reward case, where they can do no better than to explore in all directions until the first positive rewards are found. To mitigate this, we propose Rapidly Randomly-exploring Reinforcement Learning (R3L). We formulate exploration as a search problem and leverage widely-used planning algorithms such as Rapidly-exploring Random Tree (RRT) to find initial solutions. These solutions are used as demonstrations to initialize a policy, then refined by a generic RL algorithm, leading to faster and more stable convergence. We provide theoretical guarantees of R3L exploration finding successful solutions, as well as bounds for its sampling complexity. We experimentally demonstrate the method outperforms classic and intrinsic exploration techniques, requiring only a fraction of exploration samples and achieving better asymptotic performance.
OCTNet: Trajectory Generation in New Environments from Past Experiences
Sep 25, 2019
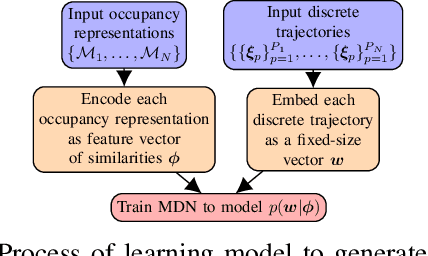
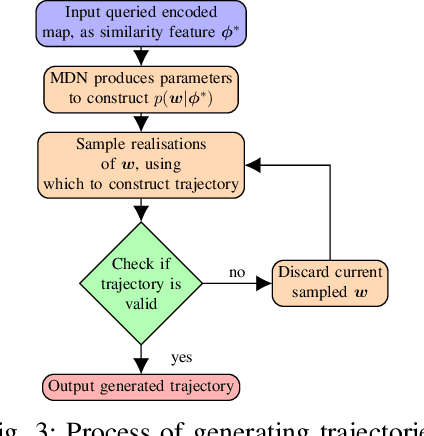
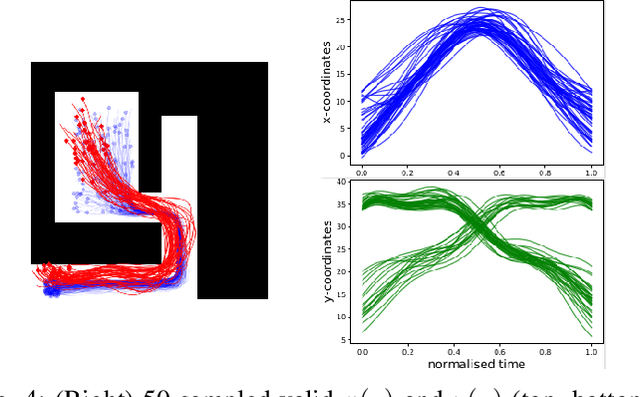
Being able to safely operate for extended periods of time in dynamic environments is a critical capability for autonomous systems. This generally involves the prediction and understanding of motion patterns of dynamic entities, such as vehicles and people, in the surroundings. Many motion prediction methods in the literature can learn a function, mapping position and time to potential trajectories taken by people or other dynamic entities. However, these predictions depend only on previously observed trajectories, and do not explicitly take into consideration the environment. Trends of motion obtained in one environment are typically specific to that environment, and are not used to better predict motion in other environments. In this paper, we address the problem of generating likely motion dynamics conditioned on the environment, represented as an occupancy map. We introduce the Occupancy Conditional Trajectory Network (OCTNet) framework, capable of generalising the previously observed motion in known environments, to generate trajectories in new environments where no observations of motion has not been observed. OCTNet encodes trajectories as a fixed-sized vector of parameters and utilises neural networks to learn conditional distributions over parameters. We empirically demonstrate our method's ability to generate complex multi-modal trajectory patterns in different environments.
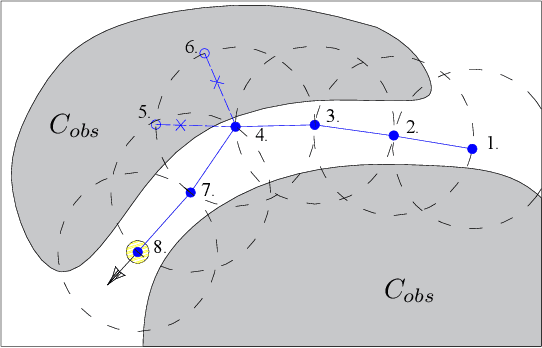
Local Sampling-based Planning with Sequential Bayesian Updates
Sep 08, 2019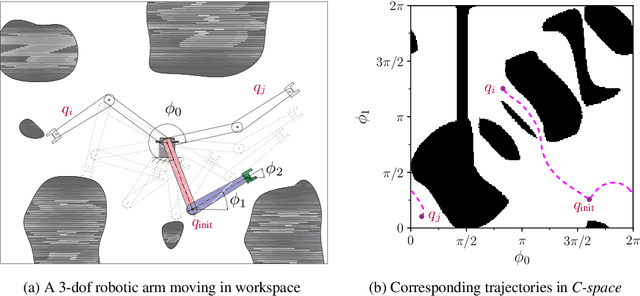
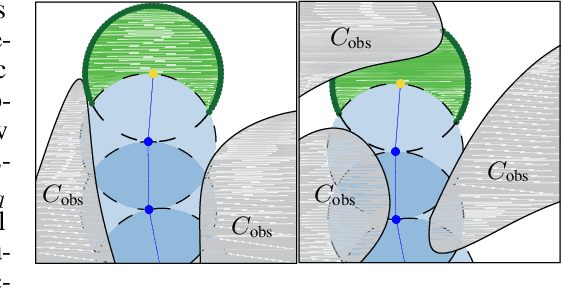
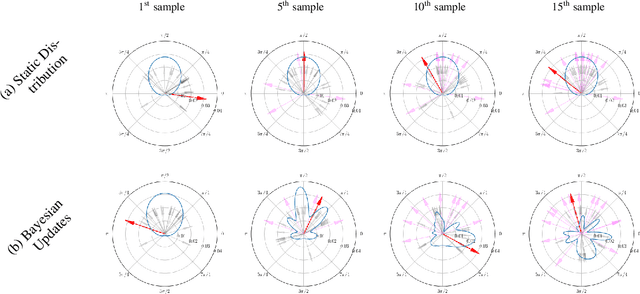
Sampling-based planners are the predominant motion planning paradigm for robots. Majority of sampling-based planners use a global random sampling scheme to guarantee completeness. However, these schemes are sample inefficient as the majority of the samples are wasted in narrow passages. Consequently, information about the local structure is neglected. Local sampling-based motion planners, on the other hand, take sequential decisions of random walks to samples valid trajectories in configuration space. However, current approaches do not adapt their strategies according to the success and failures of past samples. In this work, we introduce a local sampling-based motion planner with a Bayesian update scheme for modelling a sampling proposal distribution. The proposal distribution is sequentially updated based on previous sample outcomes, consequently shaping the proposal distribution according to local obstacles and constraints in the configuration space. Thus, through learning from past observed outcomes, we can maximise the likelihood of sampling in regions that have a higher probability to form trajectories within narrow passages.
Balancing Global Exploration and Local-connectivity Exploitation with Rapidly-exploring Random disjointed-Trees
Feb 27, 2019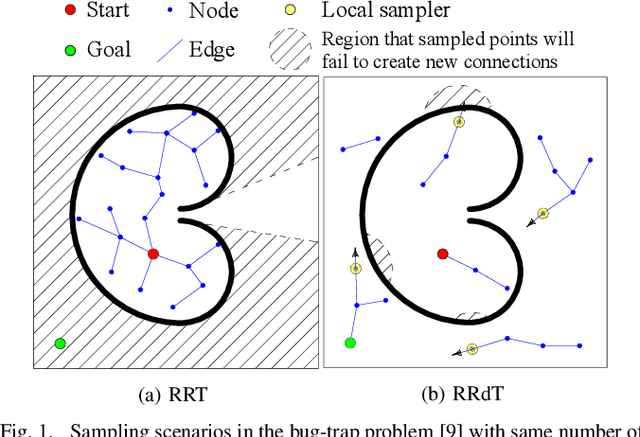
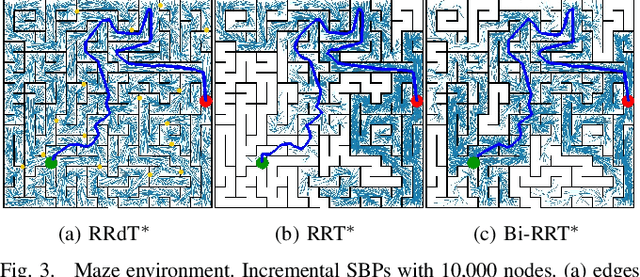
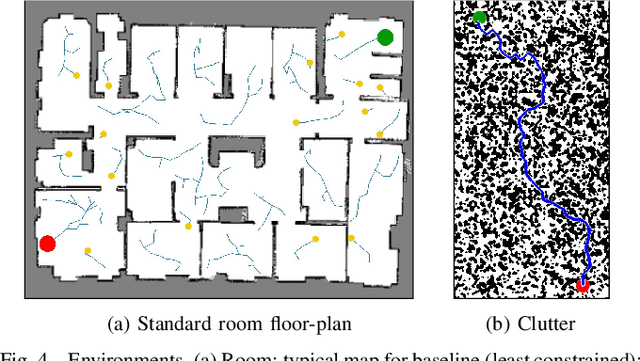
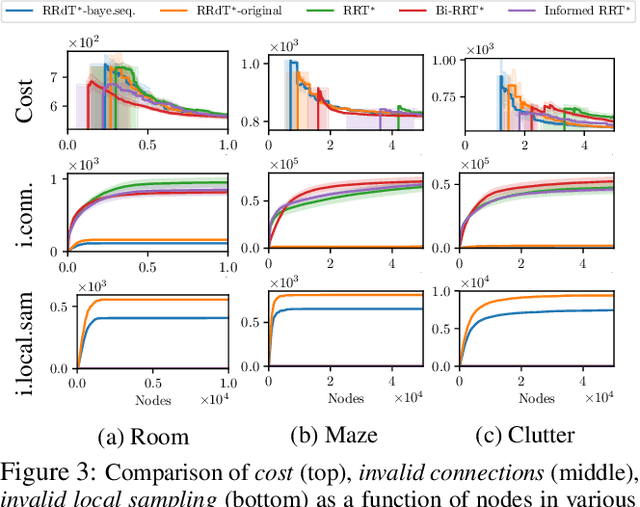
Sampling efficiency in a highly constrained environment has long been a major challenge for sampling-based planners. In this work, we propose Rapidly-exploring Random disjointed-Trees* (RRdT*), an incremental optimal multi-query planner. RRdT* uses multiple disjointed-trees to exploit local-connectivity of spaces via Markov Chain random sampling, which utilises neighbourhood information derived from previous successful and failed samples. To balance local exploitation, RRdT* actively explore unseen global spaces when local-connectivity exploitation is unsuccessful. The active trade-off between local exploitation and global exploration is formulated as a multi-armed bandit problem. We argue that the active balancing of global exploration and local exploitation is the key to improving sample efficient in sampling-based motion planners. We provide rigorous proofs of completeness and optimal convergence for this novel approach. Furthermore, we demonstrate experimentally the effectiveness of RRdT*'s locally exploring trees in granting improved visibility for planning. Consequently, RRdT* outperforms existing state-of-the-art incremental planners, especially in highly constrained environments.
Functional Path Optimisation for Exploration in Continuous Occupancy Maps
May 03, 2018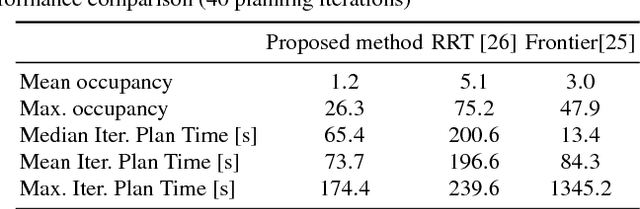
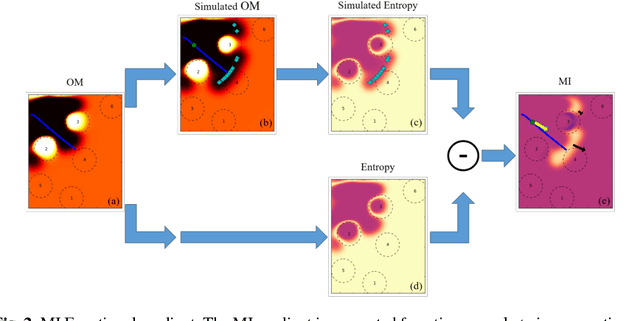
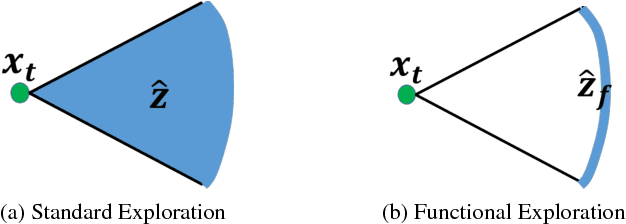
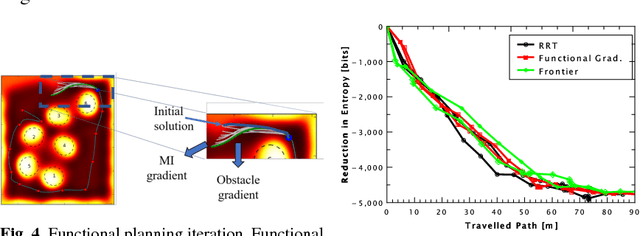
Autonomous exploration is a complex task where the robot moves through an unknown environment with the goal of mapping it. The desired output of such a process is a sequence of paths that efficiently and safely minimise the uncertainty of the resulting map. However, optimising over the entire space of possible paths is computationally intractable. Therefore, most exploration methods relax the general problem by optimising a simpler one, for example finding the single next best view. In this work, we formulate exploration as a variational problem which allows us to directly optimise in the space of trajectories using functional gradient methods, searching for the Next Best Path (NBP). We take advantage of the recently introduced Hilbert maps to devise an information-based functional that can be computed in closed-form. The resulting trajectories are continuous and maximise safety as well as mutual information. In experiments we verify the ability of the proposed method to find smooth and safe paths and compare these results with other exploration methods.
Stochastic Functional Gradient Path Planning in Occupancy Maps
May 17, 2017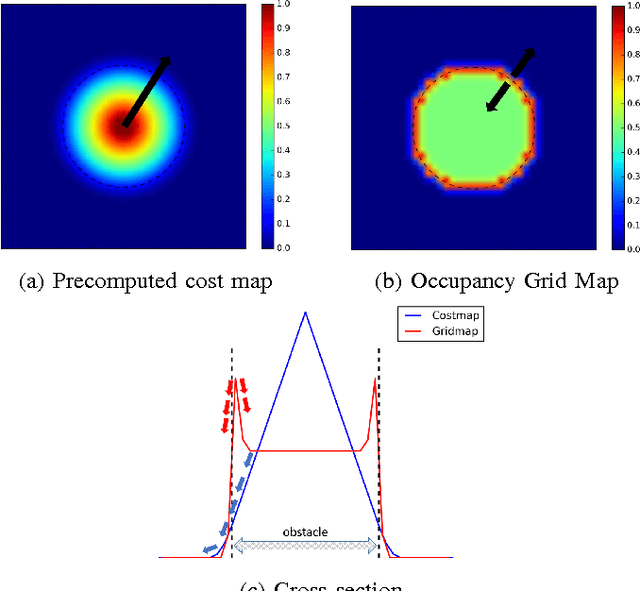
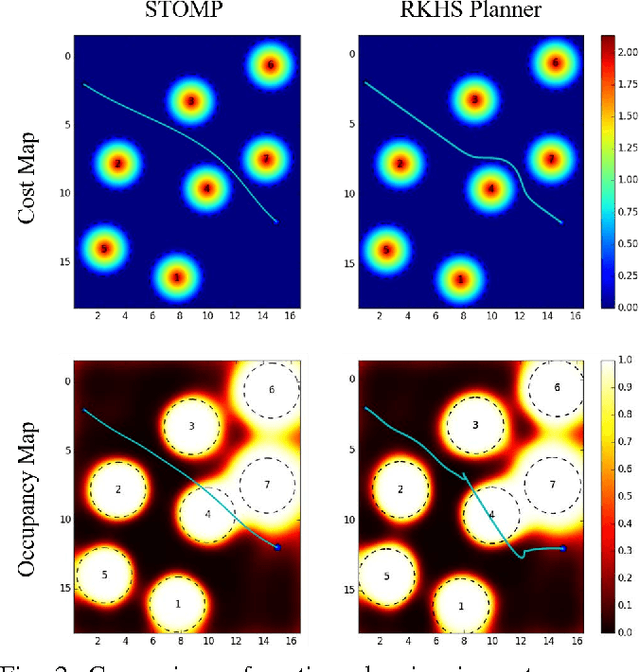

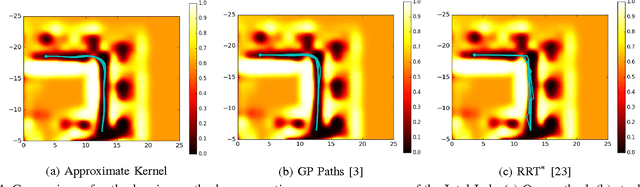
Planning safe paths is a major building block in robot autonomy. It has been an active field of research for several decades, with a plethora of planning methods. Planners can be generally categorised as either trajectory optimisers or sampling-based planners. The latter is the predominant planning paradigm for occupancy maps. Trajectory optimisation entails major algorithmic changes to tackle contextual information gaps caused by incomplete sensor coverage of the map. However, the benefits are substantial, as trajectory optimisers can reason on the trade-off between path safety and efficiency. In this work, we improve our previous work on stochastic functional gradient planners. We introduce a novel expressive path representation based on kernel approximation, that allows cost effective model updates based on stochastic samples. The main drawback of the previous stochastic functional gradient planner was the cubic cost, stemming from its non-parametric path representation. Our novel approximate kernel based model, on the other hand, has a fixed linear cost that depends solely on the number of features used to represent the path. We show that the stochasticity of the samples is crucial for the planner and present comparisons to other state-of-the-art planning methods in both simulation and with real occupancy data. The experiments demonstrate the advantages of the stochastic approximate kernel method for path planning in occupancy maps.